






 本文详细介绍了零拷贝技术的基本概念及其在Linux系统中的实现方式。通过对传统读写操作的剖析,展示了如何通过mmap、sendfile等技术手段减少不必要的数据拷贝过程,从而提高系统效率。
本文详细介绍了零拷贝技术的基本概念及其在Linux系统中的实现方式。通过对传统读写操作的剖析,展示了如何通过mmap、sendfile等技术手段减少不必要的数据拷贝过程,从而提高系统效率。
零拷贝概述
零拷贝可以避免无谓的copy动作,为了说清楚这一点,本文会先从传统的读写操作开始介绍。
传统读操作
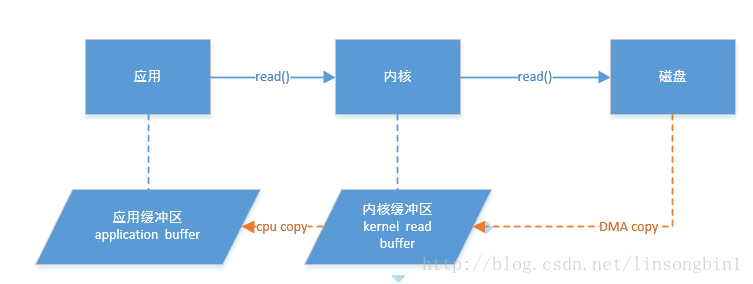
当应用发起一个从磁盘读取文件的操作时,请求会先经过内核,由内核与磁盘进行交互。数据会从磁盘拷贝到内核的缓存区中。这个copy动作由DMA完成,整个过程中基本上不消耗CPU。
DMA
硬件和软件的信息传输,可以使用DMA(direct memory access)来完成
如果应用想拿到信息,还得从内核缓冲区获取,这里又存在一个cpu copy的动作,将数据从内核缓冲区中拷贝到应用缓冲区中。这个copy动作是需要消耗CPU的。
如上文描述,要想从磁盘中读取出内容,需要2次copy动作。
传统写操作

应用想将数据传递给客户端,必须经过内核,将数据先从应用缓冲区中copy(cpu copy)到内核的缓冲区中,对于写操作而言,通常这个内核缓冲区叫
kernel socket buffer
接着DMA会从kernel socket buffer中将数据拷贝(DMA copy)到protocol engine,最终将数据发送给客户端。
这里又发生2次copy动作,一次是cpu copy,另外一次是DMA copy。
由此可见,当客户端对应用发起请求的时候,应用想将数据传递给客户端,期间需要经过4次数据拷贝动作,2次cpu copy,另外2次是DMA copy。期间应用程序相当于是一个中间者角色。
有没有办法将其中的2次cpu copy去掉呢?因为我们总是希望CPU能处理更多的事情,而不是浪费在这种无谓的copy操作当中。
答案是利用硬件以及操作系统内核,进行数据零拷贝。
使用mmap()替代read()
在此之前,为了响应客户端的请求,并把数据发送给客户端,服务端进行了两个核心操作
read()
write()
在Linux中有一个mmap操作,可以减少拷贝次数,我们将read操作换成mmap操作
mmap()
write()
换成mmap操作后,仍然需要3次copy动作。
- 第一次,DMA将数据从磁盘中拷贝(DMA copy)到kernel read buffer内核缓冲区中;
- 第二次,当应用调用write方法时,会将kernel read buffer中的数据拷贝(CPU copy)到kernel socket buffer内核缓冲区;
- 第三次,将kernel socket buffer中的数据拷贝到protocol engine(协议引擎)。
第二次为什么是cpu copy呢,因为是内存数据拷贝到另外的内存区域,必须CPU参与。
注意
在传统的读写操作中,是由应用将数据从应用缓冲区中写入到内核kernel socket buffer的。而使用mmap操作进行零拷贝时,由于不需要应用参与拷贝数据,CPU必须将数据从kernel read buffer中拷贝到kernel socket buffer。
使用sendfile()减少一次上下文切换
到此为止,已经减少了一次copy动作,但是使用
mmap()
write()
的组合还是有个缺点,就是应用调用write方法时,需求进行
应用mode到内核mode的一次切换
能不能在copy次数为3的情况下,将这次切换去掉呢?答案是使用
sendfile()
替换上面的
mmap()
write()
使用sendfile操作,copy次数还是为3,不过少了一次上下文切换。
去掉最后一个cpu copy
无论是使用
mmap()
write()
还是
sendfile()
仍然需要3次copy动作,两个是DMA copy,一个是cpu copy,能不能将这个cpu copy也去掉呢?
当然可以,需要借助DMA引擎的
gather操作
gather操作可以从多个不同的缓冲区中读取数据,DMA引擎是可以直接从kernel read buffer中读取数据的,而不用先将数据从kernel read buffer拷贝到kernel socket buffer后再进行读取操作。
到此,数据拷贝已经完全跟CPU没关系了,都是由内核操作的,内核只需要两次拷贝动作。
关于gather操作,可以参看Java NIO系列教程(四) Scatter/Gather

















 34
34

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









