






#摘要
本文提出了PDHLatin,它是一种基于列汉密尔顿拉丁方(CHIS-column hamiltonian Latin squares)构造的校验块独立的2容错水平码。通过证明它是MDS码。 本文也提出了一种新的基于CHIS的校验块独立的2容错混合编码-PIMLatin。 这两种编码具有良好的扩展性以及结构多样性。 同时本文也讨论编码缩减技术,以及它所带来的参数扩展性,结构可变性和可靠性的提升。 基于垂直缩减的思想,本文利用非汉密尔顿拉丁方的方式提出了一种2容错阵列码的构建方式。
#简介
磁盘容量的增大,以及存储系统规模的增大导致多故障频发。 因此,多容错纠删码变得流行起来,但是当前的多容错纠删码具有一些内在的局限性。Plank在Fast05上tutorial对存储系统的纠删码给出了一个详细的介绍。纠删码是一种编码容错机制。 它将
n
n
n个数据磁盘编码成
m
m
m个校验磁盘,并且可以容错任意的
t
t
t个磁盘的故障,但是并没有一种针对
n
n
n,
m
m
m,
t
t
t>
1
1
1情况下的一致公认的最优编码技术。
广为人知的多容错编码技术主要分为三种类别: Reed-Solomon码, 二进制线性码和阵列码。
- RS码是仅有的一种适用于任意 n n n, m m m(= t t t)MDS码。 这意味着最优的存储效率以及更新效率。 但是由于它使用Galois Field进行编解码运算(虽然一些优化的方法提出来),计算复杂性是一个很严重的问题。
- 二进制线性码是基于XOR的编码,具有较优的计算复杂性,但是存储效率比较低。 图1展示了一种2维线性码,其中数据单元 D i j D_{ij} Dij同时参与了两个校验块 P i P_i Pi和 Q i Q_i Qi的计算。 这个例子说明了线性码的核心观点: 将数据单元分配到多个校验组中,也就是说一个数据单元参与到多个组,保证了多容错特性。
- 阵列码将数据或者校验单元组织到一个array中。 EVENODD是第一种MDS阵列码,其他随后的一些阵列码像X-COde, RDP, STAR-code等都与它有思想上相似的地方。
#图论知识
又找了一篇相关的论文:Combinatorial Constructions of Multi-Erasure-Correcting Codes with
Independent Parity Symbols for Storage Systems 依然卡在了P1F以及拉丁方上,因此着眼于这些知识的理论搭建。
##P1F相关
所谓一个图G的因子Gi,是指至少包含G的一条边的生成子图。
所谓一个图G的因子分解,是指把图G分解为若干个边不重的因子之并。
所谓一个图G的n因子,是指图G的n度正则因子。
生成子图: 与图G的顶点相同,边是子集。
正则图: 图的所有顶点的度都相同,例如孤立的一群点是0-度正则图
n度正则因子: 首先得满足因子
G
i
G_i
Gi,然后满足正则的概念。
例如这个五边形内部的红色五角形就是图的一个2因子。
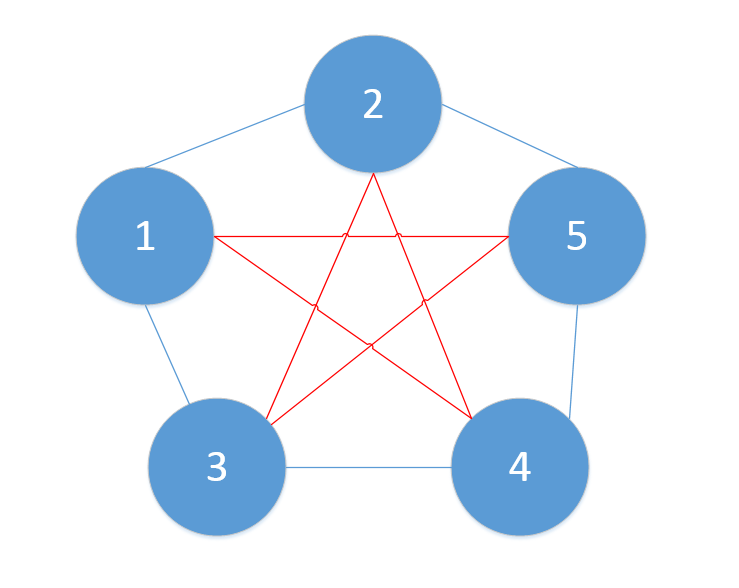
匹配: 图的一个匹配是图的一些边的集合,这些边没有公共的顶点。
最大匹配: 首先是图的一个匹配,然后边的数目最多
完美匹配: 是图的一个匹配,且能囊括所有的顶点。
例如,下图就是一个完美匹配
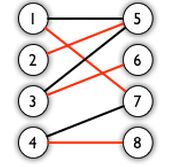
图的一因子分解:图可以分解为若干个边不重复的完美匹配的导出子图。
例如具有
2
n
2n
2n个顶点的完全图
K
2
n
K_{2n}
K2n可进行一因子分解,
K
4
K_4
K4可分解为3个1因子。
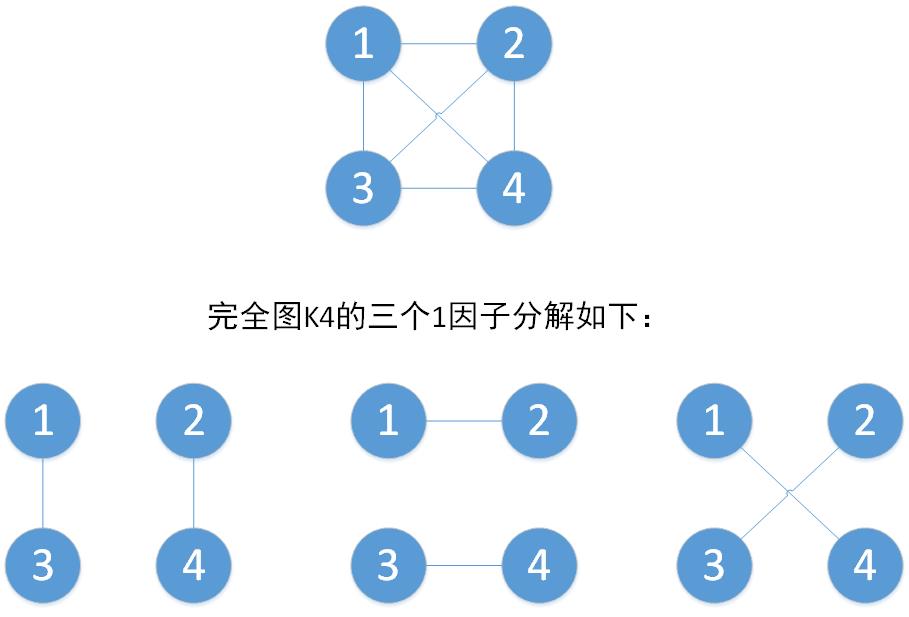
完美1因子分解: 如果一个图可以进行一因子分解,且对于任意的两个因子
F
i
F_i
Fi和
F
j
F_j
Fj,有
F
i
U
F
j
F_i U F_j
FiUFj产生了汉密尔顿回路,那么这种1因子分解就是完美1因子分解,简写为P1F。
汉密尔顿回路:
n
n
n个顶点,
n
n
n条边组成了一个环路,这样的环路只要删除其中任意一条边就不会再有回路,这种环路叫做汉密尔顿回路。 通过图G的每个结点一次,且仅一次的通路(回路)。
具有偶数个节点的完全图都有P1F。
##拉丁方相关
对于
k
≤
n
k \leq n
k≤n,一个
k
∗
n
k*n
k∗n的拉丁矩阵是1个
k
∗
n
k*n
k∗n的矩阵,而且矩阵的每一行和每一列都没有重复的元素。 通常我们使用
Z
n
=
0
,
1
,
⋯
 
,
n
−
1
Z_n = {0, 1, \cdots, n-1}
Zn=0,1,⋯,n−1作为元素集合,用
L
(
k
,
n
)
L(k,n)
L(k,n)叫做
k
∗
n
k*n
k∗n的拉丁矩阵,
L
(
k
,
n
)
L(k,n)
L(k,n)中的第
r
r
r行,第
c
c
c列的元素是
R
r
c
R_{rc}
Rrc。 我们称
L
(
n
,
n
)
L(n,n)
L(n,n)叫做拉丁方阵,且可以使用具有
n
2
n^2
n2个条目的
3
3
3元组
(
r
o
w
,
c
o
l
u
m
n
,
s
y
m
b
o
l
)
(row, column, symbol)
(row,column,symbol)来表示它。
拉丁矩阵
R
R
R的每一行都是上述
Z
n
Z_n
Zn的一个排列。如果拉丁方
L
L
L的两行组成一个单一的环,那么
L
L
L叫做行汉密尔顿拉丁方,本文关注列汉密尔顿拉丁方(CHIS),也就是两列组成一个环,如下图的
C
5
C_5
C5。
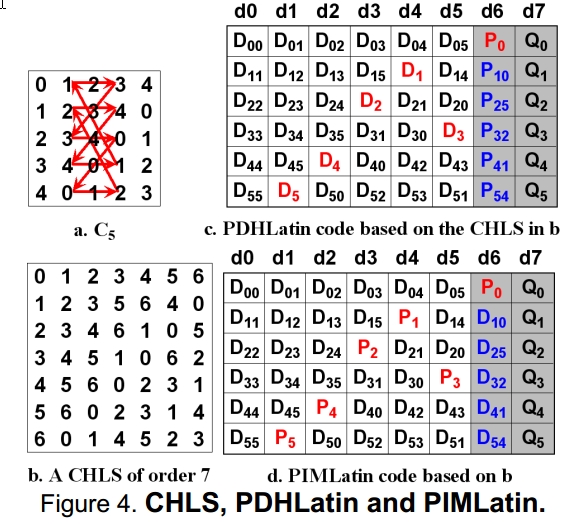
###CHIS和P1F的相互转换
CHIS和P1F具有紧密的联系。n阶CHIS可以转换为一个P1F(V, W, E),过程如下:使顶点
V
=
{
v
i
∣
0
≤
i
≤
n
−
1
}
V =\{ v_i | 0\leq i \leq n-1\}
V={vi∣0≤i≤n−1},使顶点
W
=
{
w
i
∣
0
≤
i
≤
n
−
1
}
W =\{ w_i | 0\leq i \leq n-1\}
W={wi∣0≤i≤n−1},对于所有的
(
i
,
j
,
k
)
∈
L
(i,j,k) \in L
(i,j,k)∈L, 使边$(v_i, w_k) \in F_j $, 同样这个过程也可以反向进行。
如下图的例子,P1F和CHIS一一对应:
转换过程
首先由
K
5
,
5
K_{5,5}
K5,5生成一个完美1因子匹配(即每一个子图的顶点的度都是1),每一对因子
F
i
F_i
Fi,
F
j
F_j
Fj都可以形成汉密尔顿环路。 下面的是一个5阶列汉密尔顿拉丁方。 这两个图可以相互转换(
C
5
和
K
5
,
5
C_5 和 K_{5,5}
C5和K5,5)。
将P1F中的
F
j
F_j
Fj对应于
C
5
C_5
C5的第j列;将
C
5
C_5
C5第
j
j
j列的元素的行号
i
i
i作为
F
j
F_j
Fj中V顶点的下标, 即
v
i
v_i
vi; 将
C
5
C_5
C5第
j
j
j列的元素的值
k
k
k作为
F
j
F_j
Fj中W顶点的下标, 即
w
k
w_k
wk。 举例说明: j=1,对应于
K
5
,
5
K_{5,5}
K5,5的
F
1
F_1
F1和
C
5
C_5
C5的第1列,即
1
,
2
,
3
,
4
,
0
1,2,3,4,0
1,2,3,4,0; 在
C
5
C_5
C5中,当
i
=
0
i=0
i=0时,
k
=
1
k=1
k=1(第
0
0
0行,第
1
1
1列的元素值为
1
1
1),因此在
F
1
F_1
F1中
v
0
v_0
v0与
w
1
w_1
w1相连, 同样当
i
=
1
i=1
i=1时,
k
=
2
k=2
k=2(第
1
1
1行,第
1
1
1列的元素值为
2
2
2),因此
F
1
F_1
F1中
v
1
v_1
v1与
w
2
w_2
w2相连。
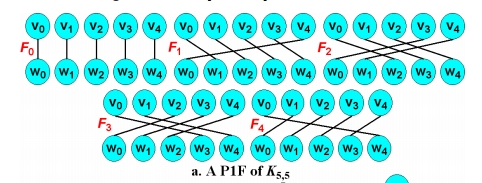
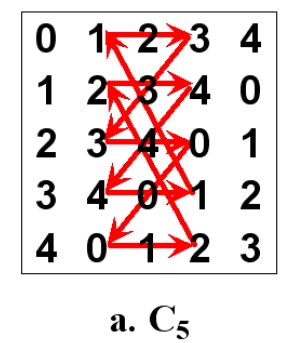
对于 C 5 C_5 C5中的第1,3列形成环路,其实就是说对于 K 5 , 5 K_{5,5} K5,5中的P1F, F 1 F_1 F1和 F 3 F_3 F3形成了环路,这两个是等价的。
如果 K n + 1 K_{n+1} Kn+1具有P1F, K n , n K_{n,n} Kn,n也具有,由于已知偶数节点的完全图具有完美1因子,因此当n为奇数(n=2也可以)时, K n , n K_{n,n} Kn,n 具有P1F。
#新的编码
#PDHLatin codes
#未完待续















 4427
4427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









