









前言
在SVM的推导中,出现了核心的一个最优化问题,这里我们简单介绍下最优化问题,特别是带有约束的最优化问题,并且引入拉格朗日乘数法和广义拉格朗日乘数法,介绍并且直观解释了KKT条件,用于解决带约束的最优化问题。本人无专业的数学学习背景,只能在直观的角度上解释这个问题,如果有数学专业的朋友,还望不吝赐教。 如有误,请联系指正。转载请注明出处。
∇ \nabla ∇ 联系方式:
e-mail: FesianXu@gmail.com
QQ: 973926198
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:

最优化问题
我们在高中,包括在高数中都会经常遇到求解一个函数的最小值,最大值之类的问题,这类问题就是属于最优化问题。比如给出下列一个不带有约束的最优化问题:
min
x
3
x
2
+
4
x
+
5
,
x
∈
R
(1.1)
\min_{x} 3x^2+4x+5, x \in R \tag{1.1}
xmin3x2+4x+5,x∈R(1.1)
其中的
3
x
2
+
4
x
+
5
3x^2+4x+5
3x2+4x+5我们称为目标函数(objective function)。这样的问题,直接利用**罗尔定理(Rolle’s theorem)**求出其鞍点,又因为其为凸函数而且可行域是整个
R
R
R,求出的鞍点便是最值点,这个是对于无约束最优化问题的解题套路。
如果问题带有约束条件,那么就变得不一样了,如:
min x , y 3 x y 2 s . t . 4 x + 5 y = 10 (1.2) \min_{x, y} 3xy^2 \\ s.t. 4x+5y = 10 \tag{1.2} x,ymin3xy2s.t. 4x+5y=10(1.2)
因为此时的约束条件是仿射函数(affine function)1,所以可以利用换元法将
x
x
x表示为
y
y
y的函数,从而将目标函数变为无约束的形式,然后利用罗尔定理便可以求出最值点了。
然而如果约束条件一般化为
g
(
x
,
y
)
=
c
g(x, y) = c
g(x,y)=c,那么
x
x
x就不一定可以用其他变量表示出来了,这个时候就要利用 拉格朗日乘数法(Lagrange multipliers ) 了。
拉格朗日乘数法(Lagrange multipliers)
我们先一般化一个二元最优化问题为
(
2.1
)
(2.1)
(2.1)形式:
min
x
,
y
f
(
x
,
y
)
s
.
t
.
g
(
x
,
y
)
=
c
(2.1)
\min_{x, y} f(x, y) \\ s.t. g(x, y) = c \tag{2.1}
x,yminf(x,y)s.t. g(x,y)=c(2.1)
将目标函数
f
(
x
,
y
)
f(x, y)
f(x,y)和等式约束条件
g
(
x
,
y
)
=
c
g(x, y)=c
g(x,y)=c画出来就如下图所示:
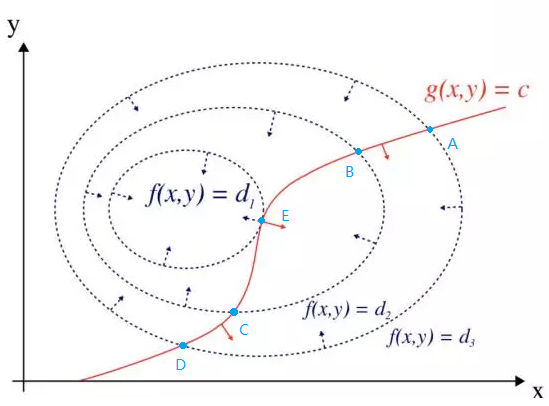
其中的 f ( x , y ) f(x, y) f(x,y)虚线为等高线,而红线为 g ( x , y ) = c g(x, y)=c g(x,y)=c这个约束函数曲线与 f ( x , y ) f(x,y) f(x,y)的交点的连线在 x − y 平 面 x-y平面 x−y平面的映射。其中,假设有 d 3 > d 2 > d 1 d_3 > d_2 > d_1 d3>d2>d1, d 1 d_1 d1点为最小值点(最优值点)。从直观上可以发现,在 g ( x , y ) = c g(x,y)=c g(x,y)=c与 f ( x , y ) f(x,y) f(x,y)的非最优化交点A,B,C,D上,其 f ( x , y ) f(x,y) f(x,y)和 g ( x , y ) g(x,y) g(x,y)的法线方向并不是共线的,注意,这个相当关键,因为如果不是共线的,说明 g ( x , y ) = c g(x,y)=c g(x,y)=c与 f ( x , y ) f(x,y) f(x,y)的交点中,还存在可以取得更小值的点存在。对于A点来说,B点就是更为小的存在。因此,我们从直觉上推论出只有当 g ( x , y ) = c g(x,y)=c g(x,y)=c与 f ( x , y ) f(x,y) f(x,y)的法线共线时,才是最小值点的候选点(鞍点)。推论到多元变量的问题的时候,法线便用梯度表示。于是,我们有原问题取得最优值的必要条件:
∇ f ( x , y ) = ∇ λ ( g ( x , y ) − c ) (2.2) \nabla f(x,y) = \nabla \lambda (g(x, y)-c) \tag{2.2} ∇f(x,y)=∇λ(g(x,y)−c)(2.2)
(
2.2
)
(2.2)
(2.2)其中的
λ
\lambda
λ表示两个梯度共线。
可以简单的变形为
∇
L
(
x
,
y
,
λ
)
=
∇
f
(
x
,
y
)
−
∇
λ
(
g
(
x
,
y
)
−
c
)
=
0
(2.3)
\nabla L(x, y, \lambda) = \nabla f(x,y) - \nabla \lambda (g(x, y)-c) = 0 \tag{2.3}
∇L(x,y,λ)=∇f(x,y)−∇λ(g(x,y)−c)=0(2.3)
让我们去掉梯度算子,得出
L
(
x
,
y
,
λ
)
=
f
(
x
,
y
)
−
λ
(
g
(
x
,
y
)
−
c
)
(2.4)
L(x, y, \lambda) = f(x, y) - \lambda(g(x, y) - c) \tag{2.4}
L(x,y,λ)=f(x,y)−λ(g(x,y)−c)(2.4)
这个时候
λ
\lambda
λ取个负号也是不影响的,所以式子
(
2.4
)
(2.4)
(2.4)通常写作:
L
(
x
,
y
,
λ
)
=
f
(
x
,
y
)
+
λ
(
g
(
x
,
y
)
−
c
)
(2.5)
L(x, y, \lambda) = f(x, y) + \lambda(g(x, y) - c) \tag{2.5}
L(x,y,λ)=f(x,y)+λ(g(x,y)−c)(2.5)
看!我们得出了我们高数中经常见到的等式约束下的拉格朗日乘数函数的表示方法。
多约束的拉格朗日乘数法
以上,我们讨论的都是单约束的拉格朗日乘数法,当存在多个等式约束时(其实不等式约束也是一样的),我们进行一些推广。先一般化一个二元多约束最小化问题:
min x , y f ( x , y ) s . t . g i ( x , y ) = 0 , i = 1 , 2 , ⋯ , N (2.6) \min_{x, y} f(x, y) \\ s.t. g_i(x, y) = 0, i = 1,2, \cdots,N \tag{2.6} x,yminf(x,y)s.t. gi(x,y)=0,i=1,2,⋯,N(2.6)
对于每个目标函数和约束配对,我们有:
L 1 ( x , y , λ 1 ) = f ( x , y ) + λ 1 g 1 ( x , y ) ⋮ L N ( x , y , λ N ) = f ( x , y ) + λ N g N ( x , y ) L_1(x ,y ,\lambda_1) = f(x,y)+\lambda_1 g_1(x,y) \\ \vdots \\ L_N(x, y, \lambda_N) = f(x,y)+\lambda_N g_N(x,y) L1(x,y,λ1)=f(x,y)+λ1g1(x,y)⋮LN(x,y,λN)=f(x,y)+λNgN(x,y)
将上式相加有:
∑
i
=
1
N
L
i
(
x
,
y
,
λ
i
)
=
N
f
(
x
,
y
)
+
∑
i
=
1
N
λ
i
g
i
(
x
,
y
)
(2.7)
\sum_{i=1}^N L_i(x,y,\lambda_i)=N f(x, y)+\sum_{i=1}^N \lambda_ig_i(x,y) \tag{2.7}
i=1∑NLi(x,y,λi)=Nf(x,y)+i=1∑Nλigi(x,y)(2.7)
定义多约束的拉格朗日函数为:
L
(
x
,
y
,
λ
)
=
f
(
x
,
y
)
+
1
N
∑
i
=
1
N
λ
i
g
i
(
x
,
y
)
(2.8)
L(x,y,\lambda) = f(x,y)+\frac{1}{N} \sum_{i=1}^N \lambda_ig_i(x,y) \tag{2.8}
L(x,y,λ)=f(x,y)+N1i=1∑Nλigi(x,y)(2.8)
因为 λ i \lambda_i λi是常数,表示共线的含义而已,所以乘上一个常数 1 N \frac{1}{N} N1也不会有任何影响,我们仍然用 λ i \lambda_i λi表示,因此式子 ( 2.8 ) (2.8) (2.8)变成:
L ( x , y , λ ) = f ( x , y ) + ∑ i = 1 N λ i g i ( x , y ) (2.9) L(x,y,\lambda) = f(x,y)+\sum_{i=1}^N \lambda_ig_i(x,y) \tag{2.9} L(x,y,λ)=f(x,y)+i=1∑Nλigi(x,y)(2.9)
这就是多约束拉格朗日乘数法的函数表达形式。
一个计算例子
让我们举一个单约束的拉格朗日乘数法的计算例子,例子来源于引用3。
给出一个最大化任务:
max
x
,
y
x
y
2
s
.
t
.
g
(
x
,
y
)
:
x
2
+
y
2
−
3
=
0
(2.10)
\max_{x,y} xy^2 \\ s.t. g(x,y):x^2+y^2-3=0 \tag{2.10}
x,ymaxxy2s.t. g(x,y):x2+y2−3=0(2.10)
图像如:
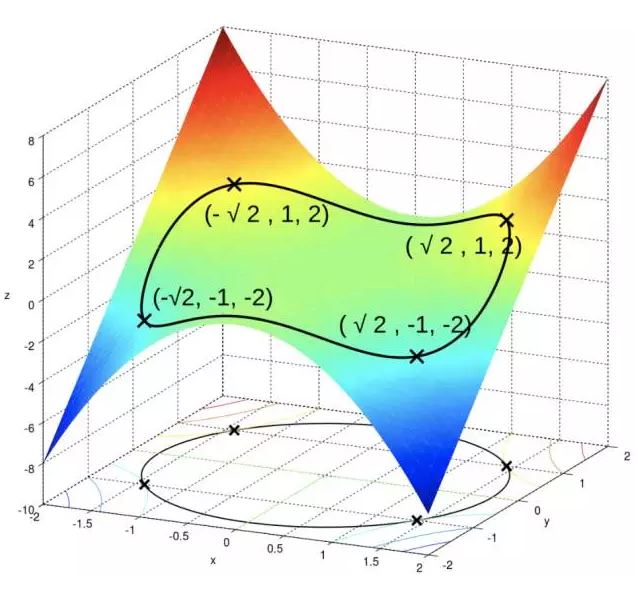
只有一个约束,使用一个乘子 λ \lambda λ,有拉格朗日函数:
L ( x , y , λ ) = x y 2 + λ ( x 2 + y 2 − 3 ) L(x,y,\lambda)=xy^2+\lambda(x^2+y^2-3) L(x,y,λ)=xy2+λ(x2+y2−3)
按照条件求解候选点:
∇
x
,
y
,
λ
L
(
x
,
y
,
λ
)
=
(
∂
L
∂
x
,
∂
L
∂
y
,
∂
L
∂
λ
)
=
(
2
x
y
+
2
λ
x
,
x
2
+
2
λ
y
,
x
2
+
y
2
−
3
)
=
0
\nabla_{x,y,\lambda} L(x,y,\lambda) = (\frac{\partial L}{\partial x}, \frac{\partial L}{\partial y}, \frac{\partial L}{\partial \lambda})=(2xy+2\lambda x, x^2+2 \lambda y, x^2+y^2-3)=0
∇x,y,λL(x,y,λ)=(∂x∂L,∂y∂L,∂λ∂L)=(2xy+2λx,x2+2λy,x2+y2−3)=0
有
x
(
y
+
λ
)
=
0
(i)
x(y+\lambda)=0 \tag{i}
x(y+λ)=0(i)
x 2 + 2 λ y = 0 (ii) x^2+2 \lambda y = 0 \tag{ii} x2+2λy=0(ii)
x 2 + y 2 = 3 (iii) x^2+y^2=3 \tag{iii} x2+y2=3(iii)
根据式子 ( i ) ( i i ) ( i i i ) (i)(ii)(iii) (i)(ii)(iii), 解得有:
( ± 2 , 1 , − 1 ) ; ( ± 2 , − 1 , 1 ) ; ( 0 , ± 3 , 0 ) (\pm \sqrt{2}, 1, -1); (\pm \sqrt{2}, -1, 1); (0, \pm \sqrt{3}, 0) (±2,1,−1);(±2,−1,1);(0,±3,0)
代入 f ( x , y ) f(x,y) f(x,y),得到:2, -2, 0,也就是我们需要求得的最大值,最小值。可以从图中看出,我们观察到其等高线与约束投影线的确是相切的。
广义拉格朗日乘数法(Generalized Lagrange multipliers)
上面我们的拉格朗日乘数法解决了等式约束的最优化问题,但是在存在不等式约束的最优化问题(包括我们SVM中需要求解的最优化问题)上,普通的拉格朗日乘数法并不能解决,因此学者提出了广义拉格朗日乘数法(Generalized Lagrange multipliers), 用于解决含有不等式约束的最优化问题。这一章,我们谈一谈广义拉格朗日乘数法。
首先,我们先一般化我们的问题,规定一个二元标准的带有不等式约束的最小化问题(当然可以推广到多元的问题),如:
min x , y f ( x , y ) s . t . g i ( x , y ) ≤ 0 , i = 1 , 2 , ⋯ , N h i ( x , y ) = 0 , i = 1 , 2 , ⋯ , M (3.1) \min_{x, y} f(x, y) \\ s.t. g_i(x, y) \leq 0, i = 1,2,\cdots,N \\ h_i(x, y) = 0, i = 1,2, \cdots, M \tag{3.1} x,yminf(x,y)s.t. gi(x,y)≤0,i=1,2,⋯,Nhi(x,y)=0,i=1,2,⋯,M(3.1)
类似于拉格朗日乘数法,参照式子 ( 2.9 ) (2.9) (2.9),我们使用 α i \alpha_i αi和 β i \beta_i βi作为等式约束和不等式约束的拉格朗日乘子,得出下式:
L ( x , y , α , β ) = f ( x , y ) + ∑ i = 1 N α i g i ( x , y ) + ∑ i = 1 M β i h i ( x , y ) (3.2) L(x, y, \alpha, \beta) = f(x, y)+\sum_{i=1}^N \alpha_ig_i(x ,y)+\sum_{i=1}^M \beta_i h_i(x, y) \tag{3.2} L(x,y,α,β)=f(x,y)+i=1∑Nαigi(x,y)+i=1∑Mβihi(x,y)(3.2)
KKT条件(Karush–Kuhn–Tucker conditions) 指出,当满足以下几个条件的时候,其解是问题最优解的候选解(摘自wikipedia)。
-
Stationarity
- 对于最小化问题就是:
∇ f ( x , y ) + ∑ i = 1 N α i ∇ g i ( x , y ) + ∑ i = 1 M β i ∇ h i ( x , y ) = 0 (3.3) \nabla f(x,y)+\sum_{i=1}^N \alpha_i \nabla g_i(x ,y)+\sum_{i=1}^M \beta_i \nabla h_i(x, y) = 0 \tag{3.3} ∇f(x,y)+i=1∑Nαi∇gi(x,y)+i=1∑Mβi∇hi(x,y)=0(3.3) - 对于最大化问题就是:
∇ f ( x , y ) − ( ∑ i = 1 N α i ∇ g i ( x , y ) + ∑ i = 1 M β i ∇ h i ( x , y ) ) = 0 (3.4) \nabla f(x,y)-(\sum_{i=1}^N \alpha_i \nabla g_i(x ,y)+\sum_{i=1}^M \beta_i \nabla h_i(x, y)) = 0 \tag{3.4} ∇f(x,y)−(i=1∑Nαi∇gi(x,y)+i=1∑Mβi∇hi(x,y))=0(3.4)
- 对于最小化问题就是:
-
Primal feasibility
- g i ( x , y ) ≤ 0 , i = 1 , 2 , ⋯ , N (3.5) g_i(x,y) \leq0, i = 1,2,\cdots,N \tag{3.5} gi(x,y)≤0,i=1,2,⋯,N(3.5)
- h i ( x , y ) = 0 , i = 1 , 2 , ⋯ , M (3.6) h_i(x, y) = 0, i = 1,2,\cdots,M \tag{3.6} hi(x,y)=0,i=1,2,⋯,M(3.6)
-
Dual feasibility
- α i ≥ 0 , i = 1 , 2 , ⋯ , N (3.7) \alpha_i \geq 0, i = 1,2, \cdots, N \tag{3.7} αi≥0,i=1,2,⋯,N(3.7)
-
Complementary slackness
- α i g i ( x , y ) = 0 , i = 1 , 2 , ⋯ , N (3.8) \alpha_i g_i(x, y) = 0, i = 1,2,\cdots,N \tag{3.8} αigi(x,y)=0,i=1,2,⋯,N(3.8)
其中的第一个条件和我们的拉格朗日乘数法的含义是相同的,就是梯度共线的意思;而第二个条件就是主要约束条件,自然是需要满足的;有趣的和值得注意的是第三个和第四个条件,接下来我们探讨下这两个条件,以及为什么不等式约束会多出这两个条件。
为了接下来的讨论方便,我们将N设为3,并且去掉等式约束,这样我们的最小化问题的广义拉格朗日函数就变成了:
L ( x , y , α , β ) = f ( x , y ) + ∑ i = 1 3 α i g i ( x , y ) (3.9) L(x, y, \alpha, \beta) = f(x, y)+\sum_{i=1}^3 \alpha_ig_i(x ,y) \tag{3.9} L(x,y,α,β)=f(x,y)+i=1∑3αigi(x,y)(3.9)
绘制出来的示意图如下所示:
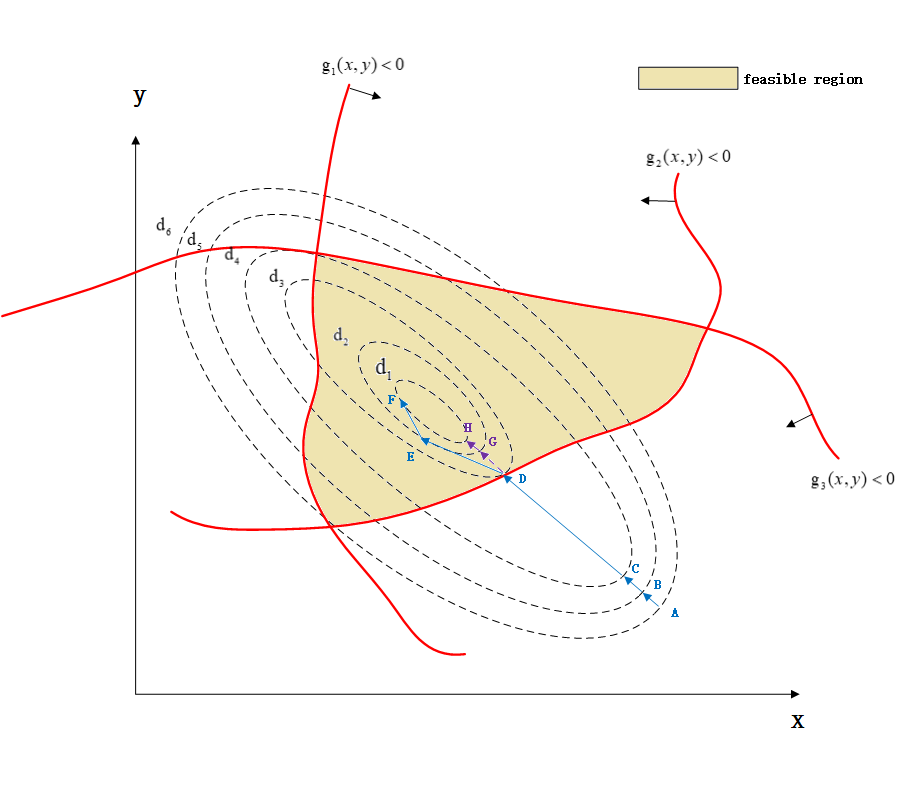
其中 d i > d j , w h e n i > j d_i > d_j, when i > j di>dj,when i>j,而蓝线为最优化寻路过程。
让我们仔细观察式子 ( 3.7 ) (3.7) (3.7)和 ( 3.8 ) (3.8) (3.8),我们不难发现,因为 α i ≥ 0 \alpha_i \geq 0 αi≥0而 g i ( x , y ) ≤ 0 g_i(x, y) \leq 0 gi(x,y)≤0,并且需要满足 α i g i ( x , y ) = 0 \alpha_i g_i(x, y) = 0 αigi(x,y)=0,所以 α i \alpha_i αi和 g i ( x , y ) g_i(x,y) gi(x,y)之中必有一个为0,那为什么会这样呢?
我们从上面的示意图入手理解并且记好公式 ( 3.3 ) (3.3) (3.3)。让我们假设初始化一个点A, 这个点A明显不处于最优点,也不在可行域内,可知 g 2 ( x , y ) > 0 g_2(x,y)>0 g2(x,y)>0违背了 ( 3.5 ) (3.5) (3.5),为了满足约束 ( 3.8 ) (3.8) (3.8),有 α 2 = 0 \alpha_2=0 α2=0,导致 α 2 ∇ g 2 ( x , y ) = 0 \alpha_2 \nabla g_2(x,y)=0 α2∇g2(x,y)=0,而对于 i = 1 , 3 i=1,3 i=1,3,因为满足约束条件而且 g 1 ( x , y ) ≠ 0 , g 3 ( x , y ) ≠ 0 g_1(x,y) \neq 0, g_3(x,y) \neq 0 g1(x,y)=0,g3(x,y)=0,所以 α 1 = 0 , α 3 = 0 \alpha_1 = 0, \alpha_3 = 0 α1=0,α3=0。这样我们的式子 ( 3.3 ) (3.3) (3.3)就只剩下 ∇ f ( x , y ) \nabla f(x,y) ∇f(x,y),因此对着 ∇ f ( x , y ) \nabla f(x,y) ∇f(x,y)进行优化,也就是沿着 f ( x , y ) f(x,y) f(x,y)梯度方向下降即可,不需考虑其他的条件(因为还完全处于可行域之外)。因此,A点一直走啊走,从A到B,从B到C,从C到D,这个时候因为D点满足 g 2 ( x , y ) = 0 g_2(x,y)=0 g2(x,y)=0,因此 α 2 > 0 \alpha_2 > 0 α2>0,所以 α 2 ∇ g 2 ( x , y ) ≠ 0 \alpha_2\nabla g_2(x,y) \neq 0 α2∇g2(x,y)=0,因此 ( 3.3 ) (3.3) (3.3)就变成了 ∇ f ( x , y ) + α 2 ∇ g 2 ( x , y ) \nabla f(x,y)+\alpha_2\nabla g_2(x,y) ∇f(x,y)+α2∇g2(x,y)所以在优化下一个点E的时候,就会考虑到需要满足约束 g 2 ( x , y ) ≤ 0 g_2(x,y) \leq 0 g2(x,y)≤0的条件,朝着向 g 2 ( x , y ) g_2(x,y) g2(x,y)减小,而且 f ( x , y ) f(x,y) f(x,y)减小的方向优化。因此下一个优化点就变成了E点,而不是G点。因此没有约束的情况下其优化路径可能是 A → B → C → D → G → H A \rightarrow B \rightarrow C \rightarrow D \rightarrow G \rightarrow H A→B→C→D→G→H,而添加了约束之后,其路径变成了 A → B → C → D → E → F A \rightarrow B \rightarrow C \rightarrow D \rightarrow E \rightarrow F A→B→C→D→E→F。
这就是为什么KKT条件引入了条件3和条件4,就是为了在满足不等式约束的情况下对目标函数进行优化。让我们记住这个条件,因为这个条件中某些 α i = 0 \alpha_i=0 αi=0的特殊性质,将会在SVM中广泛使用,而且正是这个性质定义了支持向量(SV)。
Q & A
这里回答下知乎的朋友的一些问题,链接为:《SVM笔记系列之三》拉格朗日乘数法和KKT条件的直观解释。主要有两个问题。
-
战胜: 最开始分析你说g1,g3都非零,所以α1=0,α3=0;照你这么分析的话,后面的3个不等式项都是零呀,都是无约束了!
A:因为在A,B,C点时处在可行域之外,因此所有的 α i \alpha_i αi都为0,这个保证了在可行域之外会按照 ∇ f ( x , y ) \nabla f(x,y) ∇f(x,y)的梯度方向进行优化,而不需要考虑其他约束。这就退化到了一般的无约束优化了。这个也是可以理解的,毕竟在可行域之外为什么需要考虑约束的作用呢?
-
安梦徒生: 看不懂为什么往E的方向
A: 在D这个点刚好到可行域的边界,因此按照上面的分析,梯度方向应该是 ∇ f ( x , y ) + α 2 ∇ g 2 ( x , y ) \nabla f(x,y)+\alpha_2\nabla g_2(x,y) ∇f(x,y)+α2∇g2(x,y),因此应该是 f ( x , y ) f(x,y) f(x,y)和 g 2 ( x , y ) g_2(x,y) g2(x,y)梯度方向的合成,而不单是某个约束函数的梯度方向。我这里假设他的合成梯度方向到达的点是E点作为示例而已。
引用
- 拉格朗日乘子法如何理解? 知乎
- 《统计学习方法》 豆瓣
- 《【直观详解】拉格朗日乘法和KKT条件》 微信公众号
- 《解密SVM系列(一):关于拉格朗日乘子法和KKT条件》 CSDN
- Karush–Kuhn–Tucker conditions wikipedia
最高次数为1的多项式,形如 f ( x ) = A X + B f(x) = AX+B f(x)=AX+B,其中 X X X是 m × k m \times k m×k的仿射矩阵,其与线性函数的区别就是,线性函数是 f ( x ) = A X f(x) = AX f(x)=AX没有偏置项 B B B。 ↩︎


















 4247
4247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











