









Caffe是深度学习的一种框架,由C++和Python编写,底层是C++源码。
一、Caffe-master源代码大框架:
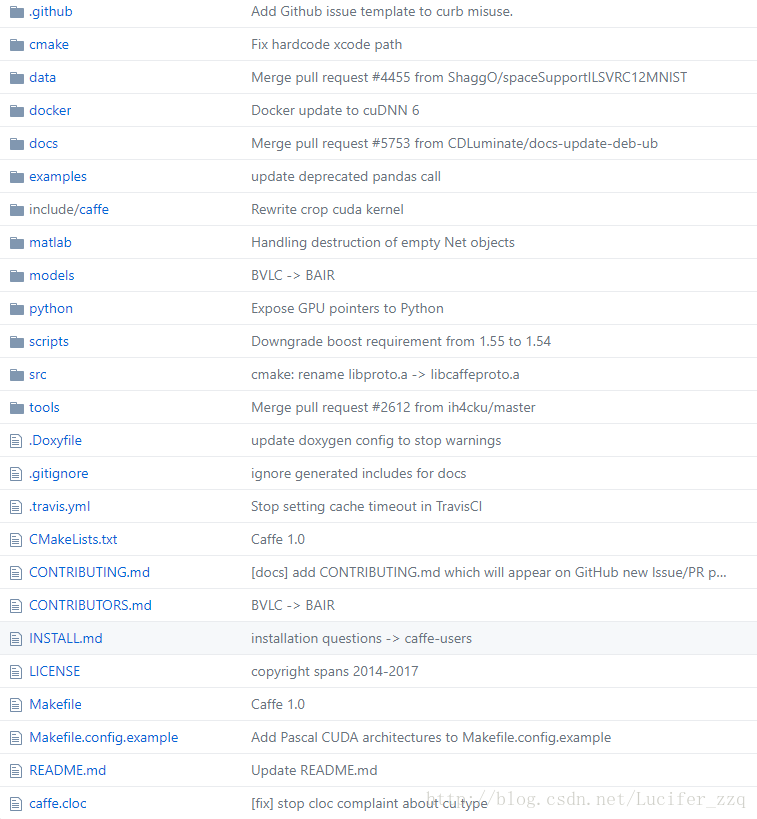
关键文件如下:
- data:用于存放caffe-master中程序所需要的原始数据(图片等)
- docs:用于存放帮助文档
- examples:用于存放代码
- include/caffe:用于存放头文件.hpp(非常重要!!)
- matlab:用于存放Matlab接口文件
- python:用于存放Python接口文件
- scripts:用于存放在跑程序的时候会用到的脚本文件(shell、sh)
- src:用于存放Caffe源码.cpp/.cu(非常重要!!)
- tools:用于存放一些二进制文件,用于调用一些可直接运行的的帮助程序
上述4&8中最重要的核心代码为:
- layers:各类层定义的.cpp/.cu/.hpp文件(后续会详细讲解如何新定义一个层结构)
- solvers:各类优化方法SGD、Adam等(后续会详细分析优化实现具体过程)
- test:测试Caffe的代码
proto:protobuf
二、 Caffe的四大组成:
1、Blob:表示网络中的数据头文件:存放在caffe/include/caffe/blob.hpp
其中定义protected数据成员:
protected:
shared_ptr<SyncedMemory> data_;
shared_ptr<SyncedMemory> diff_;
shared_ptr<SyncedMemory> shape_data_;
vector<int> shape_;
int count_;
int capacity_;其中定义Blob数据(data&diff)访问方法:
const Dtype* cpu_data() const;
const int* gpu_shape() const;
const Dtype* cpu_diff() const;
const Dtype* gpu_diff() const;
Dtype* mutable_cpu_data();
Dtype* mutable_gpu_data();
Dtype* mutable_cpu_diff();
Dtype* mutable_gpu_diff();- 源代码:存放在caffe/src/caffe/blob.cpp,其主要成员函数主要有:
void Blob<Dtype>::Reshape(...)
void Blob<Dtype>::ReshapeLike(const Blob<Dtype>& other)
void Blob<Dtype>::Update() //更新权值的函数:data_=data_-diff_
void Blob<Dtype>::ShareData(const Blob& other)
void Blob<Dtype>::ShareDiff(const Blob& other)2、Net:连接layers,整个网络的表示
3、Layer:对神经网络中各个层的抽象(后续会详细讲解定义一个新的层)
4、Solver:定义了神经网络模型的求解方法(默认SGD,后续会讲解Solver是如何完成权值更新)
- caffe/src/caffe/solver.cpp
在Solver类的成员函数solve()中实际调用Solver的另一个成员函数Step():
void Solver<Dtype>::Solve(const char* resume_file) {
CHECK(Caffe::root_solver());
...
Step(param_.max_iter() - iter_);
...
}Step():
template <typename Dtype>
void Solver<Dtype>::Step(int iters) {
const int start_iter = iter_;
const int stop_iter = iter_ + iters;
int average_loss = this->param_.average_loss();
losses_.clear();
smoothed_loss_ = 0;
iteration_timer_.Start();
...
//accumulate the loss and gradient
Dtype loss = 0;
for (int i = 0; i < param_.iter_size(); ++i) {
loss += net_->ForwardBackward(); //Net类中的Forward()函数,用于传递loss
}
loss /= param_.iter_size();
// average the loss across iterations for smoothed reporting
UpdateSmoothedLoss(loss, start_iter, average_loss); //求平均让loss变得更平滑
...
ApplyUpdate();//重要!!Solver类的一个纯虚函数,需要派生类来实现,所以在不同的具体**_solver.cpp中对此进行详细定义那么以SGD为例来看ApplyUpdate():
- caffe/include/caffe/solvers/sgd_solver.hpp
- caffe/src/caffe/solvers/sgd_solver.cpp(caffe/src/caffe/solvers/sgd_solver.cpp)
template <typename Dtype>
void SGDSolver<Dtype>::ApplyUpdate() {
Dtype rate = GetLearningRate();//得到当前迭代的learning_rate的值
if (this->param_.display() && this->iter_ % this->param_.display() == 0) {
LOG_IF(INFO, Caffe::root_solver()) << "Iteration " << this->iter_
<< ", lr = " << rate;
}
ClipGradients();//避免梯度爆炸所做的梯度裁剪
//对网络中所有需要更新的参数进行操作:
for (int param_id = 0; param_id < this->net_->learnable_params().size();
++param_id) {
Normalize(param_id);//正规化:related to the issue of feature scaling
Regularize(param_id);//正则化:to avoid overfitting when training machine learning algorithm
ComputeUpdateValue(param_id, rate);//计算新的权值更新梯度diff_
}
this->net_->Update();//完成更新操作:data_=data_-diff_
}其中:GetLearningRate()、ClipGradients()、Normalize()、Regularize()在此.cpp文件中均有定义,感兴趣的读者可以自行阅读。














 495
495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









