







 本文介绍了无监督学习中的K均值聚类算法和二分K均值聚类算法。K均值通过迭代更新质心和样本所属类别,但在初始化质心选取不佳时可能陷入局部最优。二分K均值通过选择能最小化误差平方和的簇进行二分,避免了局部最优问题。两种方法的共同挑战是需要预先设定类别数量K。
本文介绍了无监督学习中的K均值聚类算法和二分K均值聚类算法。K均值通过迭代更新质心和样本所属类别,但在初始化质心选取不佳时可能陷入局部最优。二分K均值通过选择能最小化误差平方和的簇进行二分,避免了局部最优问题。两种方法的共同挑战是需要预先设定类别数量K。
接下来就要说下无监督机器学习方法,所谓无监督机器学习前面也说过,就是没有标签的情况,对样本数据进行聚类分析、关联性分析等。主要包括K均值聚类(K-means clustering)和关联分析,这两大类都可以说的很简单也可以说的很复杂,学术的东西本身就一直在更新着。比如K均值聚类可以扩展一下形成层次聚类(Hierarchical Clustering),也可以进入概率分布的空间进行聚类,就像前段时间很火的LDA聚类,虽然最近深度玻尔兹曼机(DBM)打败了它,但它也是自然语言处理领域(NLP:Natural Language Processing)的一个有力工具,有过辉煌的一段故事。而关联性分析又是另外一个比较有力的工具,它又称购物篮分析,我们可以大概可以体会到它的用途,挖掘目标之间的关联性,经典的故事就是啤酒和尿布的关联。另外多说一下,google最近的两大核心技术:深度学习和知识图,深度学习就不说了,而知识图就是挖掘关系的。找到了关系就找到了金矿,关系也可以用复杂网络(complex network)来建模。这些话题就打住吧,今天就来说下K均值聚类和二分K均值聚类。
K均值聚类比较简单,再说原理之前,先来看个样本图,如(图一)所示:
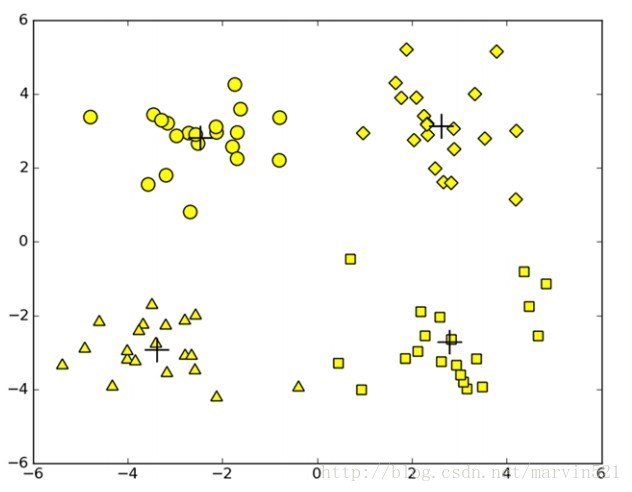
(图一)
假如(图一)中是我们的样本数据,每个样本都没有类别,我们想对他们简单的划下类,在(图一)中明显的有四“堆”数据,我们用什么方法能把他们分成四类呢?K均值聚类就是解决这种问题的(好腻 = =!),K均值聚类的原理如下:
随机的分配K个质心(上图中K为4)
如果样本中任意一个数据点归属的簇号(堆类别)发生改变
遍历每一个样本点
遍历每一个质心
计算数据点到质心的距离
把数据点分配到距其最近的簇
对每一个簇,重新计算簇中所有样本点的均值作为质心
K均值简单的一句话总结就是:更新质心,更新每个样本的所属的类别。按照上述更新规则&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1081
1081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









