







Gradient Descent Variants
reference: http://sebastianruder.com/optimizing-gradient-descent/
(1)Batch gradient descent: 计算整个数据集上, Cost function 对于parameters的偏导,而后更新梯度;对于convex error surfaces可以得到global minimum,而对于non-convex error surfaces能得到local minimum
(2) Stochastic gradient descent: 计算单个sample上,Cost function对于parameters的偏导,而后更新梯度;相较于BGD,SGD更容易从一个local minimum跳到另一个local minimum(但是当learning rate过小时,performance便和BGD相似);High variance,更容易使得loss curve产生震荡
(3)Mini-batch gradient descent: 计算whole dataset某个子集(通常设置为50-256)对于paremeters的偏导,而后更新梯度;比SGD更稳定,更易收敛;能够使用高效的矩阵化trick,使得在runing的时候更加efficient
(4)面临几大问题:
1.Learning rate很难选择,太小了收敛很慢,太大了容易在local minimum周围晃动,甚至发散
2.在训练时当loss一直在某个范围摆动时,这时候应该减小learning rate,但是这个trick受数据集属性或者模型的capacity等因素的影响较大,需要认为的精调
3.所用的参数更新都是基于同一个learning rate的,但是当数据集很稀疏,或者features出现的频率有很大不同,这时候我们会希望用较大的learning rate来更新rarely出现的feature,即希望实现feature-wise的learning rate的调整
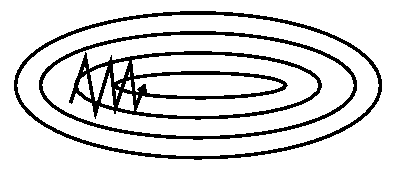
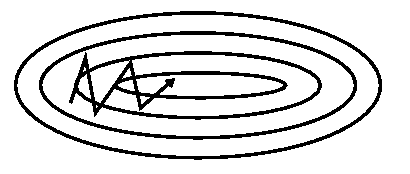
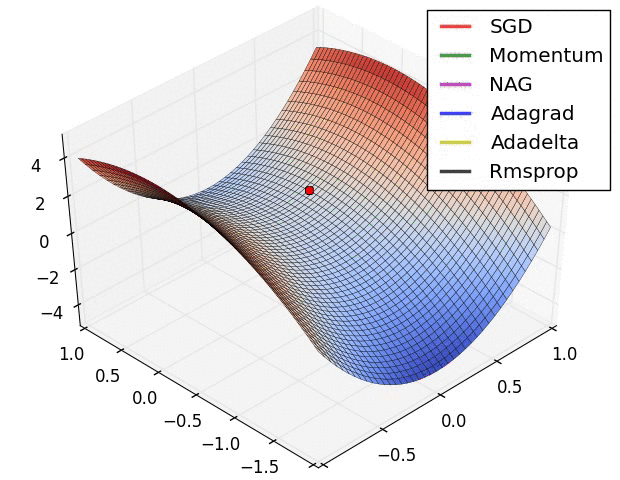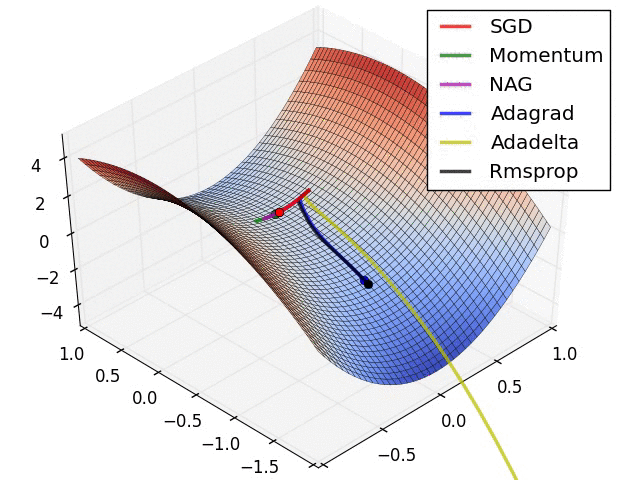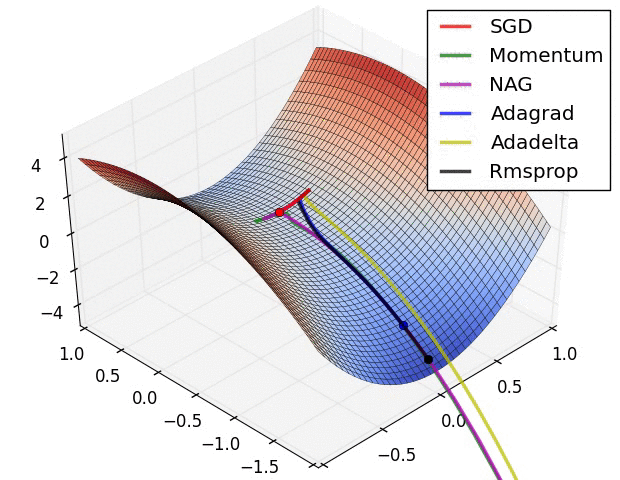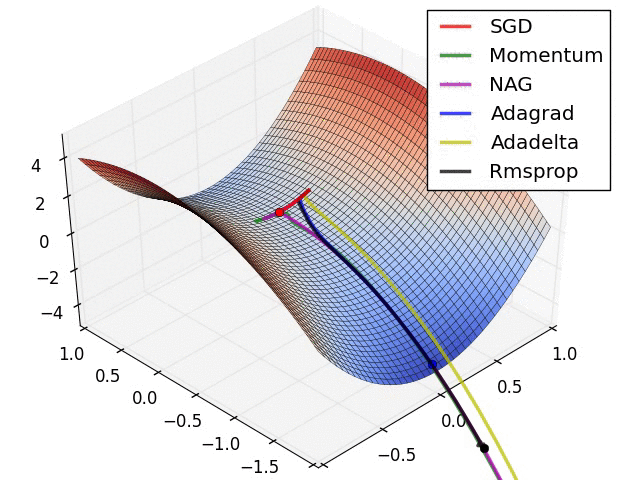
4.还有一个问题时saddle points 的问题,如下图:
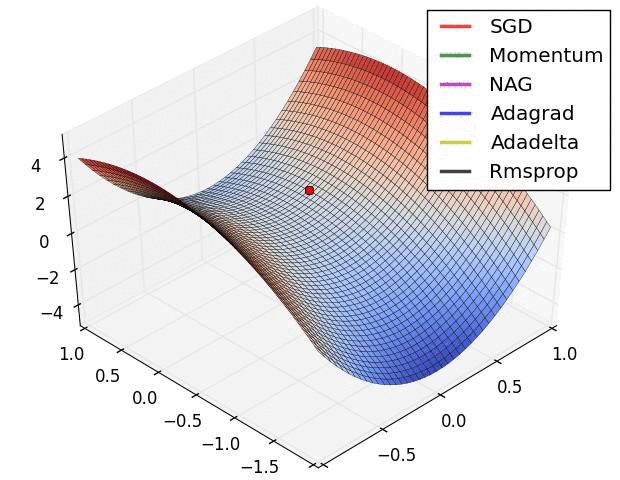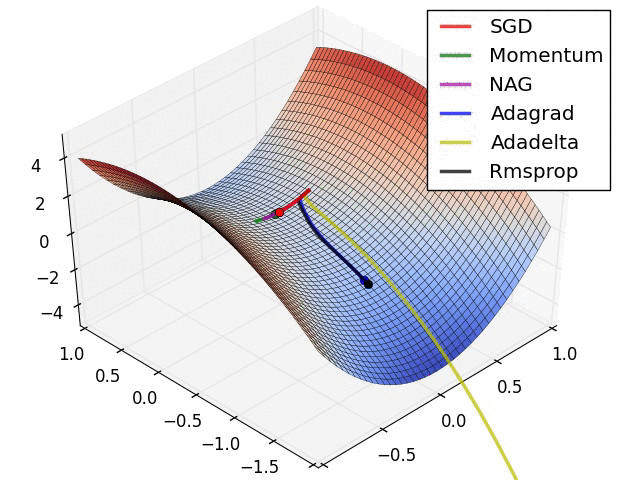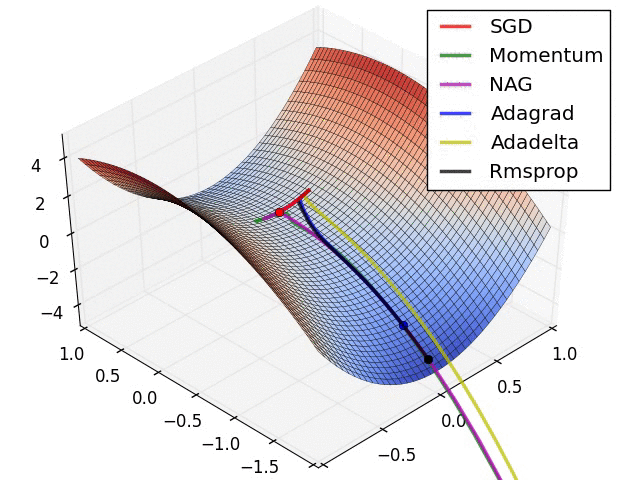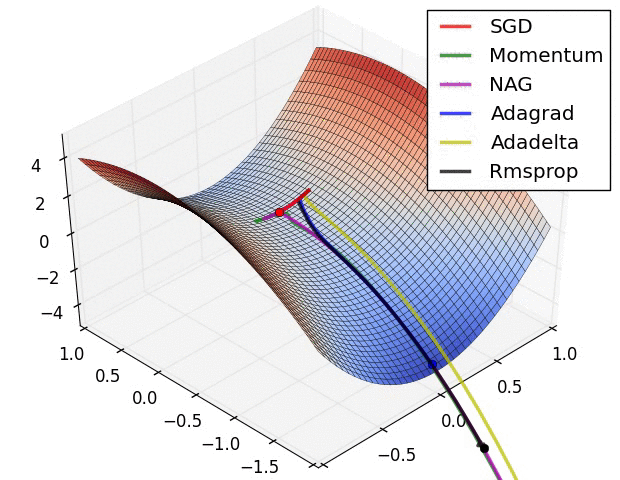
下文在SGD指的是Mini-batch gradient descent,其实在其他很多地方也是这样
Gradient descent optimization algorithms
Newton’s method.对于高维问题infeasible,所以下面不讨论
(1)Momentum: 当遇到沟壑问题(一个方向的坡度比其他方向明显要陡峭,大多数情况下都会对应到一个local minimum)时,SGD不会沿着沟壑加速下降到local minimum,而Momentum的想法则是将上一次更新时的梯度乘以一个因数 γ (一般设置为0.9),然后加上此时的梯度,若两个梯度的方向类似,则会加速在这一方向上的移动,即加速了收敛:
vt=γvt−1+η∇θJ(θ)
θ=θ−vt
(2)Nesterov accelerated gradient: Momentum的一个问题是盲目,即不判断下一步将要下降到哪,就一直加速下降,所以在坡度开始由下降转为上升时,可能会越过local minimum;Nesterov有效的解决了这个问题,大概意思就是先大概预测下一步要下降到的位置(通过计算 J(θ−γvt−1) 的梯度判断),而后再做出修正,Nesterov在很多RNN的tasks中都很有效:
vt=γvt−1+η∇θJ(θ−γvt−1)
θ=θ−vt
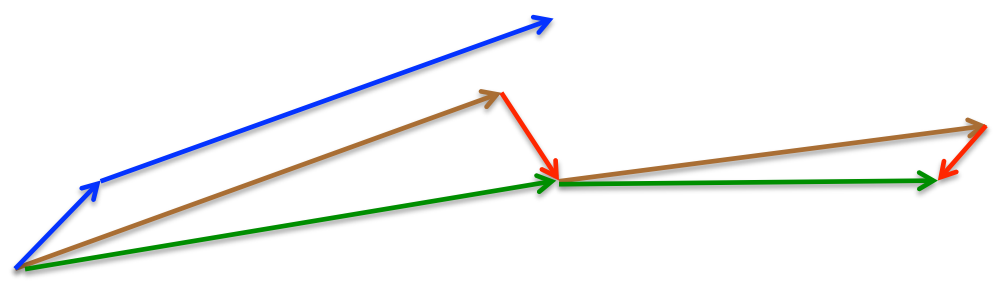
蓝色箭头是Momentum:首先计算当前梯度(短箭头),然后再加上上一步的梯度(长箭头);棕色箭头是
J(θ−γvt−1)
的梯度,即预判,然后再做出修正(绿色箭头)
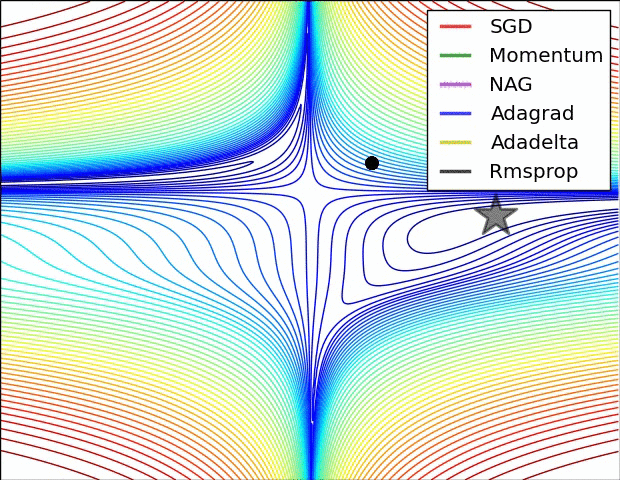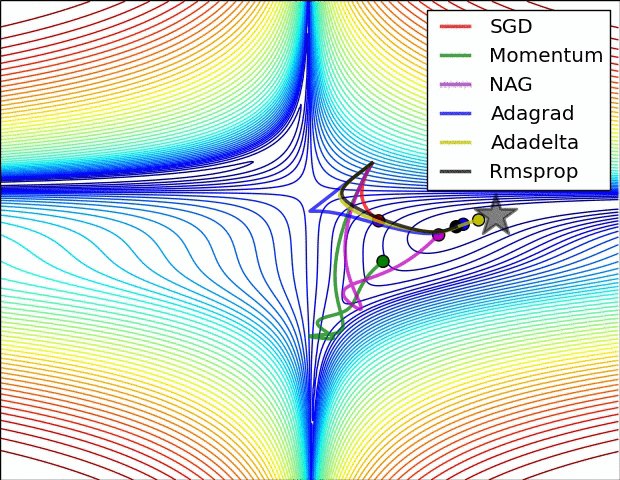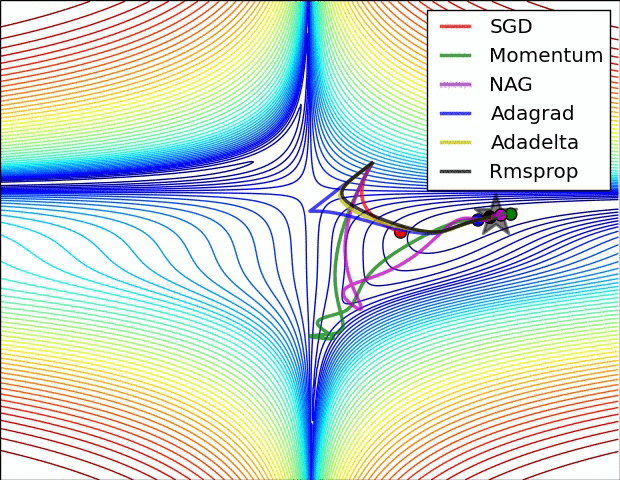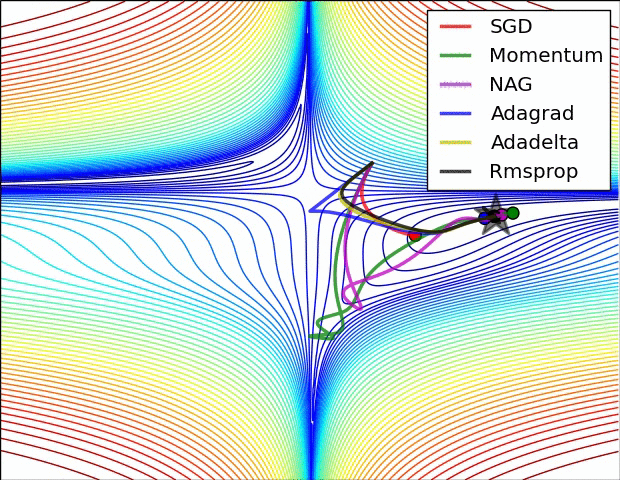















 1118
1118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









