







http://blog.csdn.net/pipisorry/article/details/42560877
* 概率潜在语义分析简称pLSA(Probabilisticlatent semantic analysis)
* 概率潜在语义分析与标准潜在语义分析的不同是,标准潜在语义分析是以共现表(就是共现的矩阵)的奇异值分解的形式表现的,而概率潜在语义分析却是基于派生自LCM的混合矩阵分解。考虑到word和doc共现形式,概率潜在语义分析基于多项式分布和条件分布的混合来建模共现的概率。所谓共现其实就是W和D的一个矩阵,所谓双模式就是在W和D上同时进行考虑。基于概率统计的PLSA模型,用EM算法学习模型参数。
PLSA的推导
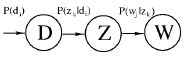
- D是文档;Z代表主题;W代表观察到的单词
- p(di) 是单词出现的在文档 di 的概率
- p(zk|di) 是文档 di 中出现主题 zk 的概率
-
p(wj|zk)
是给定主题词
zk
出现单词
wj
的概率
(每个主题在所有词项上服从Multinomial分布,每个文档在所有文档上服从Multinomial分布) - 文档的生成过程:
- 以 p(di) 的概率选择文档 di
- 以 p(zk|di) 的概率选择主题
- 以 p(wj|zk) 的概率产生一个单词
观察到的数据是: (dj,wj)
p(di,wj)=p(di)d(wj|di)
p(wj|di)=∑Kk=1p(wj|zk)p(zk|di)
其中: p(zk|di)和p(wj|zk) 分别对应了两组Multinomial分布,需要去估计参数
PLSA的EM算法估计参数
- 需要去估计的参数是: p(zk|di),p(wj|zk)
直接使用MLE估算参数
L=∏Ni=1∏Mj=1p(di,wj)
=∏i∏jp(di,wj)n(di,wj)
……..
(n(di,wj))
是单词
wj
出现在文档
di
的次数
l=∑Ni=1∑Mj=1n(di,wj)logp(di,wj)
=∑i∑jn(di,wj)logp(di,wj)
=∑i∑jn(di,wj)logp(wj|di)p(di)
=∑i∑jn(di,wj)log(∑Kk=1p(wj|zk)p(zk|dj)p(di))
上式是关于 p(zk|di)和p(wj|zk) 的函数;对于上述包括隐变量或者是缺失数据的公式采用EM算法
EM算法求解步骤
PLSA中,incomplete data是观察到的 (di,wj) ,隐含主题是 zk ,完整的数据是 (dj,wj,zk)
(1)E步骤:求含隐变量Givern当前估计的参数条件下的后验概率。
(2)M步骤:最大化Complete data对数似然函数的期望,此时使用E步骤计算隐含变量的后验概率,得到新的参数
两部迭代直到收敛
- E步骤:假设 p(zk|dj),p(wj|zk) 已知,初始化时随机赋值
p(zk|di,wj)=p(wj|zk)p(zk|di)∑kl=1p(wj|zl)p(zl|di)
- M步骤:最大化 Complete data对数似然函数的期望
l=∑i∑jn(di,wj)
=∑i∑jn(di,wj)log(p(wj|di)p(di))
=∑i∑jn(di,wj)(logp(wj|di)+logp(di))
=(∑i∑jn(di,wj)logp(wj|di))+(∑i∑jn(di,w+j)logp(di))
=>
lnew=(∑i∑jn(di,wj)logp(wj|di))
E(lnew=∑i∑jn(di,wj)∑Kk=1p(zk|di,wj)logp(wj,zk|di)
=∑i∑jn(di,wj)∑Kk=1p(zk|di,wj)logp(wj,zk)p(zk,di)
目标函数的建立
关于参数
p(zk|di),p(wj|zk)
的函数E,且其约束:
∑Mj=1p(wj|zk)=1
∑Kk=1p(zk|di)=1
E=∑i∑jn(di,wj)∑Kk=1p(zk|di,wj)logp(wj,zk)p(zk,di)
转换为:求等式约束的极值。
结论
M步:
p(wj|zk)=∑in(di,wj)p(zk|di,wj)∑Mm=1n(di,wj)p(zk|di,wj)
p(zk|di)=∑jn(di,wj)p(zk|di,wj)∑Kk=1∑jn(di,wj)p(zk|di,wj)
E步骤:
p(zk|di,wj)=p(wj|zk)p(zk|di)∑Kl=1p(wj|zl)p(zl|di)















 863
863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









