







pLSA 模型是有向图模型,将主题作为隐变量,构建了一个简单的贝叶斯网,采用EM算法估计模型参数。
由于PLSA属于LSA到LDA的过滤,很少被使用~~ 可以减少研究!
什么是PLSA
概率潜在语义分析简称pLSA(Probabilisticlatent semantic analysis)基于双模式和共现的数据分析方法延伸的经典的统计学方法。概率潜在语义分析应用于信息检索,过滤,自然语言处理,文本的机器学习或者其他相关领域。
PLSA与LSA不同
概率潜在语义分析与标准潜在语义分析的不同是,标准潜在语义分析是以共现表(就是共现的矩阵)的奇异值分解的形式表现的,而概率潜在语义分析却是基于派生自LCM的混合矩阵分解。考虑到word和doc共现形式,概率潜在语义分析基于多项式分布和条件分布的混合来建模共现的概率。所谓共现其实就是W和D的一个矩阵,所谓双模式就是在W和D上同时进行考虑。基于概率统计的PLSA模型,用EM算法学习模型参数。
变量
观测变量为文档 𝑑𝑚∈𝔻(文档集共 M 篇文档)、
词 𝑤𝑛∈𝕎(设词汇表共有 V 个互不相同的词),
隐变量为主题 𝑧𝑘∈ℤ(共 K 个主题)。
在给定文档集后,我们可以得到一个词-文档共现矩阵,每个元素 𝑛(𝑑𝑚,𝑤𝑛) 表示的是词 𝑤𝑛 在文档 𝑑𝑚 中的词频。
也就是说,PLSA 模型也是基于词-文档共现矩阵的,不考虑词序。
每个主题在所有词项上服从Multinomial 分布,每个文档在所有主题上服从Multinomial 分布。
我们可以观察到的数据就是(dm, wn)对,而Zk是隐含变量。
(dm, wn)的联合分布为
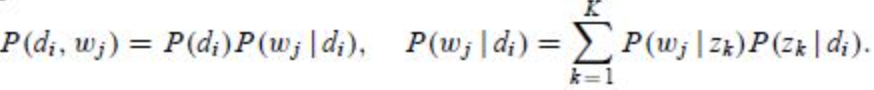
P(dm, zk)和P(zk, wn)分布对应了两组Multinomial 分布,我们需要估计这两组分布的参数。
使用PLSA生成文档
pLSA 模型通过以下过程来生成文档(记号里全部省去了对参数的依赖):
(1) 以概率 𝑃(𝑑𝑚) 选择一篇文档 𝑑𝑚
(2) 以概率 𝑃(𝑧𝑘|𝑑𝑚) 得到一个主题 𝑧𝑘
(3) 以概率 𝑃(𝑤𝑛|𝑧𝑘) 生成一个词 𝑤𝑛
概率图模型

图里面的浅色节点代表不可观测的隐变量,
方框是指变量重复(plate notation),
内部方框表示的是文档 𝑑𝑚 的长度是 N,
外部方框表示的是文档集共 M 篇文档。
pLSA 模型的参数 𝜃 显而易见就是:𝐾×𝑀 个 𝑃(𝑧𝑘|𝑑𝑚) 、𝑉×𝐾 个 𝑃(𝑤𝑛|𝑧𝑘) 。
𝑃(𝑧𝑘|𝑑𝑚) 表征的是给定文档在各个主题下的分布情况,文档在全部主题上服从多项式分布(共 M 个);
𝑃(𝑤𝑛|𝑧𝑘) 则表征给定主题的词语分布情况,主题在全部词语上服从多项式分布(共 K 个)。
一共有NK + MK个自变量,如果直接对这些自变量求偏导数,我们会发现由于自变量包含在对数和中,这个方程的求解很困难。因此对于这样的包含“隐含变量”或者“缺失数据”的概率模型参数估计问题,我们采用EM算法。
联合分布–P( dm, wn)
考虑最大化对数似然函数:


EM推导
EM算法的步骤是:
(1)E步骤:求隐含变量Given当前估计的参数条件下的后验概率。
(2)M步骤:最大化Complete data对数似然函数的期望,此时我们使用E步骤里计算的隐含变量的后验概率,得到新的参数值。
两步迭代进行直到收敛。
在PLSA中,Incomplete data 是观察到的(dm, wn),隐含变量是主题 𝑧𝑘,那么complete data就是三元组(dm, wn,𝑧𝑘)
针对我们PLSA参数估计问题
在E步骤中,直接使用贝叶斯公式计算隐含变量在当前参数取值条件下的后验概率,有
在这个步骤中,我们假定所有的𝑃(𝑧𝑘|𝑑𝑚) 、和𝑃(𝑤𝑛|𝑧𝑘) 都是已知的,初始时随机赋值,后面迭代的过程中取前一轮M步骤中得到的参数值。
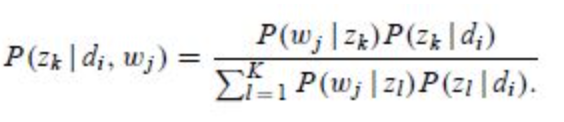
在M步骤中,我们最大化Complete data对数似然函数的期望(即把其中与z相关的部分积分掉)
PLSA模型的缺点
plsa过拟合现象
PLSA有时会出现过拟合的现象。所谓过拟合(Overfit),是这样一种现象:一个假设在训练数据上能够获得比其他假设更好的拟合,但是在训练数据外的数据集上却不能很好的拟合数据。此时我们就叫这个假设出现了overfit的现象。
原因
出现这种现象的主要原因是训练数据中存在噪音或者训练数据太少。
解决方法
要避免过拟合的问题,PLSA使用了一种广泛应用的最大似然估计的方法,期望最大化。
PLSA中训练参数的值会随着文档的数目线性递增。
PLSA可以生成其所在数据集的的文档的模型,但却不能生成新文档的模型。
通过修改EM(期望最大化)的算法来避免这个问题,我么把这个算法称为强化的期望最大化算法(tempered EM)。
强化的期望最大化算法中引入了控制参数beta。Beta值起始是1,紧着逐渐减少。
引入beta的目的就是为了避免过拟合的问题,在beta中,过拟合和不充分拟合的状态被定义。
具体的算法是:让beta的初始值为1,然后根据待训练数据来测试模型,如果成功,则使用该beta,如果不成功,则收敛。收敛的意思就是使得beta = n*beta, n<1。
PLSA 判断文档主题
根据 𝑃(𝑧𝑘|𝑑𝑚)得到主题
参考:
https://www.cnblogs.com/Determined22/p/7237111.html
https://blog.csdn.net/pipisorry/article/details/42560877















 4850
4850











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









