






1、PLSA的公式表达(两种)
在“主题模型Topic Model”一文中已经说明了从生成模型的角度如何看待主题模型。
主题模型的线性代数表示:
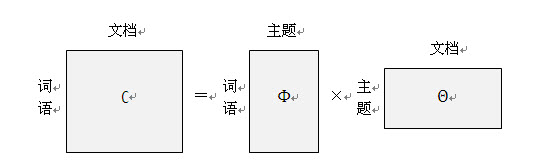
主题模型就是已知“词语-文档”矩阵C,求“词语-主题”矩阵Φ和“主题-文档”矩阵θ。
一种思路就是使用EM(期望最大化)算法来求解Φ和θ,即PLSA。
回忆一下主题模型的数学表达:
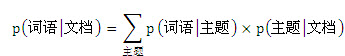
现在我们用w表示词语,用d表示文档,用c表示主题,则有公式(1):
P(w|d) =∑P(w | c)P(c | d) ......(1)
考虑联合概率分布P(w,d)与条件概率分布P(w|d) 的关系(贝叶斯公式),则有公式(2):
P(w,d) =P(d)P(w|d)......(2)
由公式(1)和公式(2)得公式(3):
P(w,d) =P(d)∑P(w | c)P(c | d)......(3)
这就是PLSA的第一种公式表达。
再思考一下贝叶斯公式:
P(c | d) = P(c,d)/P(d) = P(d,c)/P(d) = P(d|c)P(c)/P(d)
所以对于公式(3)来说有公式(4):
P(w,d) =P(d)∑P(w | c)P(c | d)=P(d)∑P(w | c) P(d|c)P(c)/P(d)=∑P(w | c) P(d|c)P(c)
P(w,d) =∑P(w | c) P(d|c)P(c)......(4)
此为PLSA的第二种公式表达。
2、EM(期望最大化)算法
详见“从最大似然到EM算法浅解”一文。
3、PLSA中的EM算法
pLSA采用的方法叫做EM(期望最大化)算法,它包含两个不断迭代的过程:E(期望)过程和M(最大化)过程。用一个形象的例子来说吧:比如说食堂的大师傅炒了一盘菜,要等分成两份给两个人吃,显然没有必要拿天平去一点点去精确称量,最简单的办法是先随意的把菜分到两个碗中,然后观察是否一样多,把比较多的那一份取出一点放到另一个碗中,这个过程一直重复下去,直到大家看不出两个碗里的菜有什么差别为止。
对于主题模型训练来说,“计算每个主题里的词语分布”和“计算训练文档中的主题分布”就好比是在往两个人碗里分饭。在E过程中,我们通过贝叶斯公式可以由“词语-主题”矩阵计算出“主题-文档”矩阵。在M过程中,我们再用“主题-文档”矩阵重新计算“词语-主题”矩阵。这个过程一直这样迭代下去。EM算法的神奇之处就在于它可以保证这个迭代过程是收敛的。也就是说,我们在反复迭代之后,就一定可以得到趋向于真实值的 Φ和 Θ。















 3001
3001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









