










本文是TensorFlow学习笔记的第二部分,这部分主要介绍神经网络中的激活函数、损失函数、优化算法和正则项。
1.激活函数
激活函数可以将线性变换转换为非线性变换,神经元可以表示为:z=f(wx+b),其中wx+b得到的是一个对输入x的一个线性变换,映射函数f就是激活函数,f可以将wx+b的结果映射到一个指定范围内的值,从而达到非线性变换的功能。加入激活函数之后的神经元可以学习更为复杂的特征。
目前TensorFlow提供了7种不同的非线性激活函数,比较常用的激活函数有:tf.nn.relu、tf.sigmoid和tf.tanh三种,这三种激活函数的图像如下所示:
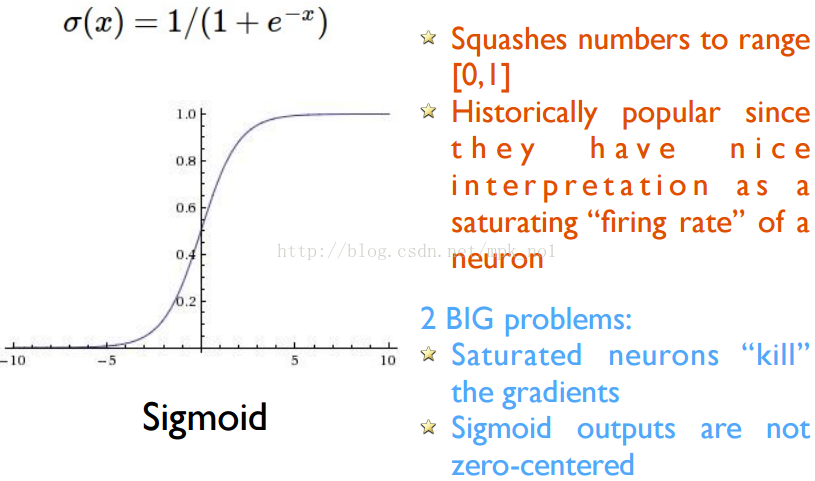
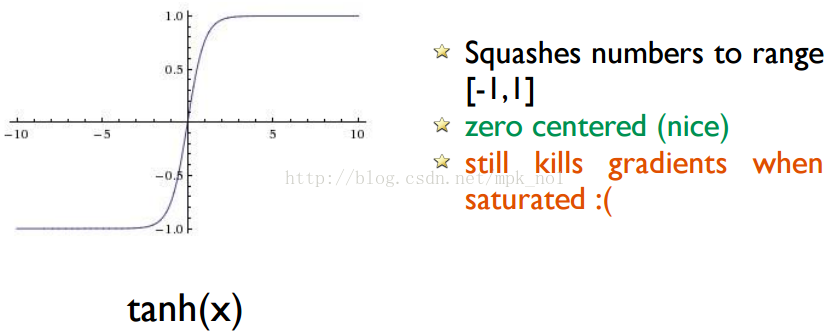

2.损失函数
常见的用于分类的损失函数有:交叉熵
交叉熵的定义公式为: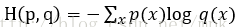
交叉熵刻画的是两个概率分布的距离,也就是说交叉熵值越小,两个概率分布越接近。
TensorFlow中交叉熵的可以用以下代码实现:
cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0)))
其中,y_代表正确结果,y代表预测结果。通过tf.clip_by_value函数可以将一个张量中的数值限制在一个范围之内,这样可以避免一些运算错误(比如log0是无效的)。tf.log函数是逐元素计算log值,*代表两个矩阵相乘,是元素之间的直接相乘,不是矩阵乘法。
常见的用于回归的损失函数有:均方误差(MSE)
均方误差的定义公式为:
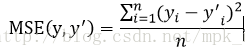
TensorFlow中实现军方无产的代码为:
mse = tf.reduce_mean(tf.square(y_ - y))
TensorFlow还支持自定义损失函数,如下面这个损失函数:
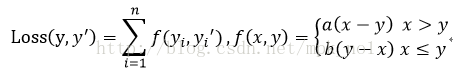
在TensorFlow中,可以用下面的代码实现:
loss = tf.reduce_sum(tf.where(tf.greater(v1, v2), (v1 - v2) * a, (v2 - v1) * b))
其中,tf.greater()的输入是两个张量,此函数会比较这两个张量中每一个元素的大小,并返回比较结果,如果结果为true,则选择第二个参数中的值,否则选择第三个参数中的值。
3.优化算法
神经网络的优化过程可以分为两个阶段,第一个阶段先通过前向传播算法计算得到预测值,并将预测值和真实值作对比得出两者之间的差距。第二个阶段通过反向传播算法计算损失函数对每一个参数的梯度,再根据梯度和学习率使用梯度下降算法更新每一个参数。
假设用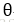
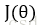
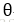

在反向传播算法中,参数的更新公式为:
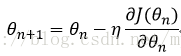
梯度下降算法有两个缺点;一是不一定能达到全局最优,二是计算时间太长。
针对第二个问题,可以使用随机梯度下降算法,随机梯度下降算法不在全部训练数据上进行优化,二是在每一轮迭代中,随机优化某一条训练数据上的损失函数,这样可以大大加快参数更新速度。但是它也有缺点:在某一条数据上损失函数更小并不代表在全部数据上损失函数更小。因此实际中经常使用的是两个算法的折中——每次计算一小部分训练数据的损失函数,即经常使用batch。
所以一般的训练代码是这样的格式:
bath_size = n
#定义神经网络结果和优化算法
loss = ....
train_step = tf.train.AsamOptimizer(0.001).minimize(loss)
#训练神经网络
with tf.Session() as sess:
#参数初始化
...
#迭代地更新参数
for i in range(STEPS):
#准备batch_size个训练数据
current_X, current_Y = ...
sess.run(train_step, feed_dict={x: current_X, y_: current_Y})
学习率的设置:
学习率决定了参数更新的幅度,如果幅度过大,那么可能导致参数在极优值的两侧来回移动,如果幅度过小,则收敛速度会很慢。
TensorFlow提供了一种更加灵活的学习率设置方法——指数衰减法。tf.train.exponential_decay函数实现了指数衰减学习率。通过这个函数,可以先使用较大的学习率来快速得到一个比较优的解,然后随着迭代的继续逐步减小学习率,使得模型在训练后期更加稳定。
exponential_decay函数实现的是以下代码的功能:
decayed_learning_rate = learning_rate * decay_rate ^ (global_step / decay_step)
其中,decayed_learning_rate为每一轮优化时使用的学习率,learning_rate为事先设定的初始学习率,decay_rate为衰减系数,decay_steps为衰减速度。tf.train.exponential_decay函数可以设置参数staircase选择不同的衰减方式。staircase默认为False,代表的是连续的衰减曲线;设为True时,代表的是阶梯型的学习率衰减曲线,global_step/decay_step会被转化为整数,可以设置为每完整地过完一遍训练数据,学习率就减小一次。阶梯型的学习率是比较常用的一种方式,因为它使得在一轮迭代过程中每一个样本都是同等地参与到了参数的更新过程中。
指数衰减学习率的使用代码如下所示:
global_step = tf.Variable(0)
#通过exponential_decay函数生成学习率
learning_rate = tf.train.exponential_decay(0.1, global_step, 100, 0.96, staircase = True)
#使用指数衰减的学习率,在minimize函数中传入global_step将自动更新
learning_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss..., global_step = global_step)
上面这段代码中设定了初始学习率为0.1,因为指定了staircase=True,所以每训练100轮后学习率乘以0.96。
4.正则项
使用正则项是为了解决过拟合问题。正则化的思想是在损失函数中加入刻画模型复杂程度的指标,通过限制权重的大小,使得模型不能任意拟合训练数据中的随机噪音。
假设用于刻画模型在训练数据上表现的损失函数为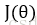
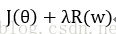
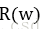
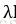
常用的刻画模型复杂度的函数有两种,一种是L1正则化,计算公式为:
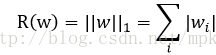
TensorFlow中实现代码为:
tf.contrib.layers.l1_regularizer(.5)(weights)
另一种是L2正则化,计算公式为:
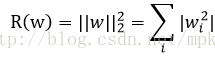
TensorFlow中实现代码为:
tf.contrib.layers.l2_regularizer(.5)(weights)
L1正则化和L2正则化的区别:
L1正则化会让参数变得更稀疏,L2正则化会让参数更发散,值变小,接近于0;
L1正则化的计算公式不可导,而L2正则化公式可导,更容易求解。
实践中,也可以将L1正则化和L2正则化同时使用:
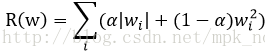
下面的代码是融合了激活函数、损失函数、优化算法和正则项的一个神经网络的示例,仅供参考:
#custom loss function
import tensorflow as tf
from numpy.random import RandomState
batch_size = 8
#获取一层神经网络边上的权重,并将这个权重的L2正则化损失加入名为‘losses’的集合中
def get_weight(shape, lam):
var = tf.Variable(tf.random_normal(shape), dtype=tf.float32)#生成一个变量
tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(lam)(var))#add_to_collection函数将这个新生成变量的L2正则化损失加入集合
return var
x = tf.placeholder(tf.float32, shape=(None, 2), name='x-input')
y_ = tf.placeholder(tf.float32, shape=(None, 1), name='y-input')
#define the forward network
layer_dim = [2, 10, 10, 10, 1]#定义了每一层网络中节点的个数
n_layers = len(layer_dim)#神经网络的层数
cur_layer = x
in_dim = layer_dim[0]#当前层的节点个数
#通过一个循环来生成一个5层全连接的神经网络结构
for i in range(1, n_layers):
out_dim = layer_dim[i]#下一层的节点个数
weight = get_weight([in_dim, out_dim], 0.001)#生成当前层中权重的变量,并将L2正则化损失加入losses集合中
bias = tf.Variable(tf.constant(0.1, shape=[out_dim]))
cur_layer = tf.nn.relu(tf.matmul(cur_layer, weight) + bias)#使用relu激活函数
in_dim = layer_dim[i]
#模型在训练数据上的损失函数,这里是均方误差
mse_loss = tf.reduce_mean(tf.square(y_ - cur_layer))
#将均方误差损失函数加入losses集合中
tf.add_to_collection('losses', mse_loss)
#将losses集合中的所有损失函数加起来得到最终的损失函数
loss = tf.add_n(tf.get_collection('losses'))
train_step = tf.train.AdamOptimizer(0.001).minimize(loss)
#produce the data
rdm = RandomState(1)
dataset_size = 128
X = rdm.rand(dataset_size, 2)
Y = [[x1 + x2 + rdm.rand()/10.0-0.05] for (x1, x2) in X]
#creare a session
with tf.Session() as sess:
#init all variable
init_op = tf.initialize_all_variables()
sess.run(init_op)
STEPS = 5000
for i in range(STEPS):
#get batch_size samples data to train
start = (i * batch_size) % dataset_size
end = min(start + batch_size, dataset_size)
#train model
sess.run(train_step, feed_dict = {x : X[start : end], y_ : Y[start : end]})
if i % 1000 == 0:
total_cross_entropy = sess.run(loss, feed_dict={x : X, y_ : Y})
print ("After %d training steps, cross_entropy on all data is %g" %(i, total_cross_entropy))














 1517
1517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









