







 本文介绍了使用Word2vec和Doc2vec进行句子对匹配的方法,特别是针对Paraphrase任务。通过训练Doc2vec和Word2vec模型,计算句子的cosin相似度来判断语义等价性。实验结果显示,Doc2vec在表示句子方面表现优于Word2vec。
本文介绍了使用Word2vec和Doc2vec进行句子对匹配的方法,特别是针对Paraphrase任务。通过训练Doc2vec和Word2vec模型,计算句子的cosin相似度来判断语义等价性。实验结果显示,Doc2vec在表示句子方面表现优于Word2vec。
句子对匹配(Sentence Pair Matching)问题是NLP中非常常见的一类问题,所谓“句子对匹配”,就是说给定两个句子S1和S2,任务目标是判断这两个句子是否具备某种类型的关系。如果形式化地对这个问题定义,可以理解如下:
![]()
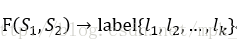
意思是给定两个句子,需要学习一个映射函数,输入是两个句子对,经过映射函数变换,输出是任务分类标签集合中的某类标签。
意思是给定两个句子,需要学习一个映射函数,输入是两个句子对,经过映射函数变换,输出是任务分类标签集合中的某类标签。
典型的例子就是Paraphrase任务,即要判断两个句子是否语义等价,所以它的分类标签集合就是个{等价,不等价}的二值集合。除此外,还有很多其它类型的任务都属于句子对匹配,比如问答系统中相似问题匹配和Answer Selection。
由于本文只是一个Word2vec和Doc2vec的应用,是一种无监督的句子对匹配方法,所以这里的映射函数F即为计算两个句子的cosin相似度。
cosin相似度计算公式如下:

基于Word2vec和Doc2vec的句子对匹配方法主要分为三步:
1.训练语料库的Doc2vec和Word2vec模型;
2.用Doc2vec或Word2vec得到句子的向量表示;
3.计算句子向量的cosin相似度,即为两个句子的匹配程度。
其中,语料库使用的是Quora发布的Question Pairs语义等价数据集,可以点击这个链接下载点击打开链接,其中包含了40多万对标注好的问题对,如果两个问题语义等价,则label为1,否则为0。统计之后,共有53万多个问题。具体格式如下图所示:

将这53万多个问题作为语料库,训练Doc2vec和Word2vec模型,即完成了第一步;
# -*- coding: utf-8 -*-
import logging
import os.path
import sys
import multiprocessing
from gensim. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









