







 本文介绍了在Windows环境下使用Caffe进行深度学习时遇到的问题及解决办法,包括数据转换、求均值、微调Finetune的步骤,以及如何提取某一层特征。此外,还分享了在编写prototxt文件和调参过程中的一些实用技巧。
本文介绍了在Windows环境下使用Caffe进行深度学习时遇到的问题及解决办法,包括数据转换、求均值、微调Finetune的步骤,以及如何提取某一层特征。此外,还分享了在编写prototxt文件和调参过程中的一些实用技巧。
转换数据,求均值:
转换数据
步骤大概是:建立一个train文件夹,里面放一个train.txt;建立一个test文件夹,里面放一个test.txt,然后分别运行以下两条bat命令:
SET GLOG_logtostderr=1
convert_imageset.exe train/ train/train.txt convert_data_train
pause
SET GLOG_logtostderr=1
convert_imageset.exe test/ test/test.txt convert_data_test
pause
当然,也会出现错误,可能有以下几点原因:
1、路径没有设置正确;2、txt里面包含了本来没有的文件;3、如果convert_data_train和convert_data_test文件夹本来就存在,那么也会报错。
生成的数据将会保存在:convert_data_train和convert_data_test文件夹内。
求均值:
SET GLOG_logtostderr=1
compute_image_mean.exe convert_data_train image_mean.binaryproto
pause
注意文件夹是不是存在的。
微调Finetune:
由于要用caffe做人脸识别,自己刚入手又不可能配置网络,那么只有下载已经有的模型进行微调。我对微调概念的理解就是,让这个caffemodel能够更加合你的数据。
然后被小坑了一下。我下载了vgg的模型,一个caffemodel,一个deploy.prototxt,然后上网查如何进行微调,思路是:自己的train,test数据转换–>求均值–>改写deploy.prototxt文件–>撰写solver.prototxt。
前两步都还好,没有问题,在改写的时候,要先加入数据层,也就是要删掉原来的:
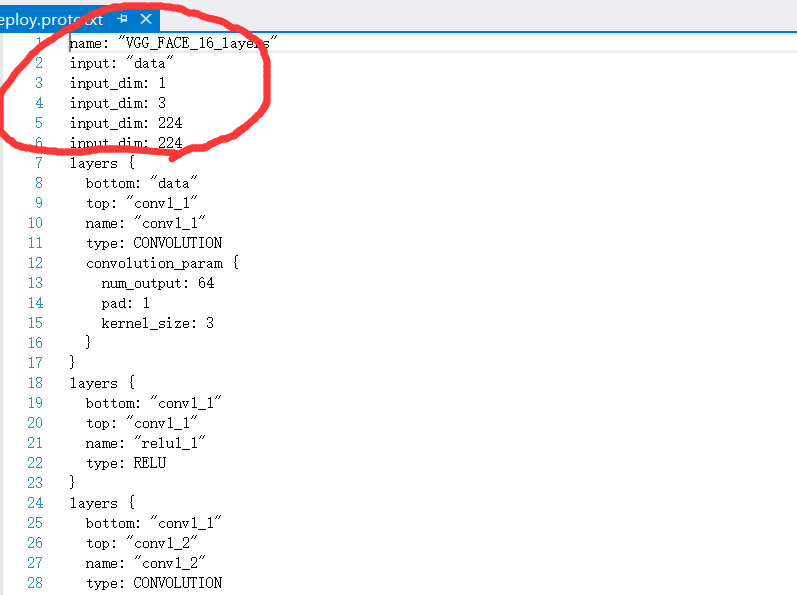
然后加入一个数据层。看网上有一个教程是这么加的:
name: "vggface_train_test.prototxt"
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 224
mean_file: "vggface/face_mean.binaryproto"
}
data_param {
source: "vggface/face_train_lmdb"
batch_size: 20
backend: LMDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2674
2674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









