







 本文探讨了函数调用的演变历程,通过分析Linux内核源码,揭示了从早期的汇编语言到现代高级语言中函数调用的实现原理。同时,文章还涉及了内存管理、编译器优化以及在VC++中的应用。
本文探讨了函数调用的演变历程,通过分析Linux内核源码,揭示了从早期的汇编语言到现代高级语言中函数调用的实现原理。同时,文章还涉及了内存管理、编译器优化以及在VC++中的应用。
-
通过 内核源码看函数调用之前世今生
作者:杨小华
栈(Stack
):一个有序的积累或堆积
韦氏词典
对每一位孜孜不倦的程序员来说,栈已深深的烙在其脑海中,甚至已经发生变异。栈可以用来传递函数参数、存储局部变量、以及存储返回值的信息、还可以用于保存寄存器的值以供恢复之用。
在X86平台上(又称之为IA32),应用程序借用栈来支持函数(又称为过程)调用,变量的存储按后进先出(LIFO)的方式进行。
一、 栈帧布局
在具体讲解函数调用之前,我们先来明确栈的几个概念:满栈与空栈,升序栈与降序栈。
满栈是指栈指针指向上次写的最后一个数据单元,而空栈的栈指针指向第一个空闲单元。一个降序栈是在内存中反向增长(就是从应用程序空间结束处开始反向增长),而升序栈在内存中正向增长。
RISC机器使用传统的满降序栈(FD Full Descending)。如果使用符合IA32规定的编译器,它通常把你的栈指针设置在应用程序空间的结束处并接着使用一个满降序栈。用来存放一个函数的局部变量、参数、返回地址和其它临时变量的栈区域称为栈帧(stack frame),如图1所示。
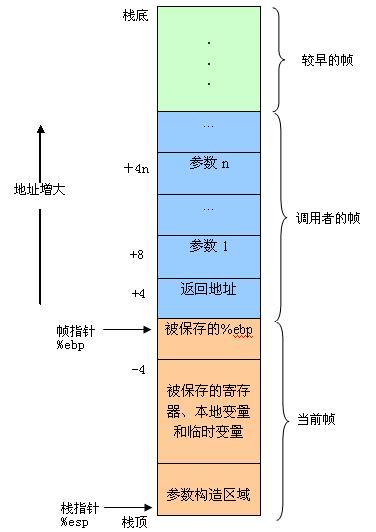
图 1 栈帧结构
栈帧布局的设计要考虑到指令集的体系结构特征和被编译的程序设计语言的特征。但是,计算机的制造者常常规定一种用于其体系结构的“标准”栈帧布局,以便被所有的程序设计语言编译器采纳。这种栈帧布局对于某些特定的程序设计语言或编译器可能并不是最方便的,但是通过这种“标准”布局,用不同程序设计语言编写的函数得以相互调用。
当P调用Q时,Q的参数是放在P的帧中的。另外,当P调用Q时,P中的下一条指令地址将被压入栈中,形成P的栈帧的末尾,具体可参见图1,返回地址就是当程序从Q返回时应该继续执行的地方。Q的栈帧从保存帧指针的位置开始,后面开始保存其他寄存器的值。Q也会用栈帧来保存其他不能存放在寄存器中的局部变量。如果函数要返回整数或指针的话,常用寄存器%eax来保存返回值。
当程序执行时,栈指针是可以移动的,因此大多数信息的访问都是相对于帧指针(%ebp)的。
二、 寄存器使用惯例
假设函数P(……)调用函数Q(a1,……,an),我们称P是调用者(caller),Q是被调用者(callee)。如果必须被调用者保存和恢复的寄存器,我们称之为
调用者保护的寄存器(caller-save);如果是被调用者的责任,则称之为
被调用者保护的寄存器(callee-save)。
程序寄存器组是唯一一个被所有函数共享的资源。虽然在给定时刻只能有一个函数是活动的,但是我们必须保证当一个函数调用另一个函数时,被调用者不会覆盖某个调用者稍后会使用的寄存器的值。
为此,任何一个平台都会制订一套标准,让所有的函数都必须遵循,包括程序库中的函数。但在大多数计算机系统结构中,调用者保护的寄存器和被调用者保护的寄存器的概念并不是由硬件来实现的,而是机器参考手册中规定的一种约定。
比如,在ARM体系平台中,所有的函数调用必须遵守ARM 过程调用标准(APCS,ARM Procedure Call Standard)。该标准提供了一套紧凑的代码编写机制,定义的函数可以与其他语言编写的函数交织在一起。其他函数可以编译自 C、 Pascal、也可以是用汇编语言写成的函数。
同理,IA32平台也采用了一套统一的寄存器使用惯例。根据惯例,寄存器%eax、%edx、%ecx被划分为调用者保存。当函数P(调用者)调用Q(被调用者)时,Q可以覆盖这些寄存器的值,而不会破坏任何P所需要的数据。另外,%ebx、%esi、%edi、%ebp被划分为被调用者保存,这意味着Q必须在覆盖他们之前,将这些寄存器的值保存到栈中,并在返回前恢复他们。
三、 参数传递惯例
大约在1960年之前,参数传递不是通过栈来传递的,而是通过一块静态分配的存储空间来传递的,这种方法阻碍了递归函数的使用。从20世纪70年代开始,大多数调用约定函数参数的传递通过栈来实现(因为访问寄存器比访问存储器要快的多),同时也会导致一些不必要的存储器访问。对实际程序的研究表明,很少有函数的参数个数是超过4个,并且极少有6个的。因此,现代计算机中的参数传递约定都规定,一个函数的前k个参数(典型的,k=4或者k=6)放在寄存器中传递,剩余的参数则放在存储器中传递。
在ARM体系平台中,APCS就明确规定:
1) 前 4 个整数实参(或者更少!)被装载到 R0 – R4寄存器中。
2) 前 4 个浮点实参(或者更少!)被装载到 f0 - f3寄存器中。
3) 其他任何实参(如果有的话)存储在内存中,用进入函数时紧接在栈指针所指向的空间。换句话说,其余的参数被压入栈顶。
但在IA32平台上,参数传递不是完全通过寄存器来实现的,而是通过栈帧来实现的。根据不同的调用方式,参数在栈帧的存放方式又有一点差别,区别如下表所示:
|
调用方式
|
参数在堆栈里的次序
|
操作方式
|
|
_cdecl
|
第一个参数在低位地址
|
调用者
|
|
_stdcall
|
第一个参数在低位地址
|
被调用者
|
|
_fastcall
|
编译器指定
|
被调用者
|
|
_pascal
|
第一个参数在高位地址
|
被调用者
|
Borland 和 GNU 编译器使用 _cdecl 方式,而 Microsoft 使用 _stdcall 方式。通过这里可以发现,当今两大主流的编译器,第一个参数都在低地址,也就是说第一个参数是最后一个压栈的,当被调用函数被调用时,此时就赋值给了第一个形参。
四、 Linux内核源码研究
下面我们以Linux内核中断处理源代码来研究函数调用的本质。本文所提及的内核代码版本为2.6.10,读者需了解GCC汇编语言的基础知识。
当某个中断发生后,将会执行push $i-256,jmp common_interrupt指令,此时将会跳转到
common_interrupt处执行。
|
文件名:arch/i386/kernel/entry.S(说明:前面的数字表示行号)
359 ALIGN
360 common_interrupt:
361 SAVE_ALL
362 movl %esp,%eax
363 call do_IRQ
364 jmp ret_from_intr
|
这里主要的操作是宏操作SAVE_ALL,就是所谓的“保存现场”,把中断发生前夕所有寄存器的内容都保存在堆栈中,待中断服务完毕返回之前再来“恢复现场”。
|
文件名:arch/i386/kernel/irq.c
48 fastcall unsigned int do_IRQ(struct pt_regs *regs)
49 {
50 /* high bits used in ret_from_ code */
//取得中断向量号
51 int irq = regs->orig_eax & 0xff;
52 #ifdef CONFIG_4KSTACKS
53 union irq_ctx *curctx, *irqctx;
54 u32 *isp;
55 #endif
……
107 }
|
下面我们来分析SAVE_ALL和do_IRQ 函数中的struct pt_regs结构体。
|
文件名:arch/i386/kernel/entry.S
|
文件名:include/asm-i386/ptrace.h
|
|
84 #define SAVE_ALL /
85 cld; /
86 pushl %es; /
87 pushl %ds; /
88 pushl %eax; /
89 pushl %ebp; /
90 pushl %edi; /
91 pushl %esi; /
92 pushl %edx; /
93 pushl %ecx; /
94 pushl %ebx; /
95 movl $(__USER_DS), %edx; /
96 movl %edx, %ds; /
97 movl %edx, %es;
|
26 struct pt_regs {
27 long ebx;
28 long ecx;
29 long edx;
30 long esi;
31 long edi;
32 long ebp;
33 long eax;
34 int xds;
35 int xes;
36 long orig_eax;
37 long eip;
38 int xcs;
39 long eflags;
40 long esp;
41 int xss;
42 };
|
从以上代码可以看出,SAVE_ALL中,依次将寄存器中的值压入栈中,其中最后一个压入的是pushl %ebx;我们观察struct pt_regs结构体,可以看出该结构体的第一个成员变量就是long ebx;然后就依次对应。其中long orig_eax;的所对应的push 语句为:push $i-256。是在jmp common_interrupt之前压入的。细心的读者可能还会产生另外一个疑问: struct pt_regs结构体中最后几个变量怎么在SAVE_ALL中没有对应的push。因为在进入中断服务程序之前,已经将这部分值压进栈中了,这是由硬件来完成的。
从以上可以看出,在IA32平台上,参数的传递不是通过寄存器来实现的,而是通过栈帧来实现。但这并不是在Linux 操作系统上如此,而是所有的IA32平台都是如此,不管是何种操作系统,何种编译器,都得遵循前面所提及的规范。
下面我们仍以中断为例,在内核中调用者是如何保护寄存器的。
|
48 fastcall unsigned int do_IRQ(struct pt_regs *regs)
49 {
……
73 #ifdef CONFIG_4KSTACKS
……
92 asm volatile(
93 " xchgl %%ebx,%%esp /n"
94 " call __do_IRQ /n"
95 " movl %%ebx,%%esp /n"
96 : "=a" (arg1), "=d" (arg2), "=b" (ebx)
97 : "0" (irq), "1" (regs), "2" (isp)
98 : "memory", "cc", "ecx"
99 );
……
101 #endif
|
上述代码中的第一个冒号表示输出值,第二个冒号表示是输入值,第三个冒号后表示将被破坏的部分,需要恢复的值。在该段代码中,将会调用__do_IRQ()函数,由于在调用完该函数后,还会用到ecx的值,所有需要保存将ecx的值。那么在__do_IRQ()函数中就可以毫无忌惮的使用ecx寄存器。
从上例还可以发现,函数的输出值往往都存贮在寄存器eax中。第一个冒号后的"=a" (arg1)表示将变量arg1和eax绑定,也就是arg1 = eax。
五、 案例分析
前不久,笔者在逛CSDN论坛时,发现不少人对如下题目展开了激烈的讨论。
|
#include<stdio.h>
low_to_up(char in);
void main()
{
printf("%c/n",low_to_up('d'));
}
low_to_up(char in)
{
char ch;
if(in>='a' && in<='z')
ch=in-'a'+'A';
else
return(ch);
}
|
我们先在VC++ 6.0中反汇编这段代码:
|
1: #include<stdio.h>
2: low_to_up(char in);
3:
4: void main()
5: {
00401020 push ebp
00401021 mov ebp,esp
00401023 sub esp,40h
00401026 push ebx
00401027 push esi
00401028 push edi
00401029 lea edi,[ebp-40h]
0040102C mov ecx,10h
00401031 mov eax,0CCCCCCCCh
00401036 rep stos dword ptr [edi]
6: printf("%c/n",low_to_up('d'));
00401038 push #64h d的ASC码 (1处)
0040103A
call @ILT+5(low_to_up) (0040100a)
0040103F add esp,4
00401042 push eax # (5处)
00401043 push offset string "%c/n" (0042001c)
00401048 call printf (004010e0)
0040104D add esp,8
7: }
00401050 pop edi
00401051 pop esi
00401052 pop ebx
00401053 add esp,40h
00401056 cmp ebp,esp
00401058 call __chkesp (00401160)
0040105D mov esp,ebp
0040105F pop ebp
00401060 ret
8:
9: low_to_up(char in)
10: {
00401080
push ebp
00401081 mov ebp,esp
00401083 sub esp,44h
00401086 push ebx
00401087 push esi
00401088 push edi
00401089 lea edi,[ebp-44h]
0040108C mov ecx,11h
00401091 mov eax,0CCCCCCCCh
00401096 rep stos dword ptr [edi]
11: char ch;
12: if(in>='a' && in<='z')
00401098 movsx eax,byte ptr [ebp+8] # (2处)
0040109C cmp eax,61h
0040109F jl low_to_up+36h (004010b6)
004010A1 movsx ecx,byte ptr [ebp+8]
004010A5 cmp ecx,7Ah
004010A8 jg low_to_up+36h (004010b6)
13: ch=in-'a'+'A'; 004010AA movsx edx,byte ptr [ebp+8] # (3处)
004010AE sub edx,20h
004010B1 mov byte ptr [ebp-4],dl
14: else
004010B4 jmp low_to_up+3Ah (004010ba)
15: return(ch); 004010B6 movsx eax,byte ptr [ebp-4]
16: }
004010BA pop edi # 恢复寄存器的值,做返回处理 (7处)
004010BB pop esi
004010BC pop ebx
004010BD mov esp,ebp
004010BF pop ebp
004010C0 ret
|
从以上汇编可以看出,被调用者保存的寄存器在这里体现的酣畅淋漓。在被调用者函数中,根本不会管调用者保存的寄存器,直接使用。这里还体现了常用eax来存贮返回值。由于是使用eax做返回值,所以在5处,直接将eax压栈,所以该程序在VC++6.0中,打印”d”。由于在low_to_up()函数中,在比较过程中借用了eax寄存器。按正常的流程,在执行完if语句后,应该有一条恰当的退出语句,所以导致没有执行7处的汇编语句,把正确的值存储到eax中。从而阴差阳错的,在执行printf时,打印了错误的值。这有可能是VC++编译器的bug?
GCC的编译器似乎技高一筹,表现的更尽人意。下面我们来分析GCC反汇编后的代码(阅读这部分代码需了解GCC汇编语法):
|
.file "csdn.c"
.text
.type low_to_up, @function
low_to_up:
pushl %ebp
movl %esp, %ebp
subl $8, %esp
movl 8(%ebp), %eax # (2处)
movb %al, -1(%ebp)
cmpb $96, -1(%ebp)
jle .L2
cmpb $122, -1(%ebp)
jg .L2
movzbl -1(%ebp), %eax
subb $32, %al
movb %al, -2(%ebp) # (3处)
jmp .L3
.L2:
movsbl -2(%ebp),%eax
movl %eax, -8(%ebp) # (5处)
jmp .L1
.L3:
.L1:
movl -8(%ebp), %eax # (4处) leave
ret
.size low_to_up, .-low_to_up
.section .rodata
.LC0:
.string "%c/n"
.text
.globl main
.type main, @function
main:
pushl %ebp
movl %esp, %ebp
subl $8, %esp
andl $-16, %esp
movl $0, %eax
subl %eax, %esp
movl $100, (%esp) #将d的值压入到栈中,然后调用low_to_up()函数 (1处)
call low_to_up
movl %eax, 4(%esp) # (6处)
movl $.LC0, (%esp)
call printf
movl $0, %eax
leave
ret
.size main, .-main
.section .note.GNU-stack,"",@progbits
.ident "GCC: (GNU) 3.3.5 (Debian 1:3.3.5-13)"
|
从以上代码可以看出,调用函数时,GCC编译器和VC++的编译器所做的处理差不多。但GCC把局部变量ch压在ebp-8处。然后用ebp-1/ebp-2做临时存储。我们从5处可以发现,在else语句中,编译器会将ebp-2的值压入到eax中,然后又将eax中的值在压入到ebp-8处,即ch的栈中。当返回时,会从ebp-8处取出ch的值,然后赋值给eax,退栈返回。在6处,将eax的值压栈,然后调用printf,输出值。由于在if条件中,并没有将值存储到ch中,所以在low_to_up函数返回时,当执行4处的汇编代码时,将ch处的随机值放到了eax中,所以该程序在Linux环境下,输出值为随机值。
笔者猜测,如果在L3处的加上一段和L2处相同的代码,那么就可以获得正确的值。笔者然后就在代码中的if语句条件中加入了return 语句,GCC反汇编后的代码验证了笔者的猜测,代码如下:
|
low_to_up:
pushl %ebp
movl %esp, %ebp
subl $8, %esp
movl 8(%ebp), %eax
movb %al, -1(%ebp)
cmpb $96, -1(%ebp)
jle .L2
cmpb $122, -1(%ebp)
jg .L2
movzbl -1(%ebp), %eax
subb $32, %al
movb %al, -2(%ebp)
jmp .L3
.L2:
movsbl -2(%ebp),%eax
movl %eax, -8(%ebp)
jmp .L1
.L3:
movsbl -2(%ebp),%eax
movl %eax, -8(%ebp)
.L1:
movl -8(%ebp), %eax
leave
ret
|
六、 总结
综上所述,当我们了解了函数调用规律后,结合汇编代码,在实际项目开发过程中可以定位一些让人比较琢磨不透的问题。也不要在项目中采用案例中的程序,给项目移植性造成困难。为什么在这个平台下好好的,怎么到了另外一个平台就出错了?
七、 参考文献
[1] Andrew W.Appel,赵克佳等译 《现代编译原理C语言描述》 人民邮电出版社 2006
[2] Randal E.Bryant等,龚奕利等译 《深入理解计算机系统》 中国电力出版社 2004
[3] Agner Fog,云风译
《怎样优化Pentium系列处理器的代码》
http://www.codingnow.com/2000/download/cpentopt.htm
[4] Linus Torvalds, Linux内核源代码(2.6.10版本) http://www.kernel.org















 1333
1333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









