






c语言函数及AAPCS的理解-基于arm分析
本文为个人学习中的笔记整理,大多是自己的理解,存在较多口语化描述,可能存在一些错误或描述不准确的地方,欢迎大家指正,共同学习。
1.函数是什么-C语言执行或编译的最小单位
我们在编写C语言程序的时候,并没有办法脱离函数编程,c编译器也是以函数为单位对文件进行编译,通常C语言编程的入口为main,存在于函数内的语句或指令会被执行,C语言编译器并不允许任何可被编译为汇编指令的语句出现在函数之外,我们可以这样理解,我们会写的C语言程序会以函数为单位被打包为一个一个的指令块(本文暂不讨论数据编译后的存储),通过反汇编来看一下函数在编译之后的存储形式:
对如下函数编译之后进行反汇编:
void test3 (void)
{
}
void test2 (void)
{
test3();
}
void test1 (void)
{
test2();
}
int main(void)
{
test1();
while (1);
}
反汇编后的结果如下图所示:
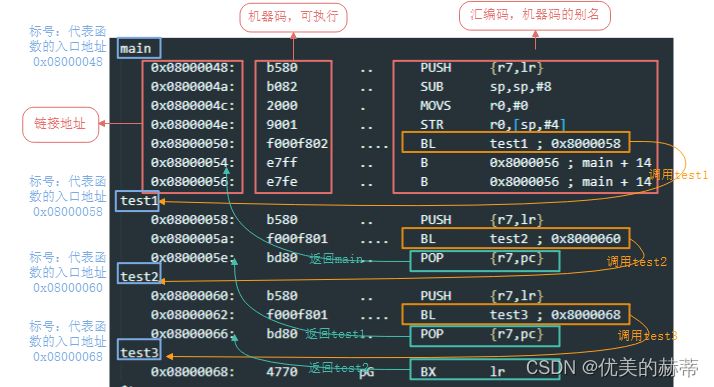
分析反汇编,可将函数抽象为两部分:入口地址+指令块(多条指令的组合),C语言函数的存在的一些概念如返回值,传参等在编译过后都不存在了,C语言函数所包含的所有信息都会包含在 入口地址+指令块(多条指令的组合)两部分,那么就会引出一个问题:C语言存在的那些概念在汇编中究竟是怎么表示的?入口地址很好理解,函数的调用即使用跳转指令跳转到函数的入口地址即可,其他概念将会在后文中说明。
2.C语言运行需要什么?
函数在编译之后会变成汇编指令,我们在写汇编的时候,指令要用到的资源,数据存放的位置都是要我们写程序的人自己处理,并不需要什么特别的前置条件。
不过C语言却并非如此,作为一门高级语言,我们可以将C语言理解为对汇编更高一层的封装,编译工具链会将C语言翻译为指令(汇编指令)+数据,指令是需要操作数据的(程序=指令+数据),在使用纯汇编编程的时候数据存放的位置都是由程序员自己指定的,方便的同时也对编程人员提出了更高的要求,C语言通过定义变量的方法,解决了数据存放的问题,从此编程人员不必再关心数据存放的位置,只需要定义出一个个的变量或对象即可,剩下的一切都由编译工具链搞定。
c编译工具链解决了数据内存手动分配的问题,方便的也相应的引入一些限制,C语言存储数据由三种形式:堆 栈 全局静态数据,
堆:并非c标准的一部分,在C语言中使用标准库函数mallc() free() 申请和释放,在更加高级的语言中(如c++ java等)都已经将动态内存申请标准化,引入了新的关键字new delete,堆本质上就是空闲内存+内存管理算法,对C语言来说,是否使用堆内存对C语言运行本身并无影响。
全局静态区域:C语言中定义的全局变量或静态变量,这部分区域的数据全局有效,一般有初始值得数据会单独放在一个段,编译结束后会存储到可执行文件中,没有初始值或初始值为零的数据会单独放在一个段中,编译结束后的可执行文件只会存储这个段的链接地址和大小(因为全是0,所以没必要全部存储在可执行文件中),对于这部分数据,为了减小bin文件的大小,这部分数据的存储地址和链接地址一般是不同的,C语言要求在由汇编跳转到c的世界之前必须保证,这些数据已经由加载地址被复制到链接地址处,这一过程一般被称为数据的重定位,当然如果不进行重定位C语言也是可以正常执行的(地址编译期已经确定绝对地址),只是C语言中定义的所有全局对象的初始状态将不能被保证,编程人员需要注意。
栈:用于局部变量或保存上下文,一些参数的传递和值的返回都要使用到栈,函数的编译会使用到栈,这是编译器决定,编程人员不可控制,所以,汇编跳转到c的世界之前必须保证栈指针指向合适的位置。
总结:对c函数来说,堆和全局数据段的初始化并非必须,全局数据段不初始化只会影响全局变量的初始值,然而栈确是必须的,c编译器在编译函数的时候总是会插入压栈和出栈的指令,C语言又是由函数组成的,所以在汇编跳转到c的世界之前必须保证栈指针指向合适的位置,至于c编译器为什么一定要在编译函数时用到压栈和出栈指令,我们在后文中接着讨论。

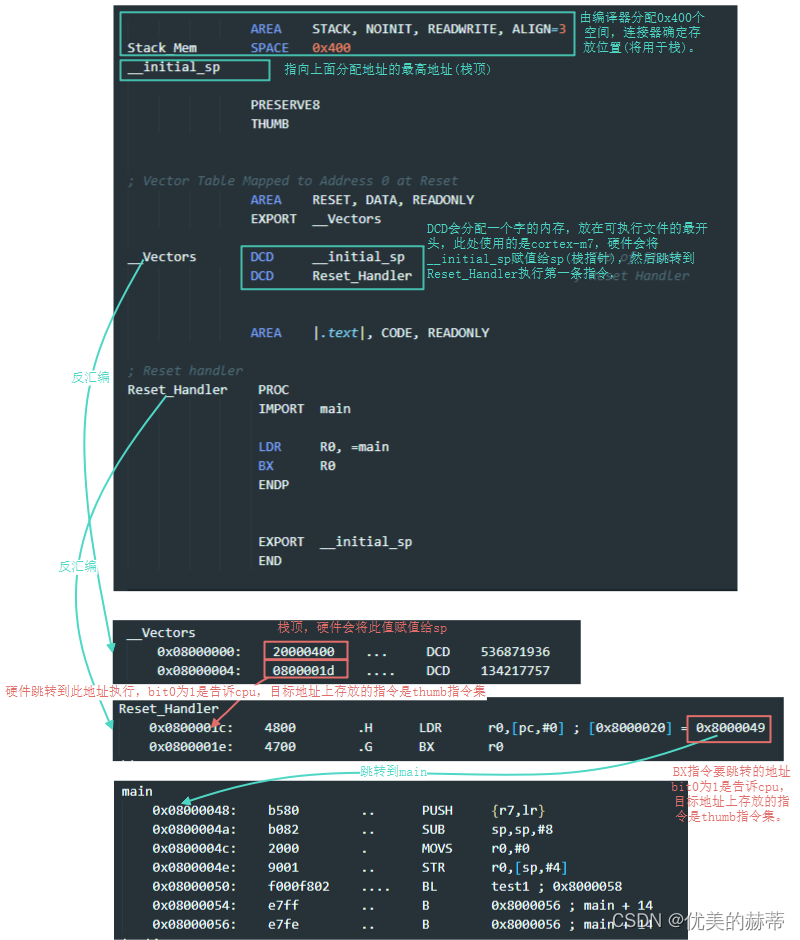
下面是一个最简单的启动汇编文件,仅仅设置栈,然后跳转到main函数即可,仅仅执行了两条指令。
注:启动文件并没有进行数据段的重定位,全局变量的值都是不确定的,但并不会影响函数的运行。
3.函数是依据什么样的规则编译成一组汇编的
参考ARM架构过程调用标准AAPCS(Procedure Call Standard for the Arm® Architecture)
由前文可知,函数依据某种规则编译为一组汇编指令,在ARM架构中,汇编指令可操作的对象分别是内存和寄存器。汇编其实就是对二进制码的重命名,对内存和寄存器的使用并没有什么限制,而C语言则不同,C语言的“指令”是以函数的形式体现的(数据则是各种形式的变量),一个应用程序往往是由多个函数组成,试想一下,函数(指令块)若随意的使用资源,各个函数就会产生冲突,如:在函数中定义了一个变量,假设这个变量使用寄存器存储,这个时候调用另一个函数,如果另一个函数也有权修改这个寄存器,那么之前定义的那个变量极有可能会被破坏。那么这个时候就需要一个协议来规定资源的分配。
3.1资源(内存,寄存器)是如何分配的?
抛开数据,C语言是由函数为单位组成的,我们以函数为单位描述资源分配的规则
3.1.1 全局数据
在C语言中的表现形式为全局变量,在编译阶段即可确定唯一的绝对地址,整个进程生命周期都有效。每个函数都可以访问,可随意更改。

3.1.2 堆
C语言标准没有规定,是由软件实现(一般c标准库会提供实现),由编译器分配一片连续的空间,然后由软件实现内存的分配和回收,也是编译阶段即可确定地址,机器码层面和全局数据没有本质区别。
3.1.3 栈
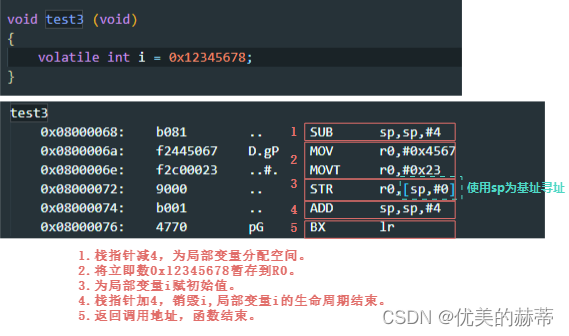
栈的本质是由编译器分配的一片连续的内存,用于保存上下文和部分局部变量,与全局数据的区别在于其是通过SP寄存器来寻址的,我们可以这样理解:每个函数都维护着一个自己的栈帧,用于保存部分局部变量和由自己所要维护的寄存器,如下是一个局部变量在栈上分配的例子,先感受一下,后文在详细分析,本段主要引入一个概念:每个函数都有自己的栈帧,在函数开始时分配,在函数结束时销毁.
3.1.4 寄存器
cortex-m架构中编译阶段会使用到的寄存器如下图所示: 寄存器可用来传参,返回值等。
在此需要引入两个概念:调用者和被调用者,寄存器的使用由两方维护,一部分由寄存器由调用者维护,一部分寄存器由被调用者维护,具体分配可参见下图:
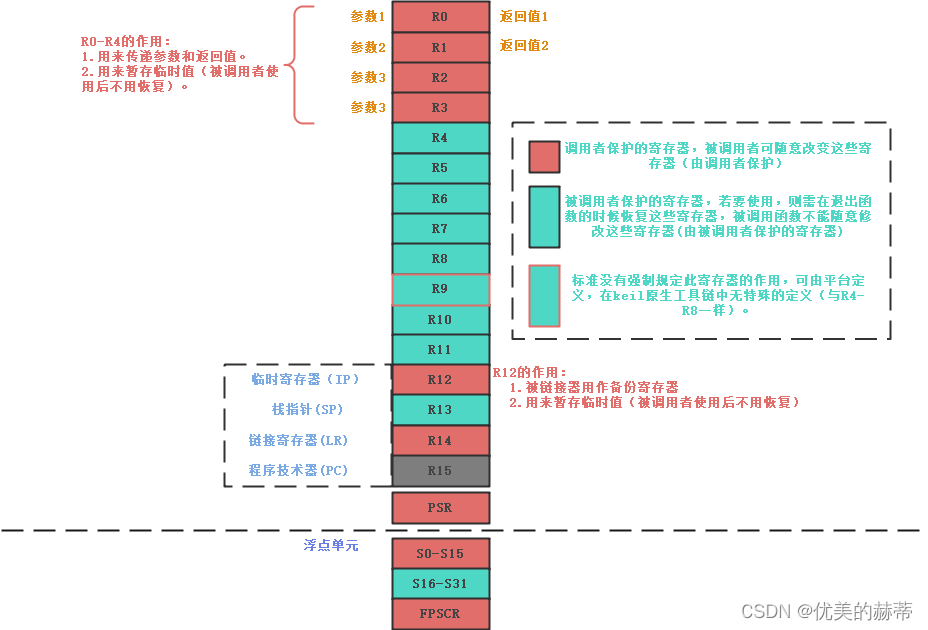
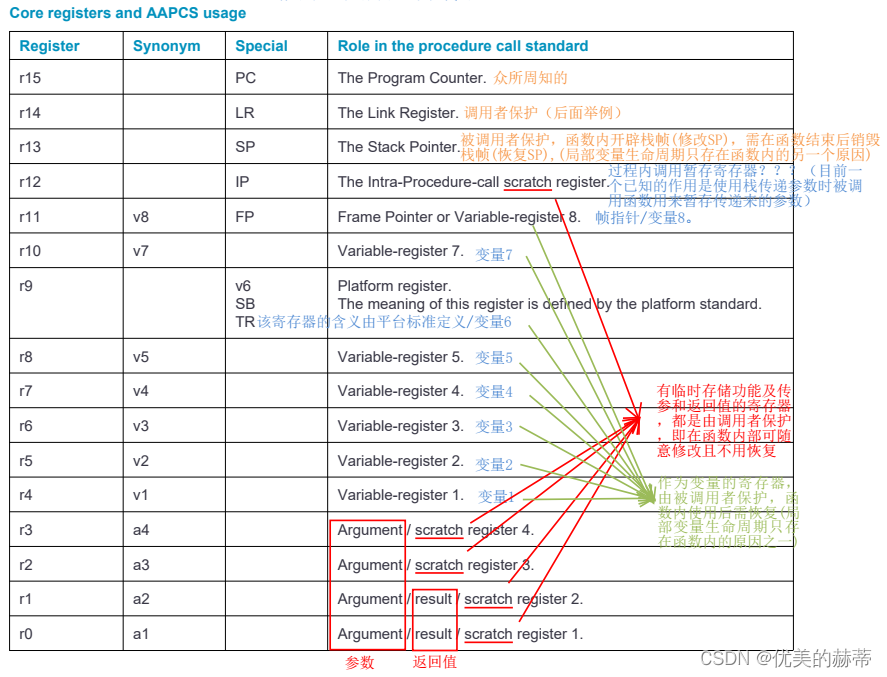
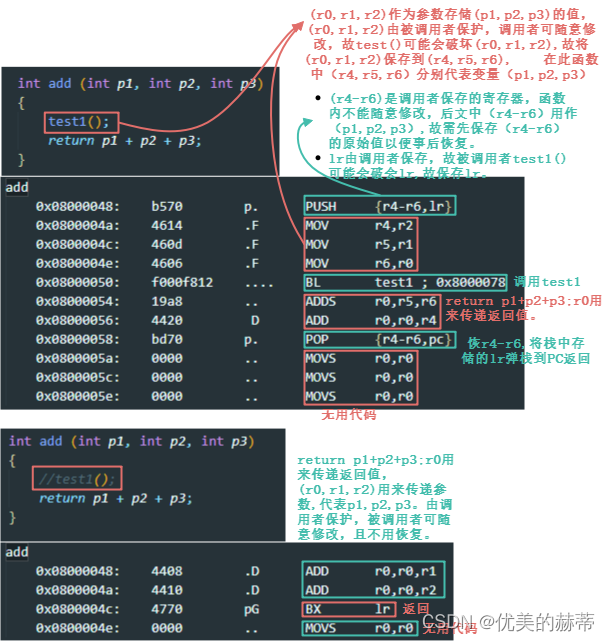
如下是一个调用者保护和被调用者保护寄存器的示例:
3.2 实验说明
3.2.1 传参实验
- 传4个参数的情况(4个参数均使用int类型,每个占4个字节 )
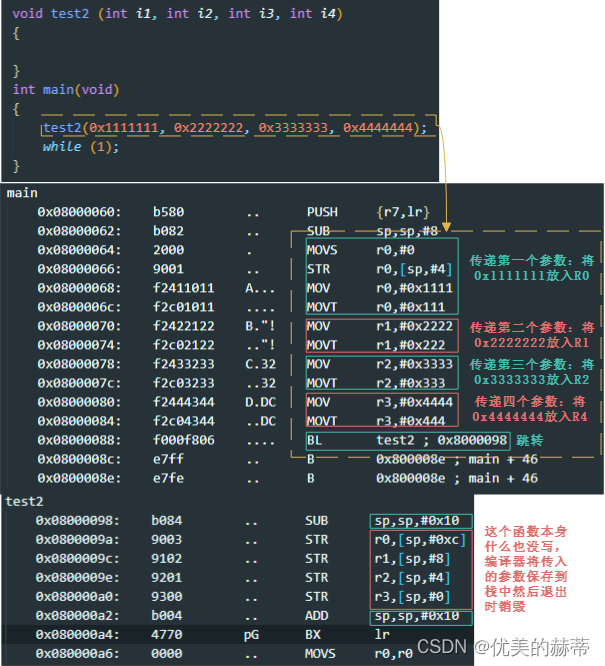
- 超过4个参数的情况

- 总结:在传参不超过4个参数的情况下使用R0-R4进行传参,超过4个参数,超出的部分使用栈传递(依据实验,使用栈传递的参数会使用R12暂存???),本实验仅仅是一种典型的情况,大家有兴趣可依次思路进行更多实验:
1. 使用不同编译器进行测试 2. 使用不同的优化登记 3. 传递不同类型的参数 4. 硬件浮点单元的传参(使用硬件浮点编译,传递浮点类型参数,如使用S0 - S4传递参数) 5. ..........
3.2.2 返回值实验
本实验较为简单,有兴趣可以自行实验
- 总结:编译器会尽量使用R0-R1进行参数返回,如果不够用,会使用栈传递。
3.2.3 变量实验
略,有兴趣可自行实验。
编译器可使用R4-R11存储局部变量已进行加速,不优化一般存储在栈中,当然我们在使用汇编写函数时所有寄存器器都是可用的,栈也可有自己分配,只有遵守调用者和被调用者规则即可
3.2.4 临时值实验
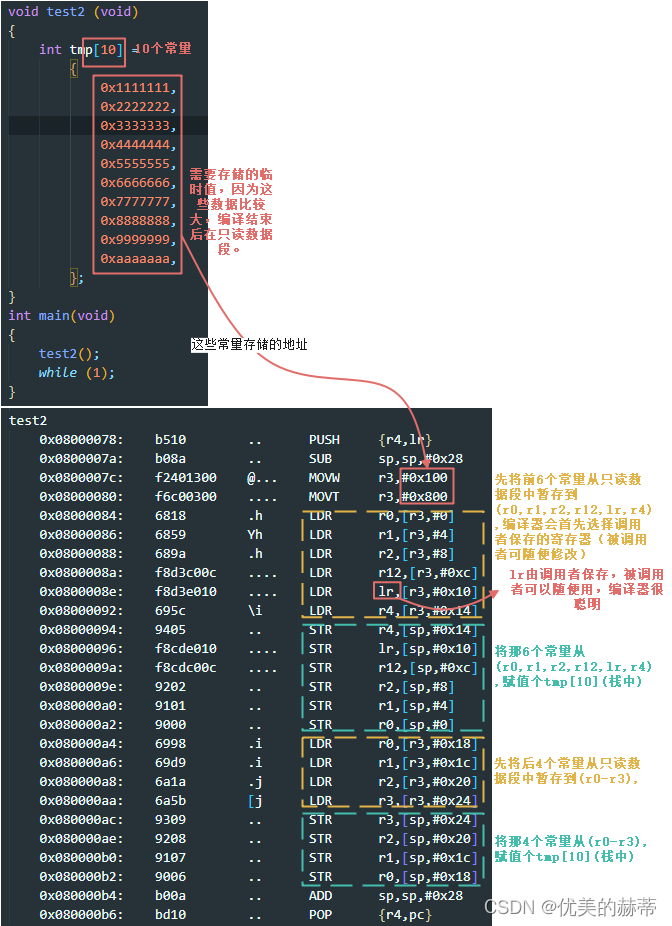
r0-r3都可存储临时值,调用者保存的那几个寄存器都可能会被编译器用来存储临时值,临时值过多时也可使用被调用者保护的寄存器(遵守调用者和被调用者规则)
3.2.5 调用者保护寄存器实验
略,前文进行了一个简单实验,有兴趣可自行实验。
3.2.6 被调用者保护寄存器实验
略,前文进行了一个简单实验,有兴趣可自行实验。
3.2.7 更多实验
。。。。。
4 总结
本文更多是提供一个思路,隐藏了较多细节(要面面俱到的话就不是一篇文章能写清楚了,工作量比较大,若有问题可留言)。














 1848
1848











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









