









http://blog.csdn.net/pipisorry/article/details/44904649
机器学习Machine Learning - Andrew NG courses学习笔记
Large Scale Machine Learning大规模机器学习
{deal with very big data sets with two main ideas.The first is called stochastic gradient descentand the second is called Map Reduce, for viewing with very big data sets}
Learning With Large Datasets大数据集学习
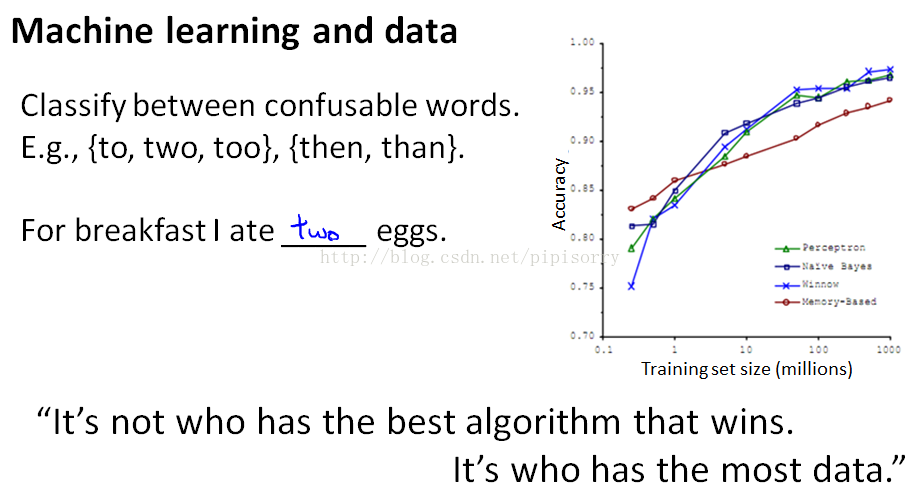
{one of the best ways to get a high performance machine learning system,is if you take a low-bias learning algorithm, and train that on a lot of data}
Note:
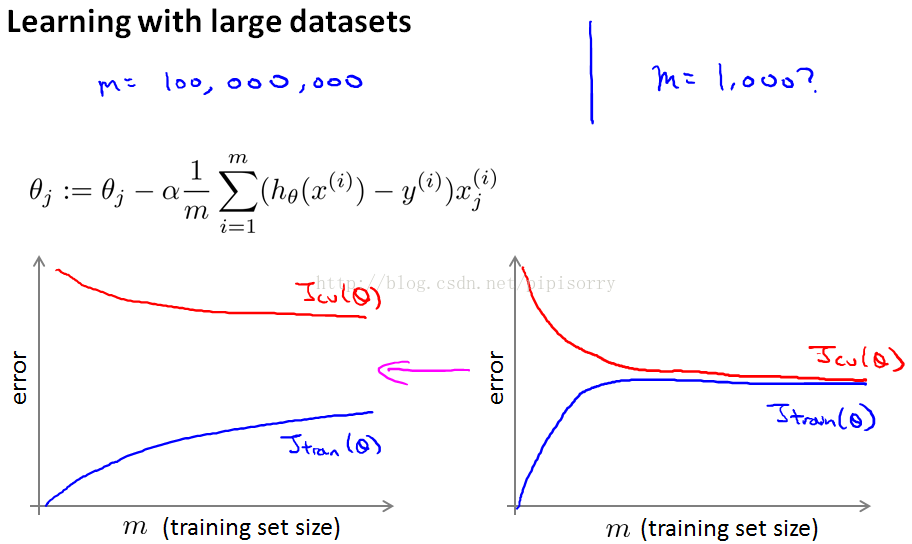
1. Before investing the effort into actually developing and the software needed to train these massive models is often a good sanity check, if training on just a thousand examples might do just as well.It is the usual method ofplotting the learning curves.
2. so if you were to plot the learning curves and if your training objective were to look like theleft,and your cross-validation set objective, Jcv of theta,then this looks like a high-variancelearning algorithm,so thatadding extra training examples would improve performance.
3. The right looks like the classical high-bias learning algorithm.then it seems unlikely that increasing m to a hundred million will do much better and then you'd be just fine sticking to n equals 1000, rather than investing a lot of effort to figure out how the scale of the algorithm.
4. For the right one natural thing to do would be to add extra features,or add extra hidden units to your neural network and so on,so that you end up with a situation closer to that on the left, where maybe this is up to n equals 1000,and this then gives you more confidence that trying to add infrastructure(下部构造) to change the algorithm to use much more than a thousand examples that might actually be a good use of your time.
Stochastic Gradient Descent随机梯度下降
{if we have a very large training set gradient descent becomes a computationally very expensive procedure}
批梯度下降

Note:
1. this particular version of gradient descent is also called Batch gradient descent.And the term Batch refers to the fact that we're looking at all of the training examples at a time.We call it sort of a batch of all of the training examples.
2. The way this algorithm works is you need to read into your computer memory all 300 million records in order to compute this derivative term.You need to stream all of these records through computer because you can't store all your records in computer memory.So you need to read through them and slowly, accumulate the sum in order to compute the derivative.And so it's gonna take a long time in order to get the algorithm to converge.
随机梯度下降
{doesn't need to look at all the training examples in every single iteration,but that needs to look at only a single training example in one iteration}

Note:
1. this cost function term really measures how well is my hypothesis doing on a single example x(i), y(i).So j train is just the average over my m training examples of the cost of my hypothesis on that example x(i), y(i).
2. What Stochastic gradient descent is doing is it is actually scanning through the training examples.And first it's gonna look at my first training example x(1), y(1).we're going to look at the first example and modify the parameters a little bit to fit just the first training example a little bit better.
3. Depending on whether your data already came randomly sorted or whether it came originally sorted in some strange order,in practice this would just speed up the conversions to Stochastic gradient descent just a little bit.
4. Stochastic gradient descent's a lot like descent but rather than wait to sum up these gradient terms over all m training examples,what we're doing is we're taking this gradient term using just one single training example and we're starting to make progress in improving the parameters already, moving the parameters towards the global minimum. rather than needing to scan through all of the training examples
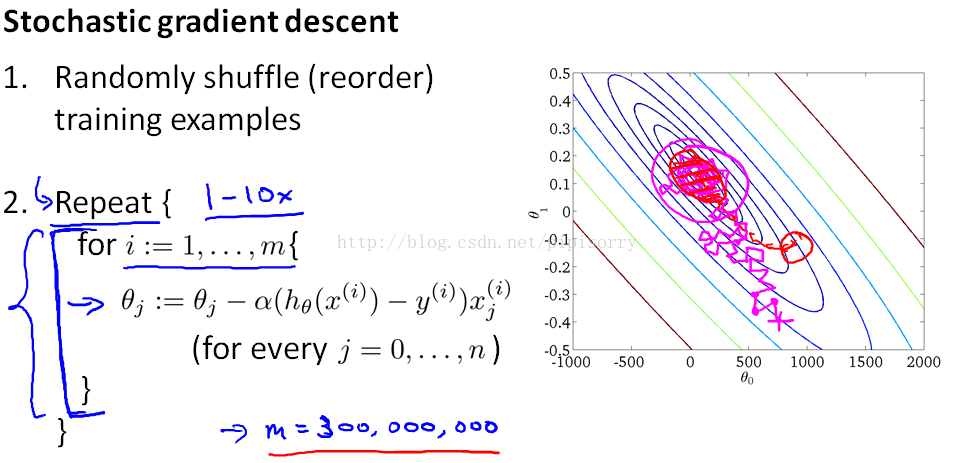
Note:
1. In contrast with Stochastic gradient descent every iteration is going to be much faster because we don't need to sum up over all the training examples.But every iteration is just trying to fit single training example better.
随机梯度下降可能存在的问题
And as you run Stochastic gradient descent, what you find is that it will generally move the parameters in the direction of the global minimum, but not always.And in fact as you run Stochastic gradient descent it doesn't actually converge in the same same sense as Batch gradient descent does and what it ends up doing is wandering around continuously in some region that's in some region close to the global minimum,but it doesn't just get to the global minimum and stay there.But in practice this isn't a problem because so long as the parameters end up in some region there maybe it is pretty close to the global minimum,that will be a pretty good hypothesis for essentially any, most practical purposes. stochastic gradient descent doesn't just converge to the global minimum.随机梯度下降不会刚好在全局最小值处收敛。
随机梯度下降和批梯度下降的对比和选择
最外层循环的次数how many times do we repeat this outer loop?
It's possible that by the time you've taken a single pass through your data set you might already have a perfectly good hypothesis.this inner loop you might need to do only once if m is very, very large. But in general taking anywhere from 1 through 10 passes through your data set, you know, maybe fairly common.But really it depends on the size of your training set.
为什么随机梯度下降比批梯度下降快?
contrast this to Batch gradient descent. With Batch gradient descent, after taking a pass through your entire training set,you would have taken just one single gradient descent steps, and this is why Stochastic gradient descent can be much faster.
这样的话,随机梯度下降最外层循环次数m相比批梯度下降少得多,所以运行更快。
选择随机梯度下降还是批梯度下降?
数据量大的时候使用随机梯度下降,而数据量不那么大的话还是用批梯度下降吧。
Stochastic gradient descent is preferred when you have a large training set size; if the data set is small, then the summation over examples in batch gradient descent is not an issue.
[论文:随机梯度下降(SGD)Tricks:《Stochastic Gradient Descent Tricks》L Bottou (2012) ]
[论文:基于在线学习自适应采样的加速随机梯度下降(AW-SGD): Accelerating Stochastic Gradient Descent via Online Learning to Sample - G Bouchard, T Trouillon, J Perez, A Gaidon (2015) ]
[Notes on Accelerating Stochastic Gradient Descent via Online Learning to Sample]
Mini-Batch Gradient Descent迷你批处理梯度下降
{can work sometimes even a bit faster than stochastic gradient descent}


Note:In particular, Mini-batch gradient descent is likely to outperform Stochastic gradient descent only if you have a goodvectorizedimplementation.by using appropriate vectorization to compute the rest of the terms,you can sometimes partially use the good numerical algebra libraries andparallelizeyour gradient computations over the b examples.比之前两种速度快的原因在于vectorized后的并行计算。
Stochastic Gradient Descent Convergence随机梯度下降的收敛性
{for making sure it's converging and for picking the learning rate alpha}
Checking for convergence

Note:
1. But when you have a massive training set size then you don't want to have to pause your algorithm periodically to compute this cost function.And the whole point of stochastic gradient was that you wanted to start to make progress after looking at just a single example without needing to occasionally scan through your entire training set right in the middle of the algorithm, just to compute things like the cost function of the entire training set.
2. 在用(xi, yi)更新theta之前计算当前(xi, yi)的cost:do this before updating theta becauseif we've just updated theta using example,that it might be doing better on that example than what would be representative.
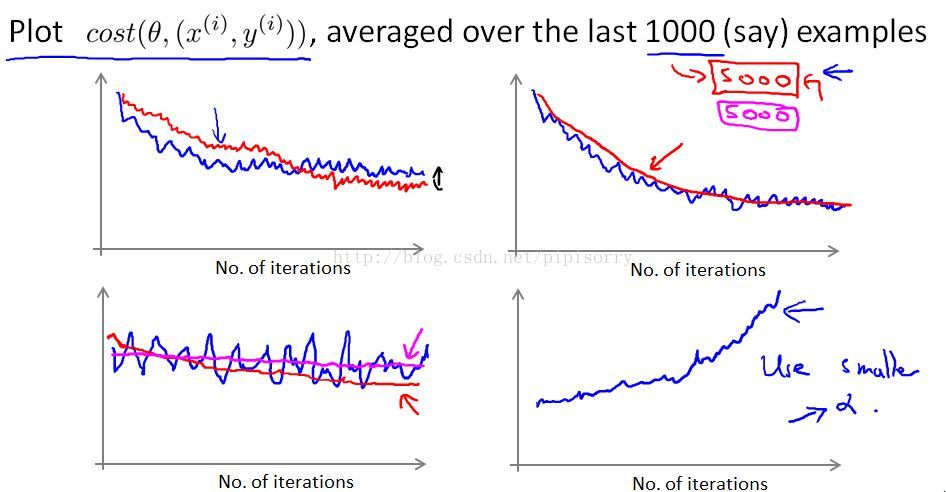
Plot cost averaged over the last 1000 examples, a few examples of what these plots might look like看图修正模型
Note:
1. because these are averaged over just a thousand examples, they are going to be a little bit noisyand so,it may not decrease on every single iteration.
2. 图1the red line: If you want to try using a smaller learning rate, something you might see is that the algorithm may initially learn more slowly so the cost goes down more slowly.But then eventually you have a smaller learning rate is actually possible for the algorithm to end up at a, maybe very slightly better solution.Because stochastic gradient descent doesn't just converge to the global minimum,the parameters will oscillate(振荡) a bit around the global minimum.And so by using a smaller learning rate, you'll end up with smaller oscillations.And sometimes this little difference will be negligible(无用的) and sometimes with a smaller than you can get a slightly better value for the parameters.
3. 图2the red line:And by averaging over, say 5,000 examples instead of 1,000, you might be able to get as moother curvelike this.
4. The disadvantage of averaged over a larger too big of course is that now you get one date point only every 5,000 examples.And so the feedback you get on how well your learning learning algorithm is doing is, sort of, maybe it's more delayed.
5. 图3 averaged over a larger number examples that we've averaged here over 5,000 examples,可能得到两种较平缓的曲线。如果得到的是洋红色水平线,you need to either change the learning rate or change the features or change something else about the algorithm.
6. 图4 if you see a curve is increasing then this is a sign that the algorithm is diverging.And what you really should do isuse as maller value of the learning rate alpha.Decreasing the learning rate
α
means that each iteration of stochastic gradient descent will take a smaller step, thus it will likely converge instead of diverging.
总结:So if the plots looks too noisy, or if it wiggles up and down too much, then try increasing the number of examples you're averaging over so you can see the overall trend in the plot better.And if you see that the errors are actually increasing, the costs are actually increasing, try using a smaller value of alpha.
收敛到最小值examining the issue of the learning rate just a little bit more
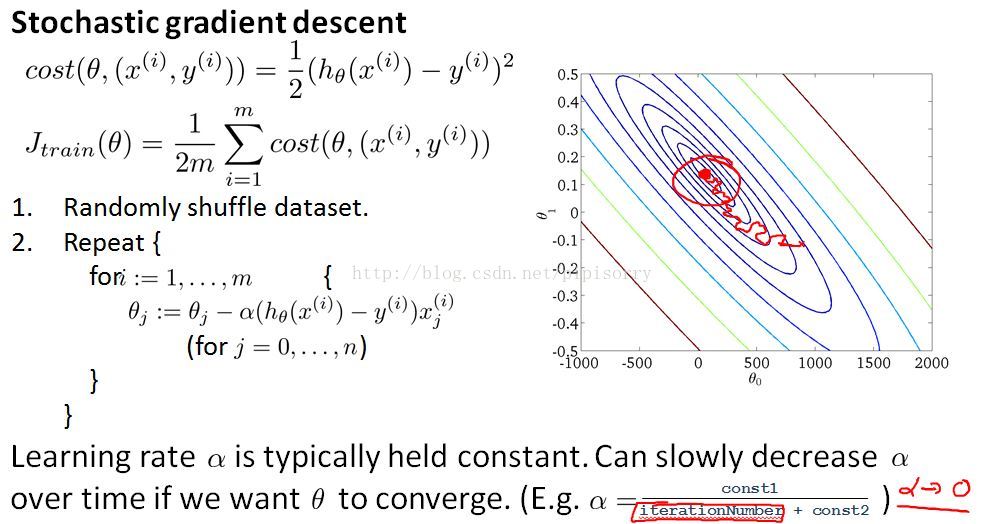
Note:
1. If you want stochastic gradient descent to actually converge to the global minimum,there's one thing which you can do which is you can slowlydecrease the learning rate alpha over time.Anditeration number is the number of iterations you've run of stochastic gradient descent,so it's really the number of training examples you've seen.
2. if you manage to tune the parameters well, then the picture you can get is that the algorithm will actually around towards the minimum, but as it gets closer because you're decreasingthe learning rate the meanderings will get smaller and smaller until it pretty much just to the global minimum.
3. But because of the extra work needed to fiddle with the constants and because frankly usually we're pretty happy with any parameter value that is, you know, pretty close to the global minimum.Typicallythis process of decreasing alpha slowly is usually not done and keeping the learning rate alpha constant.
Online Learning在线学习
Online learning Example:we want a learning algorithm to help us to optimize what is the asking price that we want to offer to our users.
Note:

1. the features x are the origin and destination specified by this user and the price that we happened to offer to them this time around, andyis either one or zero depending one whether or not they chose to use our shipping service.
2. once we get this {x,y} pair, an online learning algorithm then update the parameters theta using just this example x,y, and in particular we wouldupdate my parameters theta.
3. 什么情况下使用在线学习?If you run a major website where have a continuous stream of users coming,online learning algorithm is pretty reasonable .Because of data is essentially free if you have so much data, that data is essentially unlimited then there is no need to look at a training example more than once.Of course if we had only a small number of users then rather than using an online learning algorithm, you might be better off saving away all your data in a fixed training set and then running some algorithm over that .But if you really have a continuous stream of data, then an online learning algorithm can be very effective.
4. one interesting effect of this sort of online learning algorithm is that it canadapt to changing user preferences.And in particular, if over time because of changes in the economy maybe users become less price sensitive and they're willing to pay higher prices.if you start to have new types of users coming to your website.This sort of online learning algorithm can also adapt to changing user preferences and kind of keep track of what your changing population of users may be willing to pay for.And it does that because if your pool of users changes,then these updates to your parameters theta will justslowly adapt your parameters to whatever your latest pool of users looks like.
Another example of a sort of application to which you might apply online learning

Note:
1. we can compute P(y=1|..) for each of the 100 phones and select the 10 phones that the user is most likely to click on.
2. every time a user does a search, we return ten results what that will do is it will actually give us ten x,y pairs,ten training examples every time a user comes to our website because for each of those 10 phones that we chose to show the user we get a feature vector X, and we will also get a value for y, depending on whether or not we clicked on that url or not.
3. each time a user comes you would get ten examples, ten x,y pairs,and then use anonline learning algorithm to update the parameters using essentially 10 steps of gradient descent on these 10 examples, and then you can throw the data away, and if you really have a continuous stream of users coming to your website, this would be a pretty reasonable way to learn parameters for your algorithm so as to show the ten phones to your users.
4. 更通俗点的理解就是:假设y = theta0 + theta1*x1 + theta2*x2, 每次来一个用户,输入查询系统得到10个相似度feature x1,x2(x的内涵不变,计算方法不变),同时可以得到相应的10个点击与否y,用这10个example去修正theta的值,可能说是修改theta1大一点,这样feature x1对点击与否决定性作用更大。
5. any of these problems could also have been formulated as a standard machine learning problem, where you have a fixed training set. you can run your website for a few days and then save away a fixed training set, and run a learning algorithm on that.But these are the actual sorts of problems, where you do see large companies get so much data, that there's really maybe no need to save away a fixed training set, but instead you can use an online learning algorithm to just learn continuously from the data that users are generating on your website.
6. the online learning algorithm is very similar to schotastic gradient descentalgorithm, only instead of scanning through a fixed training set, we're instead getting one example from a user,learning from that example, then discarding it and moving on.
7. one advantage of online learning is also that if you have a changing pool of users, (disadvantage)or if the things you're trying to predict are slowly changing like your user taste is slowly changing, the online learning algorithm can slowly adapt your learned hypothesis to whatever the latest sets of user behaviors are like as well.
Map Reduce and Data Parallelism映射-规约和数据并行
{be able to scale learning algorithms to even far larger problems than is possible using stochastic gradient descent}
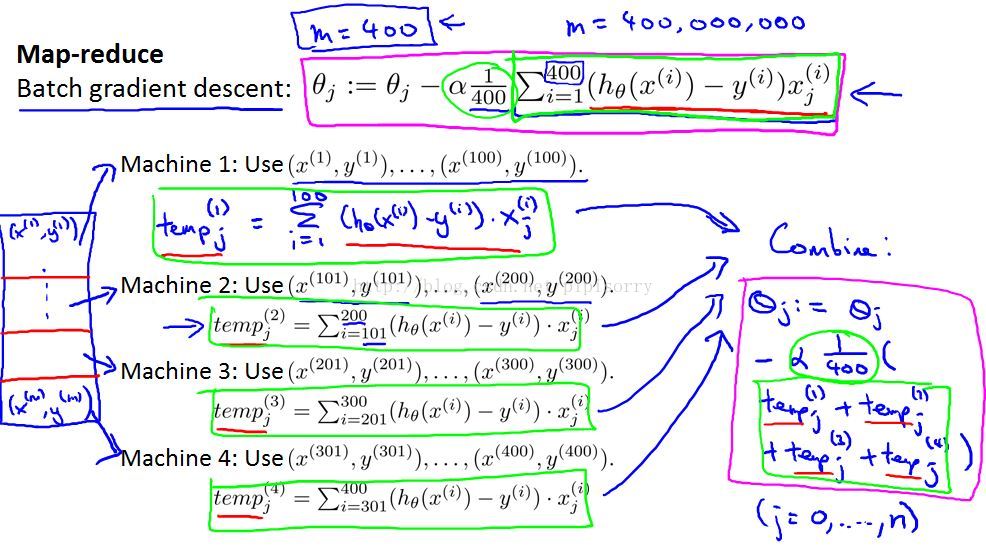
Note:
1. the map reduce idea is due to two researchers, Jeff Dean and Sanjay Gimawat.Jeff Dean,built a large fraction of the architectural infrastructure that all of Google runs on today.
2. split this training set in to different subsets.assume for this example that I have 4 computers to run in parallel on my training set.
3. map-reduce不能用于随机梯度下降。Since stochastic gradient descent processes one example at a time and updates the parameter values after each, it cannot be easily parallelized.
The general picture of the MapReduce
Note:

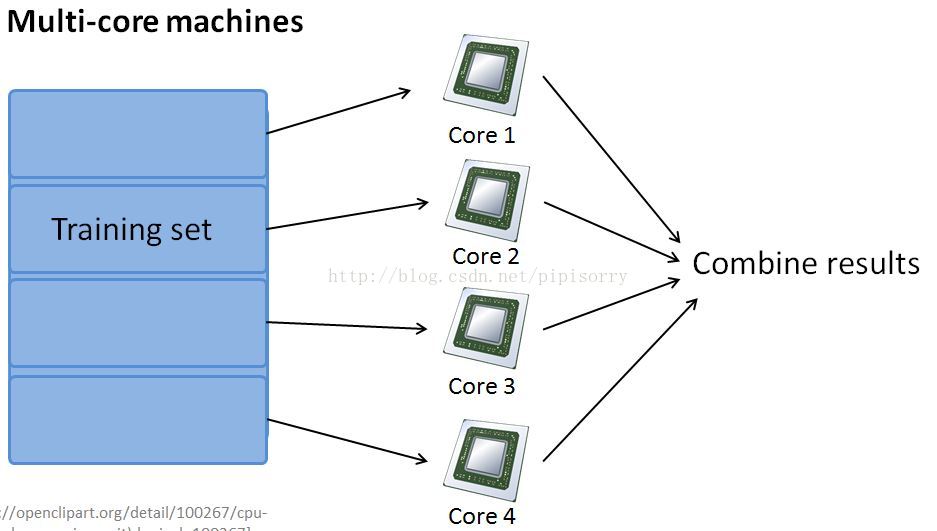
1. if there were no network latencies and no costs of the network communications to send the data back and forth, you can potentially get up to a4x speed up.
2. if you have just a single computer which has multiple processing cores,MapReduce can also be applicable.And so network latency becomes much less of an issue compared to if you were using this to over different computers within the data sensor.
3. one last caveat(预告) on parallelizing within a multi-core machine:It turns out that the sumnumerical linear algebra libraries that can automatically parallelize their linear algebra operations across multiple cores within the machine.If you're using one of those libraries and have a very good vectorizing implementation of the learning algorithm.Sometimes you can just implement you standard learning algorithm in a vectorized fashion and not worry about parallelization.So you don't need to implement Map-reduce.
4. some good open source implementations of MapReduce,called Hadoop and using either your own implementation or using someone else's open source implementation, you can use these ideas to parallelize learning algorithms and get them to run on much larger data sets.
Note:

1. the centralized server can sum these things up and get the overall cost function and get the overall partial derivative,which you can then pass through the advanced optimization algorithm.
2. In order to parellelize a learning algorithm using map-reduce, the first stepis to figure out how to express the main work done by the algorithm as computing sums of functions of training examples.In the reduce step of map-reduce, we sum together the results computed by many computers on the training data.
[用MapReduce框架解决问题的例子]
Reviews:
from:http://blog.csdn.net/pipisorry/article/details/44904649
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









