







11.1 试编程实现Relief算法,并考察其在西瓜数据集3.0上的运行结果。
本题采用Relief算法处理二分类任务,虽然书上只要求对连续属性归一化,但我将离散属性的值转化为了1,2,3,如果不对离散属性归一化,显然在查找近邻时连续属性不能有效发挥作用,因此需要将数据的离散属性和连续属性都进行归一化。另外,在计算连续属性的相关统计量时,本题是二元分类,因此可以对书上公式11.3进行化简,得到下式,可稍微简化计算:
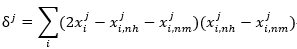
显然,本题主要分为三步:1、数据归一化;2、求取各点近邻near-hit和near-miss;3、求得相关统计量。
由输出结果可见,分类能力最强的属性是纹理,其次是根蒂,……很明显,与其他人用未归一化离散属性的结果有所差异,这也说明此方法采用距离得到近邻来计算统计量,在维数较高,数据复杂时的效果可能不是太好。
代码如下:
# -*- coding: utf-8 -*-
# 特征选择方法:Relief
import numpy as np
label = {0:'色泽', 1:'根蒂', 2:'敲声', 3:'纹理', 4:'脐部', 5:'触感', 6:'密度', 7:'含糖率'}
D = np.array([
[1, 1, 1, 1, 1, 1, 0.697, 0.460, 1],
[2,  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









