







4.4 试编程实现基于基尼指数进行划分选择的决策树算法,为表4.2中数据生成预剪枝、后剪枝决策树,并与未剪枝决策树进行比较。
本题未剪枝决策树与4.3题基本一致,同时,由于表4.2数据没有连续属性,因此本题的代码不能处理具有连续属性的数据XD。
事实上,在本题用基尼指数与用基于信息增益的效果是一样的,但由于多个变量可能同时达到最小基尼指数,因此我的代码结果和成图里面的“脐部=凹陷”这一节点采用的是根蒂进行划分(根蒂、色泽同时都是最优属性),这样一来,这个节点对应的验证集精度为1,无论预剪枝还是后剪枝都不能把它剪掉。
这道题的基尼指数我先进行了推导化简,在只有2类的情况下,Gini_ index(D,a)等价于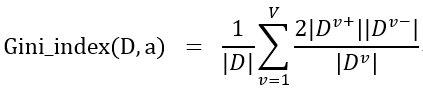
本题的未剪枝、预剪枝、后剪枝和生成树状结构都较多使用了递归,具体代码与决策树效果如下:
# -*- coding: utf-8 -*-
# exercise 4.4: 基于基尼指数的决策树算法,采用未剪枝,预剪枝,后剪枝处理(无连续属性)
import numpy as np
import igraph as ig
from collections import Counter
import random, copy
def all_class(D): # 判断D中类的个数
return len(np.unique(D[:,-1])) # np.unique用以生成具有不重复元素的数组
def diff_in_attr(D,A_code): # 判断D中样本在当前A_code上是否存在属性取值不同,即各属性只有一个取值
cond = False
for i in A_code: # continuous args are excluded
if len(np.unique(D[:,i])) != 1:
cond = True
break
return cond
def major_class(D): # 票选出D中样本数最多的类
# 本书所给图4.6是利用信息增益划分得到的,在进行预剪枝时,将脐部=稍凹\
# 判定为好瓜和坏瓜具有同样验证集精度和泛化误差,但若直接用22行进行计算\
# 取第一项,则没有考虑到训练集含偶数个例子时,可能出现上述情况,为了和书\
# 上一致,强行让这种情况下的分类取为1,即好瓜
c = Counter(D[:,-1]).most_common()
if len(c) == 1:
return c[0][0]
elif c[0][1] == c[1][1]:
return 1
else:
return c[0][0]
def min_gini(D,A_code):
N = len(D) # 当前样本数
dict_class = {} # 用字典保存类及其所在样本,键为类型,值为类型所含样本
for i in range(N):
if D[i,-1] not in dict_class.keys(): # 为字典添加新类
dict_class[D[i,-1]] = []
dict_class[D[i,-1]].append(int(D[i,0]))
else:
dict_class[D[i,-1]].append(int(D[i,0]))
Gini_D_A = {} # 用字典保存在某一属性下的属性值及其所在样本,键为属性取值,值为对应样本
for a in A_code:
# A中的离散属性,在后期的迭代中,属性a可能会变得不连续
dict_attr = {}
for i in range(N):
if D[i,a] not in dict_attr.keys(): # 为字典添加新的属性取值
dict_attr[D[i,a]] = []
dict_attr[D[i,a]].append(int(D[i,0]))
else:
dict_attr[D[i,a]].append(int(D[i,0]))
# 对Gini_index(D,a)变形发现,在只有好瓜和坏瓜这两类时,基尼指数最小等价于
# sigma(v=1到V)求和:(|Dv+| * |Dv-|) / |Dv|最小
Gini_D_A[(a,)] = 0
for av,v in dict_attr.items():
m = len(v) # m为当前属性取值的样本总数,如A_a0包含的样本总数
x2 = len(set(v) & set(dict_class[1.0]))
x1 = m - x2
Gini_D_A[(a,)] += x1 * x2 / m
Gini_D_A_list = sorted(Gini_D_A.items(),key=lambda a: a[1])
best = Gini_D_A_list[0][0]
dict 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7515
7515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









