







第一次这样写作业,摸索了很久都没有头绪,后来才明白怎么去做作业。(当然还是不会)
1.仔细阅读PDF,这里老师会给出一系列的要求
2.去完成要求中需要补充的代码(公式)到各个函数里面
3.完成后测验看能不能得到相应的图形
4.提交
前言(译):针对这次作业而言,是构建一个逻辑回归模型,判断一个大学生是否被录取;(故1为录取,0为没有录取)
有历史的数据作为训练集,使用逻辑回归判断学生在两个考试中的分数为基础判断录取概率;
大框架在ex2.m中;
1.1 Visualizing the data (可视化数据)

其中黑色的点代表符合要求的,黄色点代表不符合要求的,未来需要拟合出一条曲线来让机器判断该生是否应该被录取(大概猜测)
1.2.1 Warmup exercise: sigmoid function
顾名思义:热身练习,即编写sigmoid函数,在文件sigmoid.m中去写;
回忆:逻辑回归的函数是从一元线性回归引申的 hθ(x) =g(θTx);
要求:实现sigmoid函数,g(z) = 1/(1+e^-z)
PS:在Octave里面传参都是以矩阵的形式,这个在ex2的PDF有说, 比如 sigmoid([1])就是个0维矩阵,传参进去便会得到答案;
Hx = sigmoid(X * theta);
J = 1/m * (-y'*log(Hx)-(1-y')*log(1-Hx));
grad = 1/m * ((Hx - y)' * X); 补充:sigmoid函数,为了实现logistic回归分类器,我们可以在每个特征上乘以一个回归系数,然后把所有的结果值相加,将这个总和结果代入sigmoid函数中,进而得到一个范围在0~1之间的数值。任何大于0.5的数据被分入1类,小于0.5的数据被归入0类。所以,logistic回归也可以被看成是一种概率估计。就和分段函数一样;

1.2.2 Cost function and gradient (代价函数和梯度)
这一段是让完成代价函数和梯度公式,并将其表示在costfunction.m中,
其中公式老师已经很友好的给出了:
这里需要思维转换一下,先给出几个公式
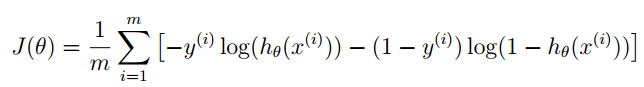
在这个公式中我们需要先表示出来 hθ(x) ; 又在前面 hθ(x) = g(θTx); 且 g(θTx) 即 sigmoid( θTx )
即 hθ(x) = sigmoid( θTx ) ;
在这里没有累加,所以改用矩阵乘法的原理就可以实现累加
同理,梯度函数也是用矩阵乘法实现
Hx = sigmoid(X * theta);
J = 1/m * (-y'*log(Hx)-(1-y')*log(1-Hx));
grad = 1/m * ((Hx - y)' * X);1.2.3 Learning parameters usingfminunc
这里讲解的是调用函数,因为我并不懂,所以转载一下;出处:http://blog.csdn.net/love_tea_cat/article/details/26616639
转载内容:稍微解释一下这段代码,第一句话是在设置fminunc的一些参数,把'GradObj'这个参数设置为on,这样就告诉了fminunc函数要同时返回具体的代价函数的值和梯度,也让fminunc函数在寻找最小化参数的时候可以使用梯度;后面把'MaxIter'参数设置为400,这样fminunc函数最多迭代400次。第二句话就是在具体调用fminunc函数,@(t)可以认为是将我们的代价函数作为一个参数传递了进去,t在代价函数中的位置就是theta的位置。

因此我们只需要定义好自己的代价函数以及max iteration次数,再调用这个函数,就能找到适用于我们的最佳解theta以及最小的cost
最后fminunc函数返回的参数构成的直线分割的效果如下:

然后在运行完后,在命令行页面会看到如下表示:

所表示的分别是:(这里的theta(0)指的是把theta初始值设为0,其实设成任意都行,一般为0)
2、初始条件下的梯度值
3、theta下的最小cost
4、三个参数(偏执值,第一门成绩,第二门成绩)
通过样例 ,第一门45,第二门85通过的概率为0.77,这句话的实际操作是:
这里的1实际上是给矩阵多加了一项偏执值
因为对于一维而言,边界函数 y = kx + b , 这里的b系数是1 ;
sigmoid([1 45 85] * [-25.16127 0.20623 0.20147]') = 0.77629 sigmoid([1 45 85] * theta) = 0.77629 下面的1.24就是如果把分界线定在0.5,那么大于等于就是1,小于就是0,于是这个同学是可以被录取的;
1.2.4 Evaluating logistic regression找到那条最好的划分曲线,那么我们将如何来评价我们找到的这条曲线的好坏呢?一种方法就是用这条曲线来对所有训练集中的元组进行判断,统计其正确率,于是我们在predict.m中添加如下代码:
Hx = sigmoid(X * theta);
for iter = 1:m
if Hx(iter) >= 0.5
p(iter) = 1;
else
p(iter) = 0;
end;
end;
至此第一个练习就结束了
2 Regularized logistic regression
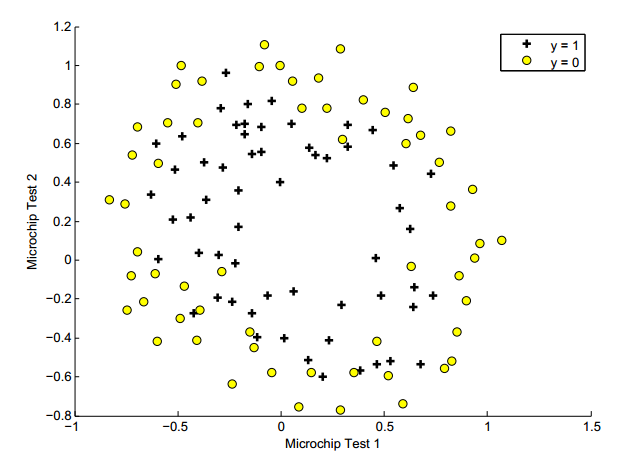
2.2 Feature mapping
这次的图不能再用直线拟合,根据形状可知拟合形态可能是一个闭合曲线;
所以在课程中我们得知,如果在直线不能完成的情况就得增加参数来提高拟合度,比如x1*x1 + x2*x2 .等, 但是同时带来的缺陷就是过度匹配
而解决这一方法的方案就需要写在 mapFeature
function out = mapFeature(X1, X2)
% MAPFEATURE Feature mapping function to polynomial features
%
% MAPFEATURE(X1, X2) maps the two input features
% to quadratic features used in the regularization exercise.
%
% Returns a new feature array with more features, comprising of
% X1, X2, X1.^2, X2.^2, X1*X2, X1*X2.^2, etc..
%
% Inputs X1, X2 must be the same size
%
degree = 6;
out = ones(size(X1(:,1)));
for i = 1:degree
for j = 0:i
out(:, end+1) = (X1.^(i-j)).*(X2.^j);
end
end
end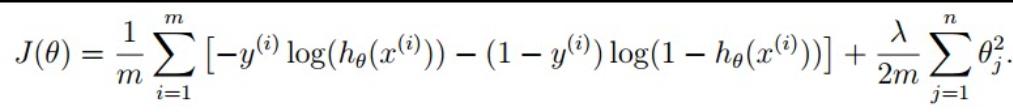
按照之前在正规化中的介绍,将会在代价函数中添加参数本身大小的影响,从而使得参数的大小都比较接近0,修改过的公式在视频和pgf都已列出,我们需要做的就是用Matlab语言实现之。代码如下(costFunctionReg.m):
Hx = sigmoid(X * theta);
J = 1/m * (-y'*log(Hx)-(1-y')*log(1-Hx)) + lambda/(2*m) * (theta(2:end)' * theta(2:end));
grad = 1/m * ((Hx - y)' * X) + lambda/m * theta';
grad(1) = grad(1) - lambda/m * theta(1);
















 4283
4283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











