








详解python实现FP-TREE进行关联规则挖掘(带有FP树显示功能)附源代码下载(2)
fptree进行数据挖掘的第一步是生成fptree,具体的生成过程大家在网上和书上都能找到详尽的解释,这里我就不再赘述了。
不过大家可能会产生一个问题:为什么要对每一条样本记录按照其中特征项支持度从大到小排序一下,才能生成fp树呢?
请看下图:
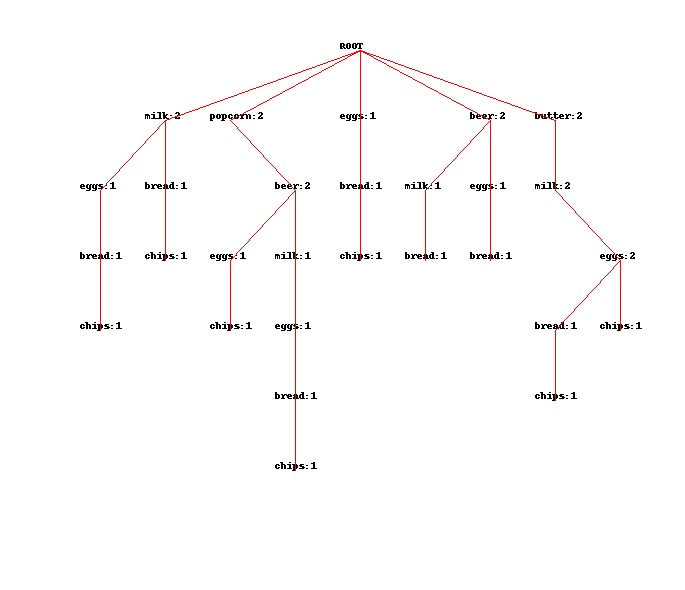
这张图是将我的每一条样本记录按照其中特征项支持度从小到大排序后生成的FP树,是不是很臃肿?
所以从大到小的排序目的就在于给FP树瘦身,降低挖掘时的运算量和FP树占用的内存空间。
在源代码中,生成fp树由两个类负责,一个treebuilder(根据样本直接生成树),另一个是cpbtreebuilider(根据条件模式基来生成树)
class treebuilder:
def __init__(self,items,facts):
self.items=items #特征项
self.facts=facts #样本记录列表
self.itemcount=self.getitemcount() #{特征项:支持度}
self.itemtable=self.getitemtable() #头表
self.tree=self.growtree() #树
树的类型定义在fpnode 类中,可以调用其中的show方法显示树(前提是PIL库安装)
示例:
import sample
import fptreemining
import treebuilder
#显示树
root=treebuilder.treebuilder(items=sample.items,facts=sample.sample)
root.tree.show()转载请注明出处:http://blog.csdn.net/rav009/article/details/8976243















 1255
1255











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











