







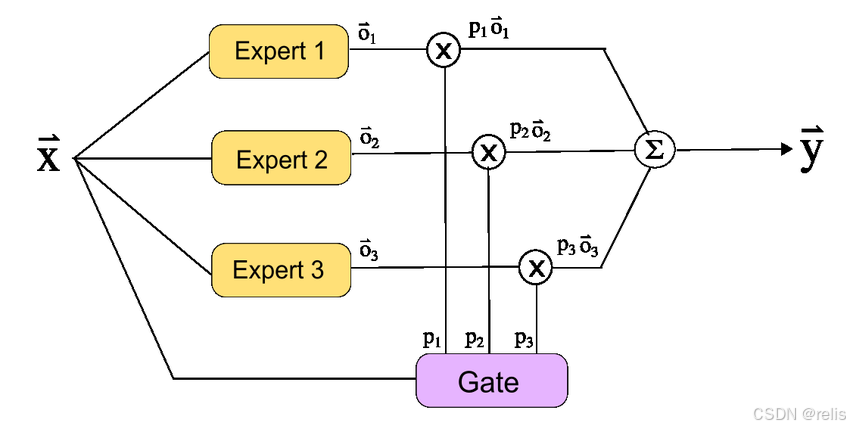
专家混合模型怎么工作的?
MoE 模型通过指定多个“专家”来处理数据,每个专家在更大的神经网络中都有自己的子网络,并训练门控网络(或路由器)以仅激活最适合给定输入的特定专家。
MoE 方法的主要优点是,通过强制稀疏性,而不是为每个输入标记激活整个神经网络,可以增加模型容量,同时基本保持计算成本不变。
在架构层面,这是通过用稀疏 MoE 层(或块)替换传统的密集前馈网络 (FFN) 层来实现的。在神经网络术语中,“块”是指执行特定功能的重复结构元素。在稀疏 MoE 模型 (SMoE) 中,这些专家块可以是单层、独立的 FFN,甚至是嵌套的 MoE。
例如,在 Mistral 的Mixtral 8x7B语言模型中,每一层由 8 个前馈块(即专家)组成,每个专家都有 70 亿个参数。对于每个标记,在每一层,路由器网络都会从这八个专家中选择两个来处理数据。然后,它将这两个专家的输出组合起来,并将结果传递给下一层。路由器在给定层选择的特定专家可能与上一层或下一层选择的专家不同。
MoE 参数计数
SMoE 可能完全由稀疏的 MoE 层组成,但许多 MoE 模型架构都包含稀疏和密集块。Mixtral 也是如此,其中负责模型自注意力机制的块由所有 8 位专家共享。实际上,这使得“ 8x7B ”这样的名称可能具有误导性:由于模型的许多参数由每个 70 亿参数专家子网络共享,因此 Mixtral 总共拥有约 470 亿个参数,而不是人们可能通过简单乘法假设的 560 亿个参数。
这个总体参数数量通常被称为稀疏参数数量,通常可以理解为模型容量的度量。实际用于处理单个 token 的参数数量(因为它会通过一些专家块并绕过其他块)称为活动参数数量,可以理解为模型计算成本的度量。虽然输入到 Mixtral 的每个 token 都可以访问 467 亿个参数,但只有 129 亿个活动参数用于处理给定的示例。
了解参数数量的最佳利用是理解 MoE 模型优势的关键。例如,Mixtral 在大多数基准测试中都优于 Meta 的Llama 2的 700 亿参数变体,速度更快,尽管总参数数量少了三分之一,并且在推理时使用的活动参数不到 20% 。
然而,值得注意的是,稀疏 MoE 的整体参数数量与计算要求并非完全无关。尽管在推理过程中仅使用参数的子集,但模型的所有参数都必须加载到内存中,这意味着 SMoE 在大多数情况下享有的计算效率并不适用于其 RAM/VRAM 要求。
稀疏性
MoE 概念(和效率)的关键在于,在任何给定时间只有稀疏层中的部分专家(以及参数)会被激活,从而减少主动计算要求。
尽管条件计算早已被提出作为一种理论手段,将计算需求与增加的模型容量分离开来,但直到 Shazeer 等人于 2017 年发表论文“超大规模神经网络:稀疏门控混合专家层”时,其成功执行所面临的算法和性能挑战才得以克服。
稀疏层相对于密集层的优势在处理高维数据时最为明显,因为高维数据的模式和依赖关系通常很复杂且呈非线性:例如,在需要模型处理长文本序列的 NLP 任务中,每个单词通常仅与该序列中的一小部分其他单词相关。这使得 SMoE 成为 LLM 领域中一个潜力巨大的领域,经过良好校准的 MoE 模型可以享受稀疏性的好处而不会牺牲性能。稀疏门控 MoE 模型也已成功应用于计算机视觉任务,5 6并且仍然是该领域的一个活跃研究领域。
这种稀疏性是通过条件计算实现的:响应特定输入动态激活特定参数。因此,门控网络(或“路由器”)的有效设计对于 MoE 模型的成功至关重要,因为门控网络可以强制执行条件计算。
路由
可以使用多种门控机制来选择在特定情况下使用哪些专家。正确的门控功能对于模型性能至关重要,因为糟糕的路由策略可能会导致某些专家训练不足或过于专业化,从而降低整个网络的效率。
传统 MoE 设置中的典型门控机制(在 Shazeer 的开创性论文中介绍)使用softmax函数:对于每个专家,路由器会根据每个示例预测该专家产生给定输入的最佳输出的概率值(基于该专家与当前参数的连接的权重);路由器不会计算所有专家的输出,而是仅计算该示例的前k 名专家的输出(它预测的输出)。如前所述,Mixtral 使用这种经典的前 k 名路由策略:具体来说,它使用前 2 名路由(即 k=2),从总共 8 名专家中选择最好的 2 名。
Fedus 等人在 2021 年发表的颇具影响力的论文《Switch Transformers:以简单高效的稀疏性扩展至万亿参数模型》中,将 top-k 路由发挥到了极致:与 Google 的 T5 LLM 合作,用 128 位专家替换了模型的 FFN 层,并实现了 k=1,也称为“硬路由”。即使将模型扩展到一万亿参数,此设置也能将预训练速度提高 400% 。
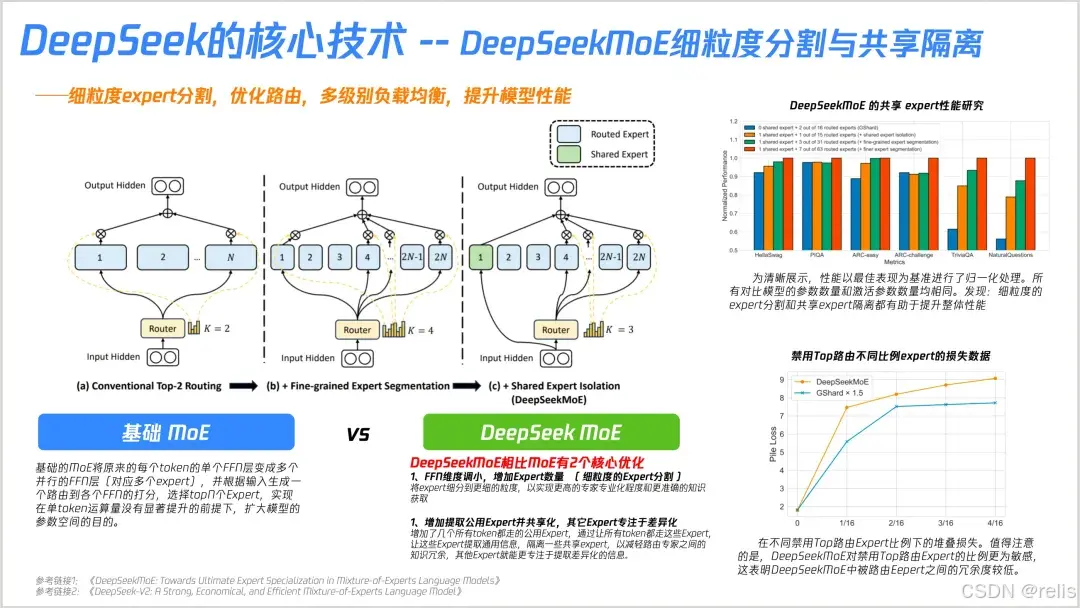
DeepSeek MoE VS 基础MoE


















 83
83

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











