






<script type="text/javascript">
</script> <script type="text/javascript" src="http://pagead2.googlesyndication.com/pagead/show_ads.js"> </script>
equalizer的0.4版本中,图元数据的管理改用kd-tree实现,而不是原来的松散八叉树。
事实上,kd-tree与八叉树(octree)都是二叉树(BSP)的变种。在三维图形应用,诸如碰撞检测,遮挡剔除以及光线追踪等领域,都可以通过对三维场景中的图元数据进行层次化细分,从而加速数据的遍历与检测过程。
相比之下,kd-tree的划分方法既有二叉树的结构简单的特点,又因为不要求对空间进行等分,所以相比八叉树能够更紧密的包围图元,所以正在被越来越多的人们关注。比如Stanford大学的人这几年就在研究如何利用kd-tree结构来优化运动场景内的三维空间数据的管理,从而在GPU内实现实时的光线追踪渲染。
回过头来看equalizer中的eqPly实例,关于eqPly应用的结构及其0.3版本时采用的松散八叉树结构,可以参考我前面的文章《针对equalizer(v0.3)中eqPly的分析 》,这里主要探讨0.4版本后的数据结构。
在新的版本中,从Ply格式的模型文件中加载的顶点和三角形数据都以向量的形式存储在mesh::VertexData中,用向量管理数据目的有三个,一方面可以供其它对象通过向量索引获得所需的数据,另一方面向量数据可以简单的与GPU中的VBO进行映射,当然还有最重要的一点,就是可以利用STL中的算法对数据进行排序,从而实现kd-tree划分。
加载模型时,首先由VertexBufferRoot从PLY模型中读取原始的图元数据,放置在VertexData中,作为VertexBufferBase的子类,VertexBufferRoot调用其setupTree函数开始构造kd-tree。从VertexBufferNode::setupTree中可以知道,对一个节点而言,在对节点内的顶点数据进行排序后,根据垂直于坐标轴的一个面对节点内的顶点进行等分,这样逐级进行划分,直到节点内的顶点数量少于预先设定的LEAF_SIZE,则该节点为叶节点,这时按顺序将叶节点内的顶点从VertexData内复制到专门用于保存kd-tree内顶点数据的VertexBufferData对象内。
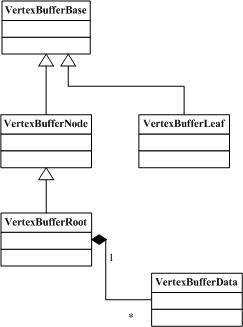
VertexBufferData对象是VertexBufferRoot类的成员,也是渲染过程中真正使用的顶点数据来源。 VertexBufferRoot是VertexBufferNode的子类,它与VertexBufferLeaf都是接口类 VertexBufferBase的子类。它们之间的关系如下图可见:
渲染模型时,首先构建一个用于遍历kd-tree的向量,然后将kd-tree的根节点(VertexBufferRoot)放入该向量中,通过对节点的包围盒与视锥体的相交性检测,可以有三种情况,即完全位于视锥体内,部分位于视锥体内和完全位于视锥体外。不在视锥体内的,根本不必作进一步处理了,完全位于视锥体内的,调用该节点的渲染函数,并沿节点的树状结构逐级遍历到各个页节点进行几何图元的绘制;而对于部分位于视锥体内的节点,则需要对它的子节点分别进行进一步的遍历检测。具体的操作过程可以参考eqPly示例中的eqPly::Channel::_drawModel函数。
当然,上述采用kd-tree的图形数据加速结构,对于小场景来说价值不大,eqPly中采用kd-tree的目的一方面是由于Equalizer是用于并行渲染框架,它需要将计算负载分配给多个计算节点完成,所以每个节点通常只渲染一个非常复杂的场景中的一小块,这时kd-tree就可有效的裁减掉节点内不渲染的图形元素,从而可以提高计算效率。此外,就像我前面提到的,kd-tree在当前的运动场景光线追踪渲染领域很受重视,也许Equalizer的开发者也在考虑对这些全局光照技术的支持,毕竟这也是充分发挥并行渲染技术优势的很好的方向。
参考资料
1.实时计算机图形学,第9章
2.Physically-based image synthesis: From Theory to Implementation, 第四章 <script type="text/javascript"> </script> <script type="text/javascript" src="http://pagead2.googlesyndication.com/pagead/show_ads.js"> </script>
事实上,kd-tree与八叉树(octree)都是二叉树(BSP)的变种。在三维图形应用,诸如碰撞检测,遮挡剔除以及光线追踪等领域,都可以通过对三维场景中的图元数据进行层次化细分,从而加速数据的遍历与检测过程。
- 二叉树指用一个平面对场景的包围盒进行分割,然后将几何图元分别放置在两个子块中,由于二叉树中采用的分割平面可以是任意的,所以分割后的子块常常是不规则的。
- kd-tree的划分中将分割平面限定为必须与某个坐标轴垂直;
- 而八叉树则在每次分割时采用三个正交平面对空间进行等分。
相比之下,kd-tree的划分方法既有二叉树的结构简单的特点,又因为不要求对空间进行等分,所以相比八叉树能够更紧密的包围图元,所以正在被越来越多的人们关注。比如Stanford大学的人这几年就在研究如何利用kd-tree结构来优化运动场景内的三维空间数据的管理,从而在GPU内实现实时的光线追踪渲染。
回过头来看equalizer中的eqPly实例,关于eqPly应用的结构及其0.3版本时采用的松散八叉树结构,可以参考我前面的文章《针对equalizer(v0.3)中eqPly的分析 》,这里主要探讨0.4版本后的数据结构。
在新的版本中,从Ply格式的模型文件中加载的顶点和三角形数据都以向量的形式存储在mesh::VertexData中,用向量管理数据目的有三个,一方面可以供其它对象通过向量索引获得所需的数据,另一方面向量数据可以简单的与GPU中的VBO进行映射,当然还有最重要的一点,就是可以利用STL中的算法对数据进行排序,从而实现kd-tree划分。
加载模型时,首先由VertexBufferRoot从PLY模型中读取原始的图元数据,放置在VertexData中,作为VertexBufferBase的子类,VertexBufferRoot调用其setupTree函数开始构造kd-tree。从VertexBufferNode::setupTree中可以知道,对一个节点而言,在对节点内的顶点数据进行排序后,根据垂直于坐标轴的一个面对节点内的顶点进行等分,这样逐级进行划分,直到节点内的顶点数量少于预先设定的LEAF_SIZE,则该节点为叶节点,这时按顺序将叶节点内的顶点从VertexData内复制到专门用于保存kd-tree内顶点数据的VertexBufferData对象内。
VertexBufferData对象是VertexBufferRoot类的成员,也是渲染过程中真正使用的顶点数据来源。 VertexBufferRoot是VertexBufferNode的子类,它与VertexBufferLeaf都是接口类 VertexBufferBase的子类。它们之间的关系如下图可见:
渲染模型时,首先构建一个用于遍历kd-tree的向量,然后将kd-tree的根节点(VertexBufferRoot)放入该向量中,通过对节点的包围盒与视锥体的相交性检测,可以有三种情况,即完全位于视锥体内,部分位于视锥体内和完全位于视锥体外。不在视锥体内的,根本不必作进一步处理了,完全位于视锥体内的,调用该节点的渲染函数,并沿节点的树状结构逐级遍历到各个页节点进行几何图元的绘制;而对于部分位于视锥体内的节点,则需要对它的子节点分别进行进一步的遍历检测。具体的操作过程可以参考eqPly示例中的eqPly::Channel::_drawModel函数。
当然,上述采用kd-tree的图形数据加速结构,对于小场景来说价值不大,eqPly中采用kd-tree的目的一方面是由于Equalizer是用于并行渲染框架,它需要将计算负载分配给多个计算节点完成,所以每个节点通常只渲染一个非常复杂的场景中的一小块,这时kd-tree就可有效的裁减掉节点内不渲染的图形元素,从而可以提高计算效率。此外,就像我前面提到的,kd-tree在当前的运动场景光线追踪渲染领域很受重视,也许Equalizer的开发者也在考虑对这些全局光照技术的支持,毕竟这也是充分发挥并行渲染技术优势的很好的方向。
参考资料
1.实时计算机图形学,第9章
2.Physically-based image synthesis: From Theory to Implementation, 第四章 <script type="text/javascript"> </script> <script type="text/javascript" src="http://pagead2.googlesyndication.com/pagead/show_ads.js"> </script>














 6137
6137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









