







集成学习系列:
Random Forest
1 - Random Forest Algorithm
这篇主要讲述机器学习中的随机森林算法相关的知识。首先回顾一下我们在前几篇博文中提到的两个模型, Bagging Bagging 和 Decision Tree Decision Tree 。
1.1 - 回顾bagging和decision tree
Bagging B a g g i n g 算法的主要过程是通过 bootstrap b o o t s t r a p 机制从原始的资料 D D 中得到不同的大小为 N′ N ′ 的资料 D~t D ~ t ,将这些资料喂给 base algorithm b a s e a l g o r i t h m ,这里记作算法 A A ,得到一个 gt g t 。最后使用 uniform u n i f o r m 的方式将这些 gt g t 融合起来作为算法最后得到的模型 G G 。
Bagging算法
1.request size N′ data D~t by bootstrapping with D
1.
r
e
q
u
e
s
t
s
i
z
e
N
′
d
a
t
a
D
~
t
b
y
b
o
o
t
s
t
r
a
p
p
i
n
g
w
i
t
h
D
2.obtain base gt by A(D~t)
2.
o
b
t
a
i
n
b
a
s
e
g
t
b
y
A
(
D
~
t
)
return G=Uniform({gt})
r
e
t
u
r
n
G
=
U
n
i
f
o
r
m
(
{
g
t
}
)
Decision Tree D e c i s i o n T r e e 算法通过递归的寻找一个在当前的资料上最好的划分特征或者说是分支条件 b(x) b ( x ) ,来不断的构建子树,最终得到一个在不同的输入下做不同的决策的 G G 。
Decision Tree算法
if termination
i
f
t
e
r
m
i
n
a
t
i
o
n
return base gt
r
e
t
u
r
n
b
a
s
e
g
t
else
e
l
s
e
1.learn b(x) and split D to Dc by b(x)
1.
l
e
a
r
n
b
(
x
)
a
n
d
s
p
l
i
t
D
t
o
D
c
b
y
b
(
x
)
2.build Gc⟵DTree(Dc)
2.
b
u
i
l
d
G
c
⟵
D
T
r
e
e
(
D
c
)
3.return G(x)=∑Cc=1|[b(x)=c]|Gc(x)
3.
r
e
t
u
r
n
G
(
x
)
=
∑
c
=
1
C
|
[
b
(
x
)
=
c
]
|
G
c
(
x
)
1.2 - 什么是Random Forest(RF)
这两个学习算法各自有一个很重要的特点:在 Bagging Bagging 中, 如果底层的弱学习器没有那么稳定,也就是所谓的方差很大的时候(或者说是对数据比较敏感的时候),通过 Bagging Bagging 中的 uniform u n i f o r m 的方式,不管是投票还是平均,就会把这些 variance v a r i a n c e 降低。巧的是 decision tree decision tree 是一个对输入的 data d a t a 很敏感的算法,或者说这个算法的 variance v a r i a n c e 很大, 可能 data d a t a 变一点, 得到的树就是不相同的。这两个学习算法一个本身的 variance v a r i a n c e 很大,一个可以降低 variance v a r i a n c e 。我们就想如果合在一起是不是能够取长补短呢?所以我们现在要做的事情就是用 bagging b a g g i n g 的方式将一堆的 decision tree d e c i s i o n t r e e 融合起来,就得到了 Random Forest R a n d o m F o r e s t ,在上一篇的最后我们说这篇要介绍的是 aggregation of aggregation a g g r e g a t i o n o f a g g r e g a t i o n 正是这个意思。
所以 random forest r a n d o m f o r e s t 中的 random r a n d o m 描述的 bagging b a g g i n g 算法中的 bootstraping b o o t s t r a p i n g 所产生的随机性,其中的 forest f o r e s t 描述的事实是 bagging b a g g i n g 的 base learner b a s e l e a r n e r 是 decision tree d e c i s i o n t r e e ,所以会产生很多的决策树,很多树合在一起就是森林 forest f o r e s t 。
Bagging B a g g i n g 的 base learner b a s e l e a r n e r 是 decision tree d e c i s i o n t r e e 的算法就是 random forest r a n d o m f o r e s t 算法。
通过以上的分析
Random Forest
R
a
n
d
o
m
F
o
r
e
s
t
算法流程如下:只是将
Bagging
B
a
g
g
i
n
g
中的
base alogrithm A
b
a
s
e
a
l
o
g
r
i
t
h
m
A
使用了
decision tree
d
e
c
i
s
i
o
n
t
r
e
e
Random Forest算法
For t=1,2,⋯,T
F
o
r
t
=
1
,
2
,
⋯
,
T
1.request size N′ data D~t by bootstrapping with D
1.
r
e
q
u
e
s
t
s
i
z
e
N
′
d
a
t
a
D
~
t
b
y
b
o
o
t
s
t
r
a
p
p
i
n
g
w
i
t
h
D
2.obtain base gt by DTree(D~t)
2.
o
b
t
a
i
n
b
a
s
e
g
t
b
y
D
T
r
e
e
(
D
~
t
)
return G=Uniform({gt})
r
e
t
u
r
n
G
=
U
n
i
f
o
r
m
(
{
g
t
}
)
1.3 - RF的一些优点
这样的算法其中的一个优点是所有 decision tree d e c i s i o n t r e e 的构建(从 bagging b a g g i n g 算法中的 bootstrap b o o t s t r a p 开始)可以 并行 的交给多个计算机去做,它们之间是互不影响。所以这个算法训练的效率很高。另外 CART算 C A R T 算 法中的很多优点:可以处理 multi classification m u l t i c l a s s i f i c a t i o n ,可以处理 miss features m i s s f e a t u r e s , 可以处理 categorical features c a t e g o r i c a l f e a t u r e s ,这些好处都被随机森立继承了下来。而 CART C A R T 算法中的主要缺点:对 data d a t a 很敏感, 特别是对一棵完全长成的树来说很容易过拟合,会因为 bagging b a g g i n g 最后所做的 uniform u n i f o r m 的关系而得到缓和。
1.4 - Random Forest中的一些技巧
在 bagging b a g g i n g 中,为了得到不同的 g g , 我们进行的操作是通过对 data d a t a 做随机的抽取。还有另一种对数据抽取方法也可以帮助我们得到不同的 g g , 那就是抽取不同的特征。例如在收集到的中共有100个特征, 我们每次随机抽取其中的10个特征来构造决策树(在进行特征选择时候只考虑这10个特征)。通过这样的方式很明显我们也能得到一些不一样的决策树。从技术上讲就是从100个维度中抽取10个维度,相当于做了一个特征转换,或者是一个低维度的投影。同时这样也使得算法更加的高效,原来 decision tree d e c i s i o n t r e e 中的 decision stump d e c i s i o n s t u m p 要在100个维度中挑选,现在只需要在10个维度中计算就好了。 Random Forest R a n d o m F o r e s t 的作者建议在每一次做分支 branch b r a n c h 的时候,都可以做一次 random r a n d o m 的 sampling s a m p l i n g 来选择不一样的一些特征进行子树的构建,通过增加 randomness r a n d o m n e s s 得到的树可能就会更加的 diversity d i v e r s i t y 。
实际的操作过程我想应该是:假设共有10个特征,构造 decision tree d e c i s i o n t r e e 的时候,先随机使用其中的4个特征,假设是特征1,4,5,7来选择最好的用于划分树的方式,假设此时选择到的特征是5,那么将数据集划分话两个( CART C A R T 算法的设置)子数据集;在其中的每一个子数据集再次随机的选取所有的10个特征中的4个特征来进行子树的构建,递归的执行直到结束。
或者我们可以考虑一种更加复杂的情况,在做分支 branch b r a n c h 或者说选择特征划分数据的时候,随机的选择 n n 个特征算它们的加权和然后以此为基础划分数据。这样看来, RF R F 中的 CART C A R T 算法如果采用 random combination r a n d o m c o m b i n a t i o n 构建特征,并且使用 decision stump d e c i s i o n s t u m p 在构建的特征上进行子树的构建的话,其本质上很像是在使用 perceptron p e r c e p t r o n 算法,即算一些特征的加权和判断和某一个阈值的关系进行分类。这样的话我们就不仅仅可以得到”垂直”或者是”水平”的分割性,还可以得到”斜”的分割线。
这就是基本的 random forest r a n d o m f o r e s t 算法,可以看到除了在 bagging b a g g i n g 中由 bootstrap b o o t s t r a p 这样的机制带来的 randomness r a n d o m n e s s 之外, 在 CART C A R T 算法中每次决定分支 branch b r a n c h 之前都要进行 random combination r a n d o m c o m b i n a t i o n 这样的的操作,这样就增添了更多的 randomness r a n d o m n e s s 。
2 - Out-Of-Bag Estimate
2.1 - 重新认识下bootstrapping
刚刚我们介绍了
Random Forest
R
a
n
d
o
m
F
o
r
e
s
t
,其中的一个核心是
bagging
b
a
g
g
i
n
g
,
bagging
b
a
g
g
i
n
g
中利用了一个很重要的机制叫做
bootstrap
b
o
o
t
s
t
r
a
p
,利用这个机制可以从
D
D
中选择出不同的样本形成
D~t
D
~
t
,然后使用
base learner
b
a
s
e
l
e
a
r
n
e
r
从
D~t
D
~
t
得到不同的
gt
g
t
。
这个
bootstrap
b
o
o
t
s
t
r
a
p
的过程可以表示为如下的一个表格:

表一
这个表格的第一列是所有的样本 {(x1,y1),(x2,y2),(x3,y3),⋯,(xN,yN)} { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ( x 3 , y 3 ) , ⋯ , ( x N , y N ) } , 表格的第二列表示的是: g1 g 1 是从 D~1 D ~ 1 中学习得到的,在 D~1 D ~ 1 中包括 (x1,y1),(xN,yN) ( x 1 , y 1 ) , ( x N , y N ) 等, 但是不包括 (x2,y2),(x3,y3) ( x 2 , y 2 ) , ( x 3 , y 3 ) 等,不包括的样本使用 ★ ★ 表示。我们把这些没有被选择到的 data d a t a ,也就是图中是 ★ ★ 的数据称为 out o u t - of o f - bag(OOB) b a g ( O O B ) , 这一小节主要开看看这些资料有什么用处。更准确的说, (x2,y2),(x3,y3) ( x 2 , y 2 ) , ( x 3 , y 3 ) 称为 g1 g 1 的 out o u t - of o f - bag b a g 。
2.2 - OOB的数量
我们先来计算一下,在
bootstrapping
b
o
o
t
s
t
r
a
p
p
i
n
g
的过程中有多少笔
OOB
O
O
B
的资料呢?假设我们从原来数量为
N
N
的资料中通过
bootstrap
b
o
o
t
s
t
r
a
p
的方式抽取
N′
N
′
笔资料。如果
N′=N
N
′
=
N
,那么样本
(xnyn)
(
x
n
y
n
)
在构造
gt
g
t
的时候一次也没有被抽到的可能性是:
(1−1N)N
(
1
−
1
N
)
N
如果
N
N
很大的时候:
所以如果抽取 N N 次的话,大概有笔资料会没有机会参与 gt g t 的构建。也就是大概有三分之一的资料都是 OOB O O B 的。
2.3 - 利用OOB的资料来做验证
这些 OOB O O B 的资料有什么作用呢?首先我们看一张我们比较熟悉的关于 Validation V a l i d a t i o n 的表格。
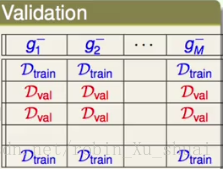
在做 validation v a l i d a t i o n 的时候,我们将数据划分为若干份,一部分用来做 train t r a i n , 一部分用来 validation v a l i d a t i o n 。在上表的每一列中我们使用那些 D~train D ~ t r a i n 来训练得到不同的 g−n g n − ,使用 D~val D ~ v a l 衡量 g−n g n − 的表现。 D~val D ~ v a l 之所以可以衡量 g−n g n − 的表现是因为 D~val D ~ v a l 没有参与 g−n g n − 的构建。
那么回到我们第一张表,其中被标记为 ★ ★ 的资料就相当于 D~val D ~ v a l 。首先从数量上来说,我们通常 validation v a l i d a t i o n 会使用五分之一或者是十分之一的资料, 刚刚我们推导了 OOB O O B 的数量大概是三分之一。这样的话, 这些 OOB O O B 的资料就可以用来验证 gt g t 表现。但是在 aggregation a g g r e g a t i o n 这系列的算法中,我们并不关心 gt g t 的表现好不好,我们关心的是最终的 G G 的表现。所以如果我们可以使用这些的资料来验证 G G 的好坏的话, 那么我们就可以对做一些参数的选择。
一种可行的方法如下:针对每一个样本,我们看看在什么时候这个样本可以用做 validation v a l i d a t i o n 的资料。例如对于表一中的最后一个样本 (xN,yN) ( x N , y N ) ,这个样本可以当成 g3 g 3 的 validation v a l i d a t i o n 的资料,也可以当成是可以当成 gT g T 的 validation v a l i d a t i o n 的资料,因为 (xN,yN) ( x N , y N ) 并没有参与其中任意一个 g g 的构建,所以可以当成是某个 G−N G N − 的 validation v a l i d a t i o n 的资料,其中的 G−N G N − 可以是 bagging(g3,gT) b a g g i n g ( g 3 , g T ) , 这样我们就可以看看 G−N G N − 在 (xN,yN) ( x N , y N ) 上的表现如何(将 xN x N 带入到 G− G − 中看结果和 yn y n 的差距)。那么对于每一个样本,我们都可以得到一个 G−n G n − (其中 n∈[1,N] n ∈ [ 1 , N ] )来看看其在 (xn,yn) ( x n , y n ) 上的表现如何。这就很像我们以前做 validation v a l i d a t i o n 的时候提到的 leave one out cross validation l e a v e o n e o u t c r o s s v a l i d a t i o n :把每一笔资料都当做 validation set v a l i d a t i o n s e t ,来计算模型的表现如何最后做平均。所以通过这样的方法我们可以定义很多 G− G − 来大概的知道最终的 G G 的表现如何。
利用来验证
G
G
的表现:对于每一笔资料构建一个
G−
G
−
,并计算
G−
G
−
在该资料上的表现,最后对所有的资料做平均,计算公式如下:
所以 bagging b a g g i n g 或者是 random forest r a n d o m f o r e s t 算法就有这样的优势:在得到了一个 G G 之后,我们就能计算出该好或者是不好。因为其中的 bootstrap b o o t s t r a p 的过程使得这些算法可以做 self validation s e l f v a l i d a t i o n 。这样就可以来对 Bagging B a g g i n g 或者是 Random Forest R a n d o m F o r e s t 中的参数进行调优。
以前为了做模型的选择需要将资料划分为
train set Dtrain
t
r
a
i
n
s
e
t
D
t
r
a
i
n
和
validation set Dval
v
a
l
i
d
a
t
i
o
n
s
e
t
D
v
a
l
,首先在
Dtrain
D
t
r
a
i
n
上做训练,然后在
Dval
D
v
a
l
上验证算法的好坏,通过不断的选择得到了好的模型之后还需要在
D
D
上再进行一次模型的训练得到最终的结果。
现在有了
OOB
O
O
B
之后,不需要进行数据集的划分,将所有的资料
D
D
都用于模型的训练,然后使用
EOOB
E
O
O
B
来进行模型的评估。

OOB O O B 的错误在实际应用中对于衡量 G G 的表现来说通常相当的准确。
3 - Feature Selection
上一小节讲述了可以用来衡量 random forest r a n d o m f o r e s t 的表现。这一节我们看看这样的方法还可以用在什么地方。我们这一小节关注一个新的问题: Feature Selection F e a t u r e S e l e c t i o n 。 Feature Selection F e a t u r e S e l e c t i o n 指的是当数据的维度很高的时候,我们可能想要把一些冗余的或者没有用的特征移除掉,也可以认为是我们想要学到一个从高维度到低纬度的转换, 通过这样的方式来选择好的特征或者是输入。 Feature Selection F e a t u r e S e l e c t i o n 的好处有:会使得不管是训练还是测试都更加的有效和简单;删除掉的维度可能是一些噪声, 这样能避免 overfitting o v e r f i t t i n g 的发生。
Decision tree D e c i s i o n t r e e 中需要选择好的特征来构建子树(或者说选择好的特征做分支条件 branch criteria b r a n c h c r i t e r i a ),所以在这个模型中有自己的 feature selection f e a t u r e s e l e c t i o n 。在 adaboost decision stump a d a b o o s t d e c i s i o n s t u m p 中也有做 feature selection f e a t u r e s e l e c t i o n 的过程。
我们做 Feature Selection F e a t u r e S e l e c t i o n 的主要思路是:不考虑特征的交互关系,利用某种方法给每一个 feature f e a t u r e 打一个分数来表示该 feature f e a t u r e 的重要性。这样排序之后取 Top N T o p N 得到的就是 N N 个比较重要的。
3.1 - 线性模型中的特征选择
这样的想法在线性模型中特别容易实现,因为在最终的线性模型中我们使用每一个特征和该特征的权重 w w 的乘积然后求和作为最后的得分,之后再将该分数应用到不同的问题当中,例如或者是 classifiction c l a s s i f i c t i o n 。所以当特征 x x 彼此之间取值的范围差不多,并且还不错的话, w w 的大小就是我们想要特征的重要性,所以使用 w w 的大小当做的重要性,经过排序取 top N t o p N 就能达到特征选择的效果。所以当做完一个 linear model l i n e a r m o d e l 之后,从模型返回的 w w 中就可以得出每一个特征的重要性,就可以完成一次特征选择。在特征选择之后,再决定是不是要利用这些特征做第二阶段或者是第三阶段的线性的或者非线性的学习。
3.2 - 非线性模型中的特征选择
在非线性的模型中, 做特征选择通常就要困难很多,因为在非线性的模型中,特征之间的关系是交杂在一起的,所以很难厘清单独一个特征的重要性。虽然是一个非线性的模型,但是由于其中的一些机制,所以让这个模型做特征选择相对来说比较简单一些(这就是为什么 feature selection f e a t u r e s e l e c t i o n 这个课题会选择在这里讲的原因,因为是利用 random forest r a n d o m f o r e s t 的机制在做)。怎么做呢?基本的方法叫做 random test r a n d o m t e s t ,该方法的思路是如果某一个特征比较重要,那么当这个特征中被掺入了一些噪声的时候,学习算法的表现一定会变差。所以通过比较学习的结果在原来的特征下的表现和该特征掺杂噪声下的表现的差距,就能判断这个特征的重要性。
那么掺杂一些什么样子的特征呢?如果加一些常见的高斯分布的噪声,那么可能会影响到这个特征上原来取值的分布。所以这可能不是一个很好的选择。借鉴一下
bootstrap
b
o
o
t
s
t
r
a
p
,因为是在原始的资料中进行抽样,所以这样得到的结果在一定的程度上维持了原始的资料的分布和特点。这里我们采用另一种比较类似的机制:
permutation
p
e
r
m
u
t
a
t
i
o
n
,具体的做法是对所有样本在该特征下的取值做随机的置换。这样就产生了噪声,并且保证了该特征的分布不会改变。这样的做法在统计上称为
permutation test
p
e
r
m
u
t
a
t
i
o
n
t
e
s
t
。 所以衡量第
i
i
个维度的特征的重要性的公式如下:
其中 D D 是原始的没有 permutation p e r m u t a t i o n 资料, D(p) D ( p ) 是将第 i i 个维度经过的资料。
原始的 random forest r a n d o m f o r e s t 的作者建议可以使用 permutation test p e r m u t a t i o n t e s t 来计算每一个维度的重要性。这样就可以拿来做特征的选择了。
根据 (1) ( 1 ) 式,为了确定特征 i i 的表现,看起来我们需要计算,那么通常的做法是需要在数据 D(p) D ( p ) 上重新训练模型,使用 validation v a l i d a t i o n 来验证表现。但是因为我们使用的是 random forest r a n d o m f o r e s t ,可能不需要 validation v a l i d a t i o n ,而使用 Eoob E o o b 来代替就好了。那么 (1) ( 1 ) 式可以改为:
其中 G G 是从得到的模型, G(p) G ( p ) 是从 D(p) D ( p ) 得到的模型。 G(p) G ( p ) 依然需要经过重新的训练, 我们希望得到一个投机取巧的近似方式,省去再训练一个模型 G(p) G ( p ) 的时间。我们的做法是将 Eoob(G(p)) E o o b ( G ( p ) ) 写成 E(p)oob(G) E o o b ( p ) ( G ) , 如果是这样的话, 就不需要再训练一个模型,而是仍然使用模型 G G , 只是在利用的资料做 validation v a l i d a t i o n 的时候做手脚, 即在验证的时候做 permutation p e r m u t a t i o n ,而不是在训练的时候做 permutation p e r m u t a t i o n 。
具体的做法是:
假设我们现在感兴趣的是第
i
i
个特征的重要性,在使用的资料
(xn,yn)
(
x
n
,
y
n
)
做
leave one out validation
l
e
a
v
e
o
n
e
o
u
t
v
a
l
i
d
a
t
i
o
n
的时候,所有未使用该笔数据的
gt
g
t
构成
G−
G
−
,之前在计算
EOOB
E
O
O
B
的时候直接计算
G−
G
−
在
(xn,yn)
(
x
n
,
y
n
)
上的表现即可,即先计算每一个
gt
g
t
在
(xn,yn)
(
x
n
,
y
n
)
上的得分,最后集成。但是现在有所不同, 在计算每一个
gt
g
t
的时候,必然会用到第
xn,i
x
n
,
i
,这个时候就是我们可以做手脚的时候:针对
(xn,yn)
(
x
n
,
y
n
)
的输入中的第
i
i
个特征 做
permutation
p
e
r
m
u
t
a
t
i
o
n
,并且算法的作者要求使用对于
G−
G
−
来说是
OOB
O
O
B
的资料来进行随机的替换。对所有的样本重复以上的工作,最后将
Eoob
E
o
o
b
平均就得到了在对特征
i
i
做了之后算法的表现。
使用这个的机制就可以得到每一个特征的重要性,之后就可以做特征的选择。这个方法的核心工具是:
- 利用 OOB O O B 的资料来做 validation v a l i d a t i o n 。
- permutation test p e r m u t a t i o n t e s t 机制。
在实际的应用当中, random forest r a n d o m f o r e s t 的特征选择非常好用,很多人在面临非线性的问题的时候,会先使用 random forest r a n d o m f o r e s t 来做一些初步的特征选择。
表一
4 - Random Forest算法的表现
4.1 - 资料1
一个简单的数据资料
这一小节看一下
random forest
r
a
n
d
o
m
f
o
r
e
s
t
算法的表现,同样针对二元分类的问题。

上图中左图是使用
CART+random combination
C
A
R
T
+
r
a
n
d
o
m
c
o
m
b
i
n
a
t
i
o
n
的结果;中图是使用
bootstrap
b
o
o
t
s
t
r
a
p
机制选择了
N′(=N/2)
N
′
(
=
N
/
2
)
个样本训练的
Decision Tree
D
e
c
i
s
i
o
n
T
r
e
e
决策树,使用的方法是
CART+random combination
C
A
R
T
+
r
a
n
d
o
m
c
o
m
b
i
n
a
t
i
o
n
,因为只是使用了原始数据的一半,所有存在一些划分错误的点;右图是使用一棵决策树组成的
random forest
r
a
n
d
o
m
f
o
r
e
s
t
,所以和中图得到的结果是一样的。
接下来我们想要观察的是,当树的个数增多的时候,
random forest
r
a
n
d
o
m
f
o
r
e
s
t
的表现,也就是右图的表现。
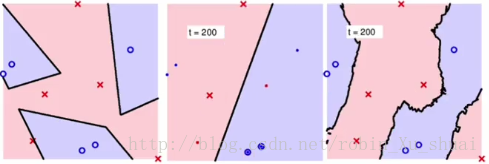
中图是使用 bootstrap b o o t s t r a p 机制选择了 N′(=N/2) N ′ ( = N / 2 ) 个样本训练的 Decision Tree D e c i s i o n T r e e 决策树(第200棵)。右图表现的是综合200棵树的表现。
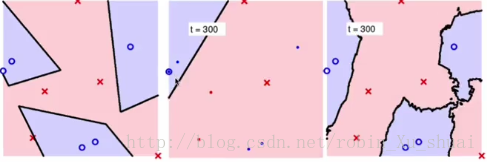
中图是使用 bootstrap b o o t s t r a p 机制选择了 N′(=N/2) N ′ ( = N / 2 ) 个样本训练的 Decision Tree D e c i s i o n T r e e 决策树(第300棵)。右图表现的是综合300棵树的表现。

中图是使用 bootstrap b o o t s t r a p 机制选择了 N′(=N/2) N ′ ( = N / 2 ) 个样本训练的 Decision Tree D e c i s i o n T r e e 决策树(第800棵)。右图表现的是综合800棵树的表现。
这时我们观察到由 CART+random combination C A R T + r a n d o m c o m b i n a t i o n 算法在 bagging b a g g i n g 中的 bootstrap b o o t s t r a p 机制得到的不同的训练样本上得到的 800 800 棵 Decision Tree D e c i s i o n T r e e 组成的 random forest r a n d o m f o r e s t 算法得到的边界(右图)大概会通过 ◯ ◯ 和 × × 的中间, 而只有一棵树的时候,通常是不会有这样的效果的(左图) 。通过 ◯ ◯ 和 × × 的中间正是我们在 SVM S V M 中讲过的 large margin l a r g e m a r g i n 。 另外使用 random forest r a n d o m f o r e s t 得到的边界要比单一的一棵树 CART C A R T 得到的边界要平滑的多。 所以 random forest r a n d o m f o r e s t 这样利用了很多棵树之后做出了平滑并且具有 large margin l a r g e m a r g i n 性质的边界。
4.2 - 资料2
稍微复杂一点的资料。

左图是使用 bootstrapping N′(=N/2) b o o t s t r a p p i n g N ′ ( = N / 2 ) 得到的边界;右图是使用这一棵树得到的 random forest r a n d o m f o r e s t 。
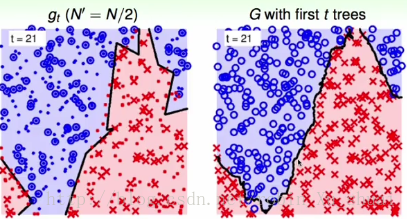
左图是使用 bootstrapping(N′=N/2) b o o t s t r a p p i n g ( N ′ = N / 2 ) 得到的边界(在第21轮中);右图是使用这21棵树得到的 random forest r a n d o m f o r e s t 的结果。这样的非线性边界比起左图中的边界要鲁棒很多,具有比较平滑比较稳定的特性。
4.3 - 资料3
资料2+10%噪声

左图是使用 bootstrapping N′(=N/2) b o o t s t r a p p i n g N ′ ( = N / 2 ) 得到的边界;右图是使用这一棵树得到的 random forest r a n d o m f o r e s t 。可以看到在图中决策树给出的边界中有一部分在努力的去过拟合那些噪声。

左图还是一棵决策树的表现,右图是使用21棵树构成的 random forest r a n d o m f o r e s t ,可以看出边界已经很平滑,虽然还有少数的边界在拟合噪声。但是通过 randomforest r a n d o m f o r e s t 这种投票的机制,已经可以避免很多由噪声产生的影响。 (noise corrected by voting) ( n o i s e c o r r e c t e d b y v o t i n g )
因为 random forest r a n d o m f o r e s t 的理论假设是当使用无限多棵树的时候,会得到比较好的结果,所以一般来说我们会使用尽量多的树。
小测试
下面的哪一个不是 random forest r a n d o m f o r e s t 的正确用法
- 使用 bootstrapped b o o t s t r a p p e d 数据来训练每一棵树
- 使用 EOOB E O O B 来验证 random forest r a n d o m f o r e s t 的表现
- 使用 permutation test p e r m u t a t i o n t e s t 来进行 feature selection f e a t u r e s e l e c t i o n
- 固定树的数量
显然答案应该是4,树的数量要视具体的问题来决定。
5 - 总结
这篇介绍了
Random Forest
R
a
n
d
o
m
F
o
r
e
s
t
算法。这个算法的本质是将
bagging
b
a
g
g
i
n
g
算法中的
base algorithm
b
a
s
e
a
l
g
o
r
i
t
h
m
使用
decision tree
d
e
c
i
s
i
o
n
t
r
e
e
。通常我们会把
decision tree
d
e
c
i
s
i
o
n
t
r
e
e
的过程利用
randomly projected
r
a
n
d
o
m
l
y
p
r
o
j
e
c
t
e
d
添加一点随机性,也就是用通过随机结合的各式各样的
feature
f
e
a
t
u
r
e
来做切分的决策。同时在这个算法中由于使用了
bootstrap
b
o
o
t
s
t
r
a
p
的机制,所以我们可以得到一些
OOB
O
O
B
的数据来验证算法表现的好坏,而不必使用使用
validation data
v
a
l
i
d
a
t
i
o
n
d
a
t
a
来做
validation
v
a
l
i
d
a
t
i
o
n
。也就是这个算法可以
self validation
s
e
l
f
v
a
l
i
d
a
t
i
o
n
。 另外这个自我验证的方式可以配合
permutation test
p
e
r
m
u
t
a
t
i
o
n
t
e
s
t
可以来做
feature selection
f
e
a
t
u
r
e
s
e
l
e
c
t
i
o
n
。最后我们说到当树的数量够多的时候,我们可以得到相对平滑的边界。
Random forest
R
a
n
d
o
m
f
o
r
e
s
t
是
bagging
b
a
g
g
i
n
g
和
decision tree
d
e
c
i
s
i
o
n
t
r
e
e
的结合。下一篇我们介绍的
boosted decision tree
b
o
o
s
t
e
d
d
e
c
i
s
i
o
n
t
r
e
e
是
AdaBoost
A
d
a
B
o
o
s
t
和
decision tree
d
e
c
i
s
i
o
n
t
r
e
e
的结合。















 918
918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









