







机器学习的算法中,讨论的最多的是某种特定的算法,比如Decision Tree,KNN等,在实际工作以及kaggle竞赛中,Ensemble methods(组合方法)的效果往往是最好的,当然需要消耗的训练时间也会拉长。
所谓Ensemble methods,就是把几种机器学习的算法组合到一起,或者把一种算法的不同参数组合到一起。基本上分为如下两类:
- Averaging methods(平均方法),就是利用训练数据的全集或者一部分数据训练出几个算法或者一个算法的几个参数,最终的算法是所有这些算法的算术平均。比如Bagging Methods(装袋算法),Forest of Randomized Trees(随机森林)等。
实际上这个比较简单,主要的工作在于训练数据的选择,比如是不是随机抽样,是不是有放回,选取多少的数据集,选取多数训练数据。后续的训练就是对各个算法的分别训练,然后进行综合平均。这种方法的基础算法一般会选择很强很复杂的算法,然后对其进行平均,因为单一的强算法很容易就导致过拟合(overfit现象),而经过aggregate之后就消除了这种问题。
- boosting methods(提升算法),就是利用一个基础算法进行预测,然后在后续的其他算法中利用前面算法的结果,重点处理错误数据,从而不断的减少错误率。其动机是使用几种简单的弱算法来达到很强大的组合算法。所谓提升就是把“弱学习算法”提升(boost)为“强学习算法,是一个逐步提升逐步学习的过程;某种程度上说,和neural network有些相似性。经典算法 比如AdaBoost(Adaptive Boost,自适应提升),Gradient Tree Boosting(GBDT)。
这种方法一般会选择非常简单的弱算法作为基础算法,因为会逐步的提升,所以最终的几个会非常强。
boosting相对复杂,有如下几个方面:1)流程: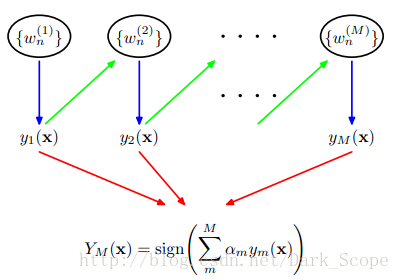
2)如何开始。选择一个弱分类器,只要比随机猜测好一点点就可,也就是说a>0即可。3)前面算法如何影响后续算法,或者说,如何进行算法的提升。前面算法的系数w会根据一定的算法修改从而形成后续算法的系数,所以如何修改系数w是非常关键的。不同的损失函数(算法的预测值和数据的实际值之差)以及如何极小化损失函数的方法决定了如何更新系数w,同时决定了boosting的最终效果,几个常见的boosting:
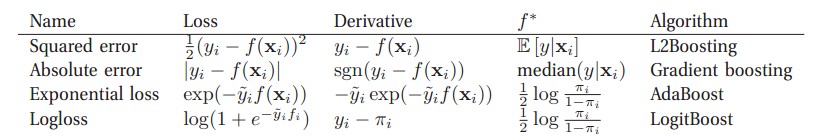
4)最终的算法表现形式:
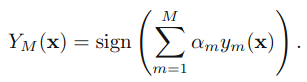 其中
其中,而e为算法错误率,如果e<0.5那么a>0,e越小(错误越少)a越大(权重越高),该算法在最终结果中约有话语权。
【NOTE】
本文中,算法本身不重要,重要的是,什么是Ensemble Methods,以及如何做boost的过程。一旦决定了loss function,我们就可以用求偏导数+找梯度方向来处理boost的方向。
参考文章:
http://blog.csdn.net/dark_scope/article/details/24863289
http://blog.csdn.net/dark_scope/article/details/14103983
《The Elements of Statistical Learning 》















 596
596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









