









[ 版权申明:本文系作者原创,转载请注明出处]
文章出处: http://blog.csdn.net/sdksdk0/article/details/51691862
作者:朱培 ID:sdksdk0
---------------------------------------------------------------------------------------------------------------
因为整个项目工程师非常庞大的,一方面由于整个开发流量非常繁琐,不可能通过一篇文章就可以说得清楚的,另一方面由于保密性,所以这里只分享其中的部分内容。首先会从整体架构等说起,通过本文的学习主要是进一步了解海量数据挖掘的框架流程,对数据采集流程、内容识别、知识库的建立以及行为轨迹增强有初步的了解,学会简单的url清洗以及能够开发出简单的分类MapReducer程序。当然,如果部分内容看不懂也没关系,毕竟这需要经验的积累,不要太急于求成,可以先查看我的其他文章!
一、项目背景介绍
1.1 项目背景
对于运营商来说,使用海量数据挖掘对客户移动互联网行为进行采集,分析,发现用户关注的内容,为开展营销提供号码支持。当然,也不局限于这些功能。例如一个用户在用手机看小说,那么肯定有一个url的网址啦,用户所有访问的网址,ip,时间戳,上下行流量,基站,网络模式,手机型号等一大串信息都会被记录下来并在运营商的的云端进行存储,这个数据量是非常非常大的。这个时候我们可以通过抓取到用户访问过的url和总流量,然后通过爬虫去分析用户浏览的这个网页是怎么样的一个网页,通过内容识别机制来找出这个网页的内容,例如一个用户在看的是新闻url,然后我们通过爬虫发现其访问的是新浪新闻,然后内容识别发现其经常访问关于娱乐新闻,明星八卦等,(基于流量和这类新闻的浏览次数来判读是否经常访问),那么这个时候我们就可以给其推送一些娱乐周边新闻等,只要用户点击去浏览了那么肯定会产生流量啊,那么运营商的营销的目的不就达成了么,哈哈哈!
该项目投产之后的收效为:
1.2 项目概况
节点就是:PC服务器,放到机柜中,配置(4颗12核cpu,64G或128G内存,磁盘1T*8/12)
数据量,每天2T左右(10亿行以上),时间维度,地域维度。最长分析3个月的。每天增量不断增长。
项目组成员:
研发团队:数据采集(3-4人),行为轨迹增强(10人左右),ETL(20人左右,需要写web程序)
实施团队:部署环境,2-3个实施人员带上20多个开发人员
运维团队:
销售团队等
1.3 系统架构图
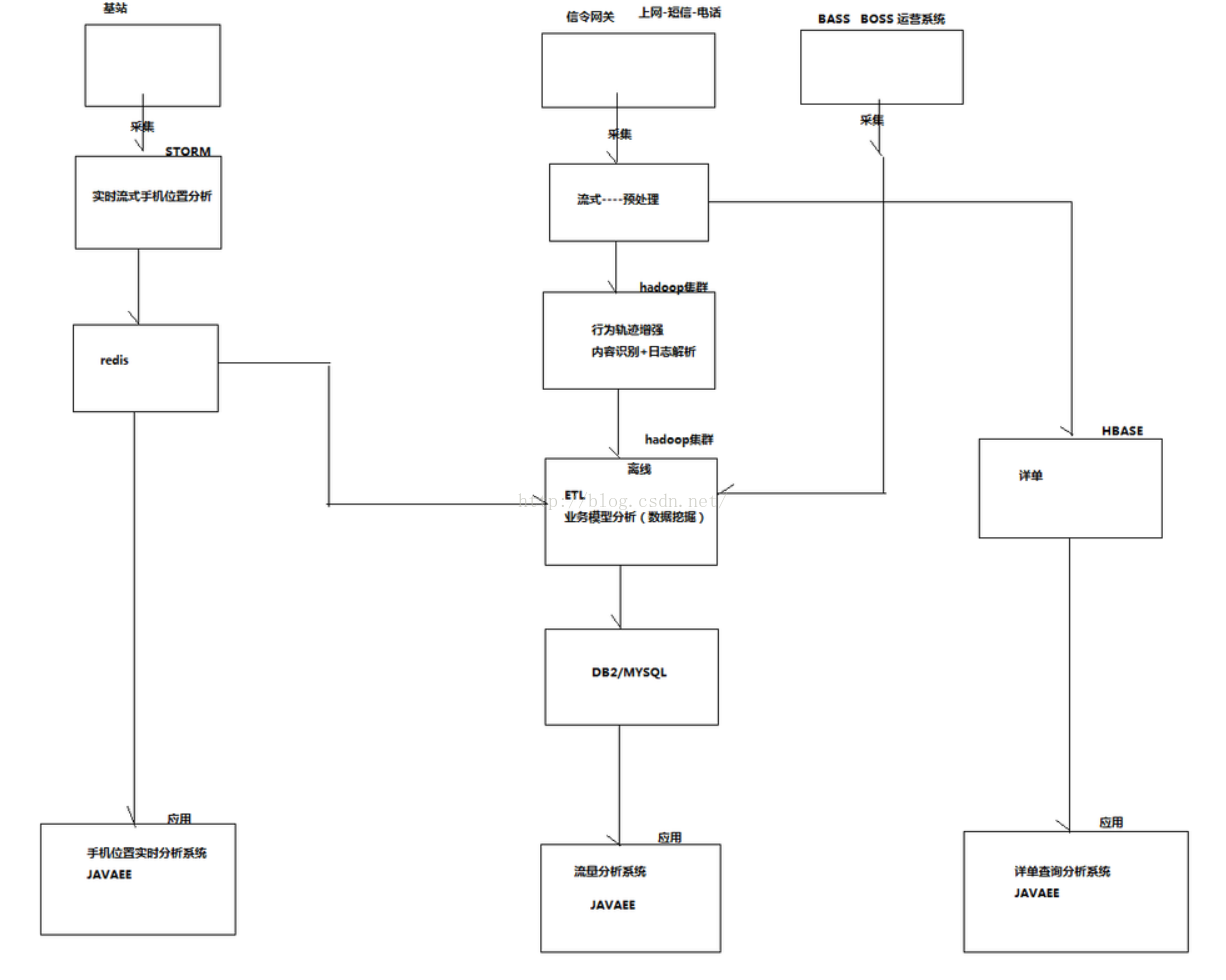
二、数据采集系统架构
既然前面说到了要抓取url的网址,那么我们如何来获得这些用户的数据呢!当然,普通人肯定是得不到运营商的数据啦,因为这些数据都是保密的,那么我要说的是运营商如何得到用户数据呢!
项目所处理的数据
硬件设备(网关,基站等)
其他系统(运营系统等)
业务日志:
HTTP日志/WAP日志/MMS日志/CONN日志/DNS日志
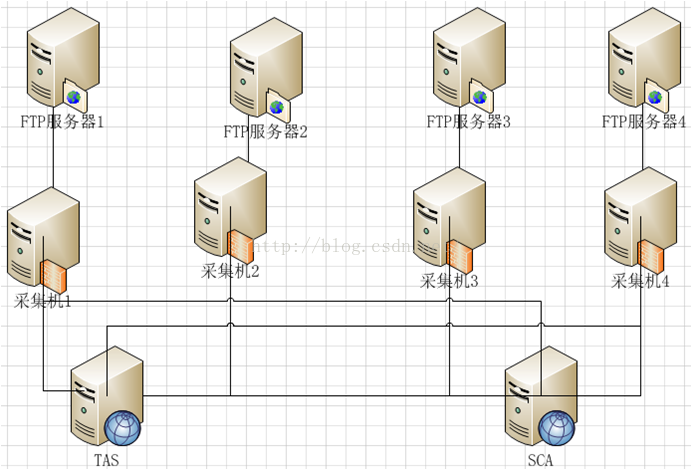
从移动运营商的核心网关中把需要的数据发送到ftp服务器上,然后我们这边就会提供ftp的客户端去采集ftp服务器的数据,然后处理之后过来进行分析。
三、内容识别模块
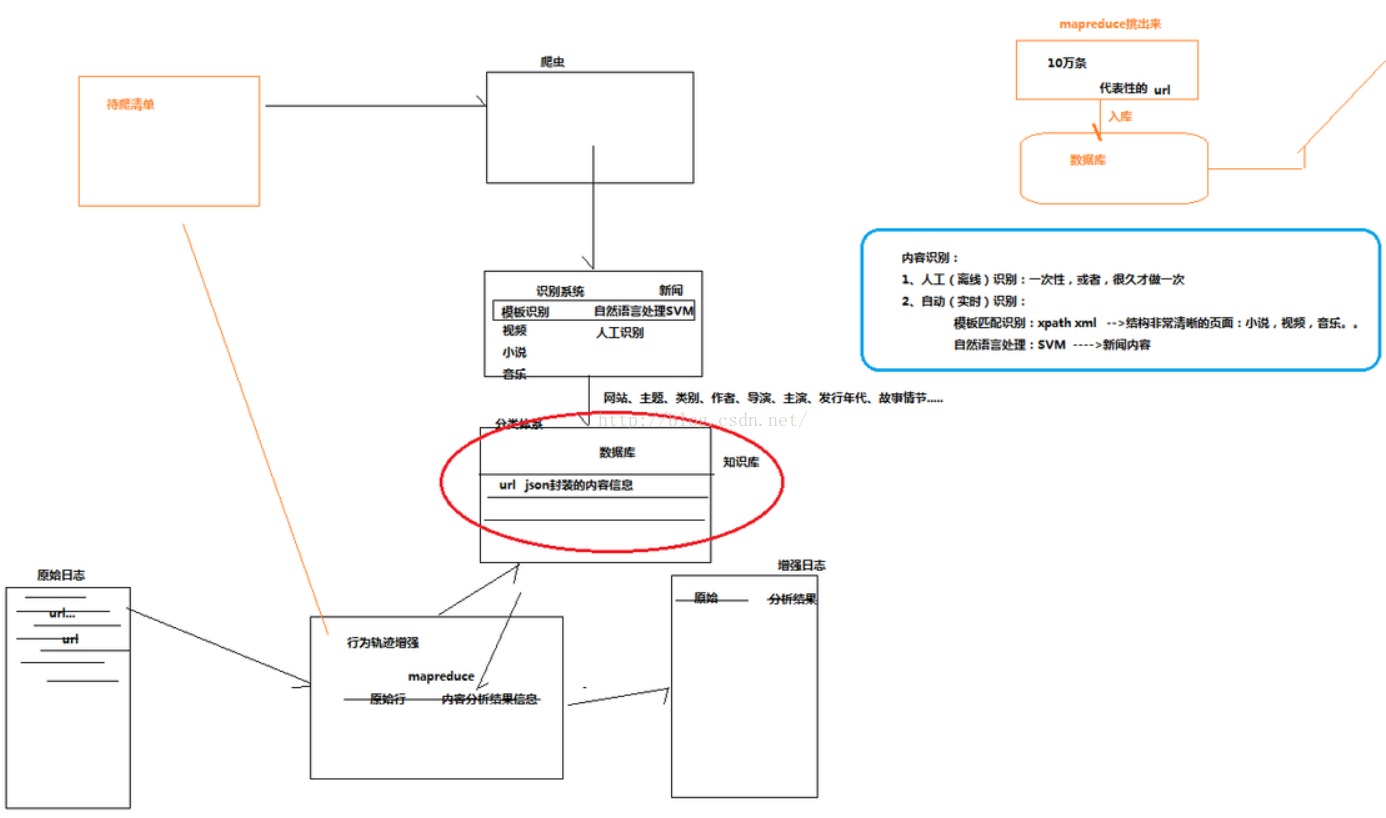
把url经过爬虫然后到识别系统,分析出网站名,主题,类别,(作者)等
将分类体系导入到数据库中,url json封装的内容信息。
大量的日志不断的产生,然后通过行为轨迹增强,通过一个mapreduce,
如果这个数据匹配到了,则将原始行+内容分析结果信息(从知识库来的数据)导出到增强日志。如果匹配不到的数据就输出到一个待爬清单中。
识别系统:自然语言处理SVM(实时识别),人工识别(人工一条条的去识别),模板识别(一个网页的内容的位置一般不会变,用xpath来定位到我们所需要查找的节点)
相信学过xml的应该都会使用xpath了,如果不会的话,可以查阅我这篇文章:http://blog.csdn.net/sdksdk0/article/details/51555090
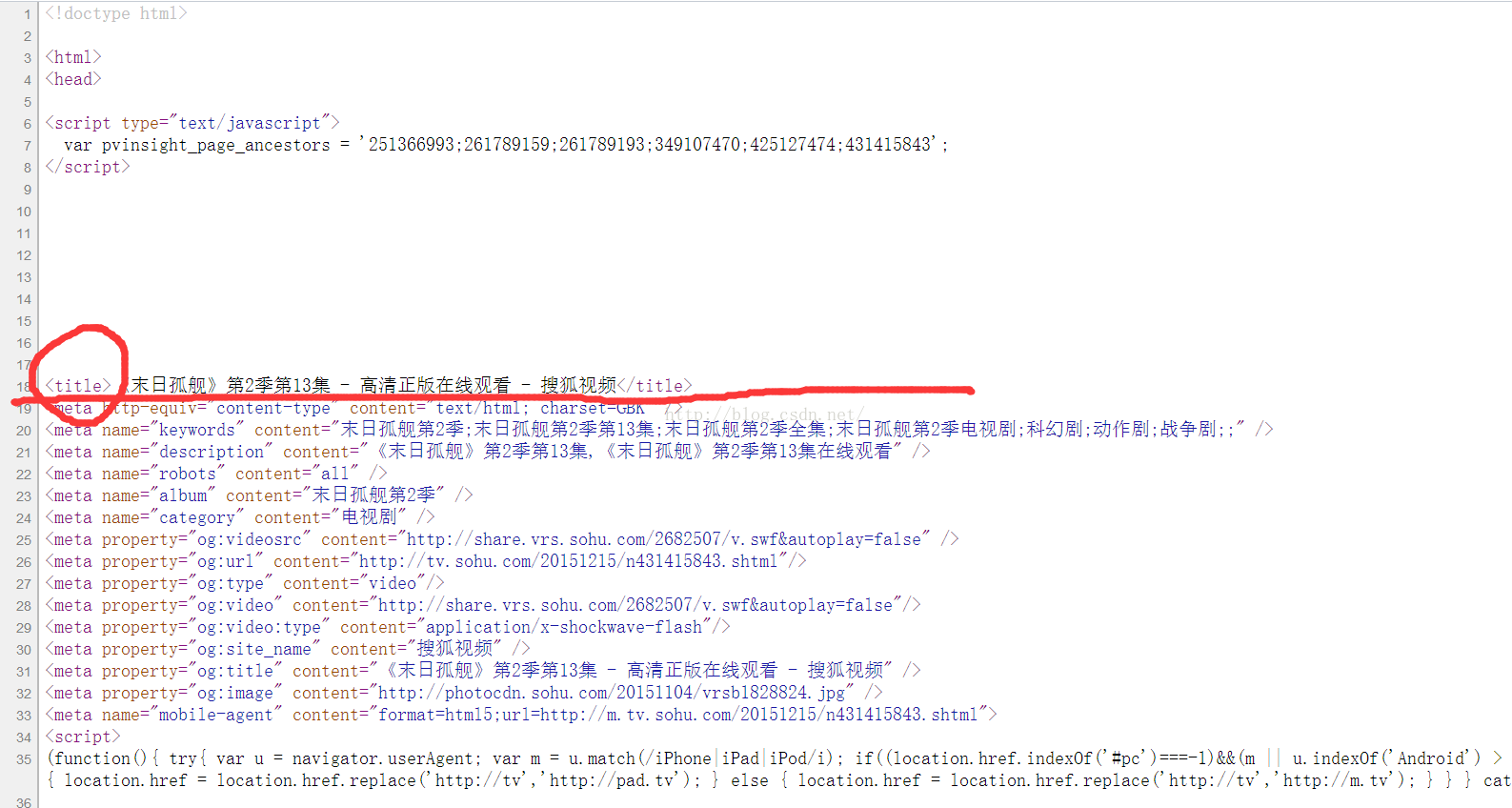
在这个项目中庸xpath来做这个模板匹配:例如
对于一个网页的html页面来说,我们可以这样来匹配其标题,例如我们打开搜狐的html,我们可以看到他的这个网页标题是<title></title>的,所以我们对于这类网站就可以用xpath来定位这个title在哪里,然后去获取这title节点中内容
<site>
souhu.com
<site>
<property>
<name>movie_name</name>
<xpath>/path/.../</xpath>
</property>
</site>
</site>所以总的来说,对于内容识别要采用多种方式去做,不要局限于一种,不同类型的网站最好有不同的解决方案。
我们使用自然语言处理来进行分析的时候还有问题就是,一个网页的内容太多了,svm分析有时候不能完全的识别到我们想要的内容,就像一条新闻,本来这个新闻的主标题才是中国网页的主要内容,而使用自然语言处理系统的话它可能会把新闻下面的广告读成了这个网页的主要内容了,所以这样的话就会有误差了。当然咯,自然语言分析还是很有用,那么为了更精确的识别照顾好网页的内容怎么办呢。好吧,那当然是最传统的人工读取了,由可爱的实习生们把这些网页一条条的浏览,然后记录这个网页的主要内容!(好吧,不要惊讶 ,移动就是这么干的)。然后读取大概10万个网页,这样的话就形成了一个规则库,这个就比自然语言处理和模板匹配的结果更加精确了。
,移动就是这么干的)。然后读取大概10万个网页,这样的话就形成了一个规则库,这个就比自然语言处理和模板匹配的结果更加精确了。
四、知识库url挑选
两个知识库,一个规则库(人工分析的),还有一个实例库(自动分析系统)。
先把url进行规则分析,如果有则输出,没有没有则放到实例库,如果实例库也没有了,就放到待爬清单中。
先拿1T的样本数据,然后网址按流量汇总排序出来,总流量的前80%,总条数10万条。
因为只要挑选出来就可以了,不需要实时在运行的,所以只要一个job就可以了。
这里我们主要拿到一个url和总流量来进行分析和处理,其他更为复杂的情况这里就不分享了哦。
我们首先可以在eclipse总新建一个jav工程,导入各种hadoop/lib下面的jar包,或者直接新建一个mapRedecer工程也可以。
新建一个bean类:记得要继承一个Comparable接口。
package cn.tf.kpi;
public class FlowBean implements Comparable<FlowBean>{
private String url;
private long upflow;
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public long getUpflow() {
return upflow;
}
public void setUpflow(long upflow) {
this.upflow = upflow;
}
public FlowBean(String url, long upflow) {
super();
this.url = url;
this.upflow = upflow;
}
public FlowBean() {
super();
}
@Override
public int compareTo(FlowBean o) {
return (int) (o.getUpflow() - this.upflow) ;
}
@Override
public String toString() {
return "FlowBean [url=" + url + ", upflow=" + upflow + "]";
}
}
其实这里和我之前写的那个用户流量分析系统有很多类似的地方。
package cn.tf.kpi;
import java.io.IOException;
import java.util.TreeSet;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import cn.tf.kpi.TopURL.TopURLMapper.TopURlReducer;
public class TopURL {
public static class TopURLMapper extends
Mapper<LongWritable, Text, Text, LongWritable> {
private Text k = new Text();
private LongWritable v = new LongWritable();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] fields = StringUtils.split(line, "\t");
try {
String url = fields[26];
long upFlow = Long.parseLong(fields[30]);
k.set(url);
v.set(upFlow);
context.write(k, v);
} catch (Exception e) {
e.printStackTrace();
}
}
public static class TopURlReducer extends
Reducer<Text, LongWritable, Text, LongWritable> {
private Text k = new Text();
private LongWritable v = new LongWritable();
TreeSet<FlowBean> urls = new TreeSet<FlowBean>();
//全局流量和
long globalFlowSum =0;
@Override
protected void reduce(Text key, Iterable<LongWritable> values,
Context context) throws IOException, InterruptedException {
long count = 0;
for (LongWritable v : values) {
count += v.get();
}
globalFlowSum +=count;
FlowBean bean = new FlowBean(key.toString(), count);
urls.add(bean);
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
long tempSum=0;
for(FlowBean bean:urls){
//取前80%的
if(tempSum/globalFlowSum<0.8){
k.set(bean.getUrl());
v.set(bean.getUpflow());
context.write(k,v);
tempSum+=bean.getUpflow();
}else{
return;
}
}
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance();
job.setJarByClass(TopURL.class);
// 指定本job使用的mapper类
job.setMapperClass(TopURLMapper.class);
// 指定本job使用的reducer类
job.setReducerClass(TopURlReducer.class);
// 指定mapper输出的kv的数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 指定reducer输出的kv数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 指定本job要处理的文件所在的路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 指定本job输出的结果文件放在哪个路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 将本job向hadoop集群提交执行
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
}
然后把这个工程打成一个jar包,命名为top.jar。存放到你指定的一个位置就可以了,我存放的位置是在/home/admin1/hadoop/lx/top.jar
现在启动hadoop集群服务,
把采集到的数据上传到hdfs的/topflow/data目录下,下载地址在文末贴出。(源数据下载地址:http://download.csdn.net/detail/sdksdk0/9551559)。把这个log.1文件上传你的hdfs目录中,这个log.1主要是几十万条采集到的用户流量的数据。
bin/hadoop fs -mkdir -p /topflow/data
bin/hadoop fs -put ../lx/log.1 /topflow/data
把jar包放到hadoop中执行:
bin/hadoop jar ../lx/top.jar cn.tf.kpi.TopURL /topflow/data /topflow/output 执行之后会见过系统的处理就可以选出url了。
内容如下:就是一个url网址+总流量大小,并且按照降序排列,所以我们只要拿到这个数据源的总流量最大的前80%的用户数据就可以了,然后就可以进行下一步的操作了。编译好的这个文件会存放在你的hdfs目录中,去查看一下就可以了。
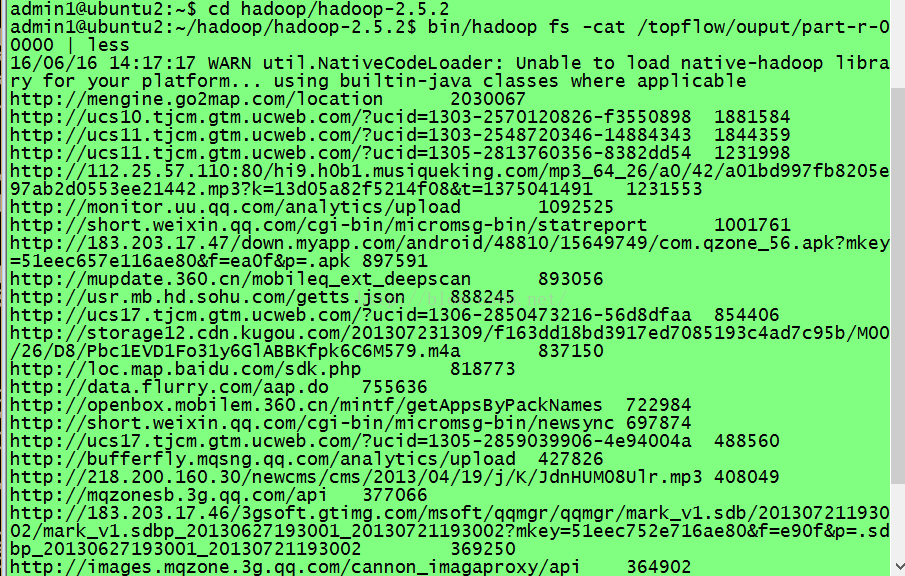
然后你需要先准备一个mysql数据库,用于存放清洗好的数据,也就是我们把刚才得到的数据,是存放在hdfs的/topflow/output目录下的那个文件,把这个文件存到mysql数据库中,作为一个知识库。
在mysql数据中新建一个test数据库,然后建一个名字叫rule的表:
create database test;
use test;
create table rule(
url varchar(1024),
info varchar(20) default 'complited'
)
然后需要导入数据,这里我直接使用sqoop来把hdfs中的数据导入到mysql中去,先去下载一个sqoop,
sqoop是一个用来在hadoop体系和关系型数据库之间进行数据互导的工具
----实质就是将导入导出命令转换成mapreduce程序来实现。sqoop安装:安装在一台节点上就可以了。
首先下载好sqoop之后解压进入conf目录下,配置hadoop的路径,然后把mysql的驱动jar包复制一份放到sqoop的lib目录中。
在sqoop的conf目录下,修改sqoop-env.sh
export HADOOP_COMMON_HOME=/home/admin1/hadoop/hadoop-2.5.2
export HADOOP_MAPRED_HOME=/home/admin1/hadoop/hadoop-2.5.2然后启动:进入sqoop的目录下,运行下面这个程序
bin/sqoop export --connect jdbc:mysql://ubuntu2:3306/test --username hive --password a \
--table rule \
--export-dir /topflow/output \
--columns url \
--input-fields-terminated-by '\t'
然后就会把数据全部存入到mysql中,经过清洗之后,这里大概是6070条数据,在实际生产中的数据量可不仅仅只有这么一点点。
select *from rule;查看这个表里面的内容。
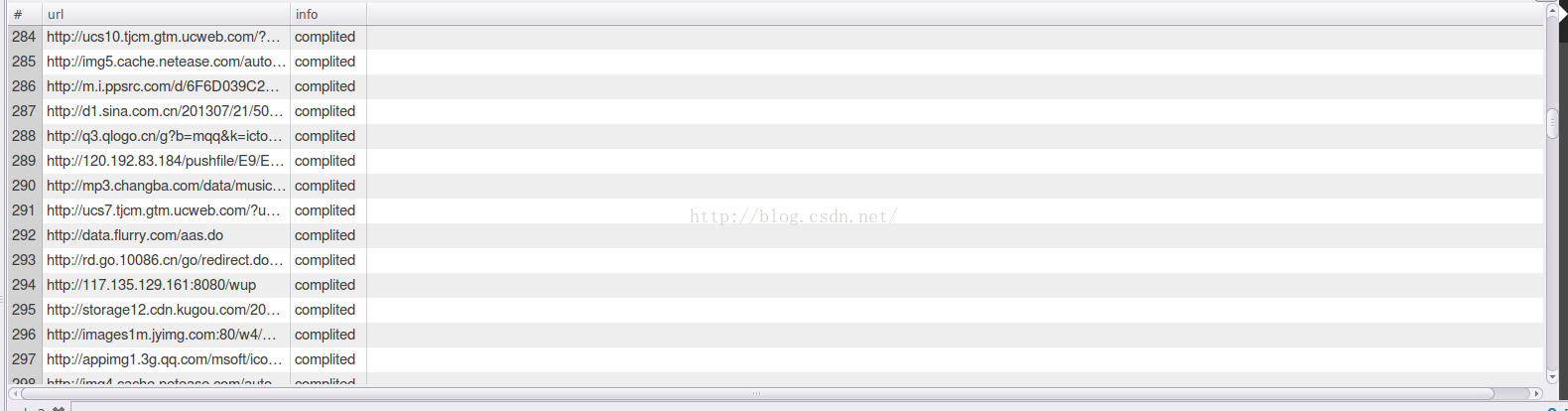
到这里,我们这个url知识库就建立好了,接下来就可以愉快的进行后续操作了。
五、用户行为轨迹增强
用户行为增强就是把原始的数据源来和这个知识库做匹配,如果有则把原来的数据+分析后的数据作为一个增强的模块,如果没有在这个知识库中匹配到,则放到待爬数据中。接下来演示的就是把原始数据(也就是前面提到的log.1)的数据与我们刚才存放到mysql中的六千多条数据进行匹配,若有,则输出到增强日至,若无则存放到待爬数据。
这个部分的内容其实是比较简单的,就是流程比较复杂一点。接下来继续在那个eclipse中新建3个类。
先把mysql的驱动包导入我们新建的这个工程,并build path一下。
这里写一个连接数据库的泪,因为我们要和数据库中的知识库做对比嘛,这是一个基础的jdbc连接类,这种很简单的我相信大街上随便一个人都会写的哈 。这里就不再重复啰嗦啦!
。这里就不再重复啰嗦啦!
package cn.tf.kpi;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.HashMap;
public class DBLoader {
public static void dbLoader(HashMap<String, String> ruleMap) {
Connection conn = null;
Statement st = null;
ResultSet res = null;
try {
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection("jdbc:mysql://ubuntu2:3306/test", "hive", "a");
st = conn.createStatement();
res = st.executeQuery("select url,info from rule");
while (res.next()) {
ruleMap.put(res.getString(1), res.getString(2));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try{
if(res!=null){
res.close();
}
if(st!=null){
st.close();
}
if(conn!=null){
conn.close();
}
}catch(Exception e){
e.printStackTrace();
}
}
}
public static void main(String[] args) {
DBLoader db = new DBLoader();
HashMap<String, String> map = new HashMap<String,String>();
db.dbLoader(map);
System.out.println(map.size());
}
}
接下来就是一个增强日志类:
package cn.tf.kpi;
import java.io.IOException;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class LogEnhanceOutputFormat extends FileOutputFormat<Text, NullWritable>{
@Override
public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext context) throws IOException, InterruptedException {
FileSystem fs = FileSystem.get(context.getConfiguration());
FSDataOutputStream tocrawlOut = fs.create(new Path("hdfs://ubuntu2:9000/topflow/tocrawl/url.list"));
FSDataOutputStream enhancedOut = fs.create(new Path("hdfs://ubuntu2:9000/topflow/enhanced/enhanced.log"));
return new LogEnhanceRecordWriter(tocrawlOut,enhancedOut);
}
public static class LogEnhanceRecordWriter extends RecordWriter<Text, NullWritable>{
private FSDataOutputStream tocrawlOut;
private FSDataOutputStream enhancedOut;
public LogEnhanceRecordWriter(FSDataOutputStream tocrawlOut, FSDataOutputStream enhancedOut) {
this.tocrawlOut = tocrawlOut;
this.enhancedOut = enhancedOut;
}
@Override
public void write(Text key, NullWritable value) throws IOException, InterruptedException {
if(key.toString().contains("tocrawl")){
//写入待爬清单目录(hdfs://)
tocrawlOut.write(key.toString().getBytes());
}else{
//写入增强日志目录(hdfs://)
enhancedOut.write(key.toString().getBytes());
}
}
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
IOUtils.closeStream(enhancedOut);
IOUtils.closeStream(tocrawlOut);
}
}
}
最后把最重要的一个类写完就可以了;这里只要写一个map就可以了
package cn.tf.kpi;
import java.io.IOException;
import java.util.HashMap;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class LogEnhance {
public static class LogEnhanceMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
private HashMap<String, String> contentMap = new HashMap<String, String>();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
// 加载整个内容识别知识库到内存中
DBLoader.dbLoader(contentMap);
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = StringUtils.split(line, "\t");
try {
// 抽取url字段,去匹配规则库获取url页面的内容识别信息
String url = fields[26];
String contentResult = contentMap.get(url);
String result = null;
// 如果知识库中没有这条url的内容识别信息,就只输出url字段到待爬清单
if (StringUtils.isBlank(contentResult)) {
result = url + "\t" + "tocrawl" + "\n";
} else {
// 在原始日志内容后面追加内容识别结果信息作为增强之后的输出
result = line + "\t" + contentResult +"\n";
}
context.write(new Text(result), NullWritable.get());
} catch (Exception e) {
context.getCounter("malformed", "line").increment(1);
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance();
job.setJarByClass(LogEnhance.class);
// 指定本job使用的mapper类
job.setMapperClass(LogEnhanceMapper.class);
// 指定mapper输出的kv的数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
// 指定reducer输出的kv数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 指定采用自定义的outputformat
job.setOutputFormatClass(LogEnhanceOutputFormat.class);
// 指定本job要处理的文件所在的路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 虽然自定义outputformat中已有输出目录,但是这里还是要设置一个目录用来输出_SUCCESS文件
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 将本job向hadoop集群提交执行
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
}
继续把这个工程达成jar包,命名为top1.jar,然后放到hadoop下面去运行:
bin/hadoop jar top.jar cn.tf.kpi.LogEnhance /topflow/data /topflow/output1
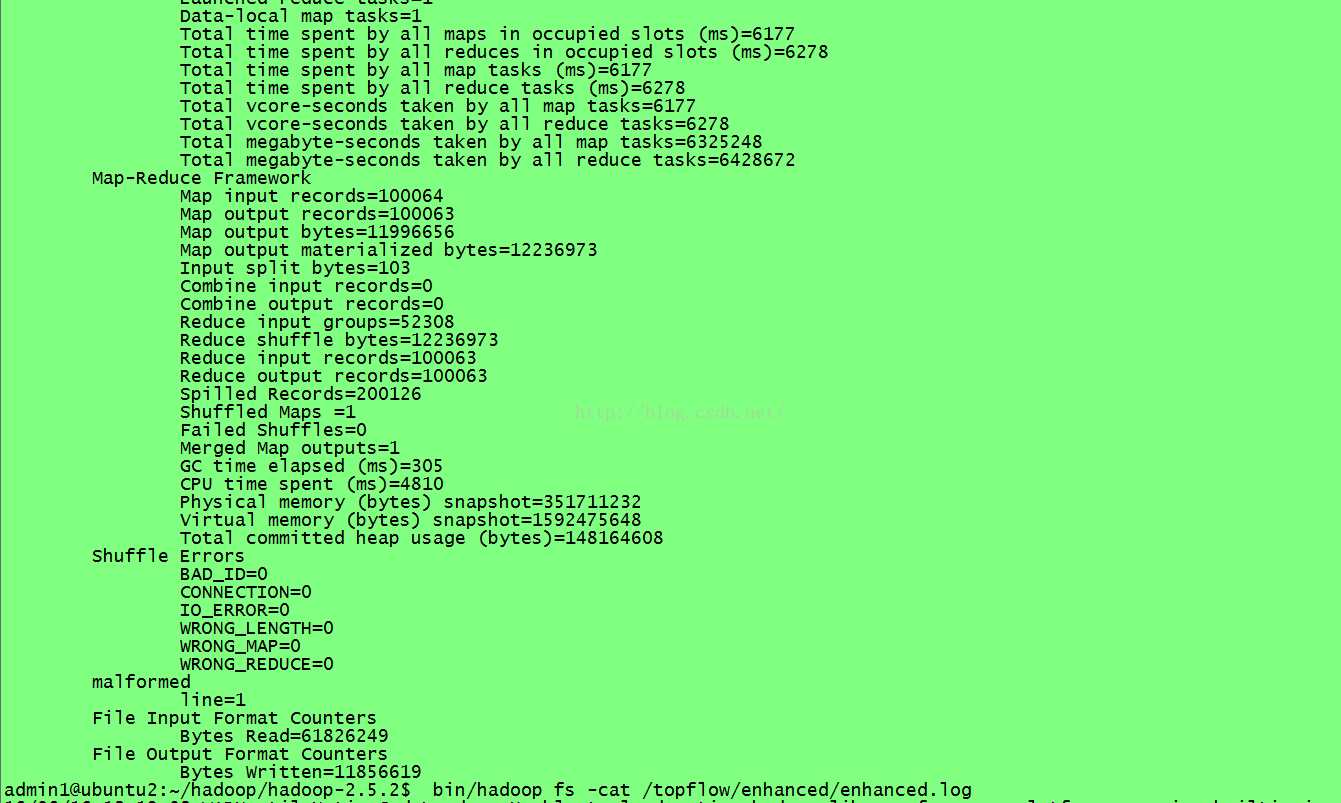
也可以到浏览器中查看:
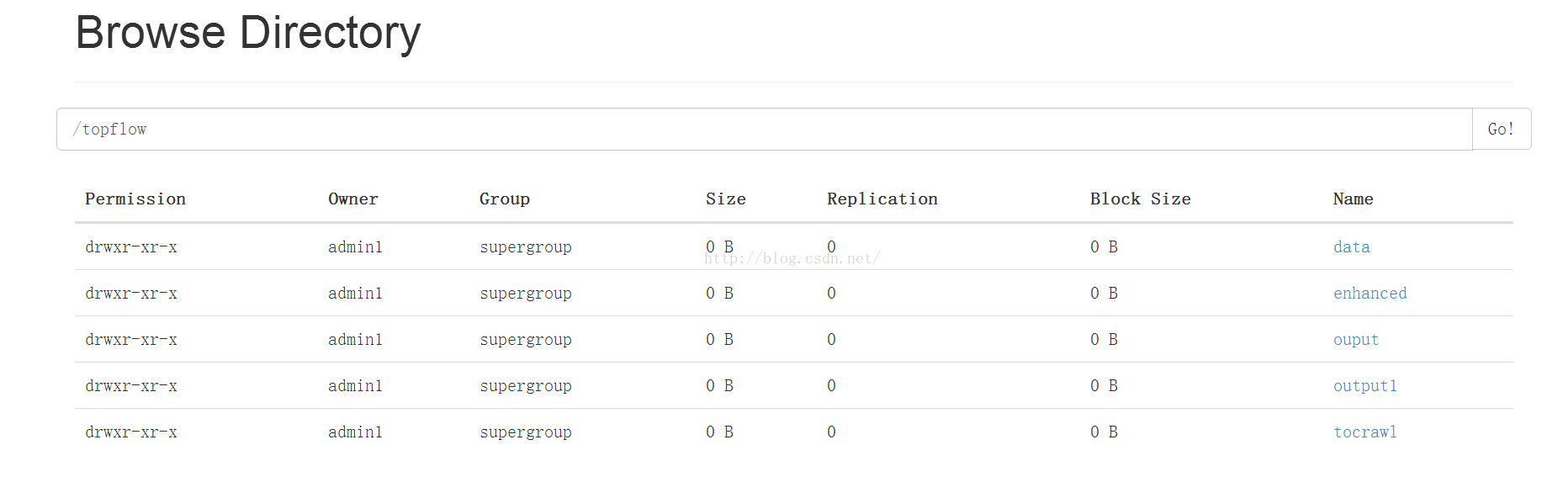
到这里,就在于分享完毕了,按照我分享的这个流量一步步做,我估计要一两天的时间才可以完全做完这个部分!其实总的来说就是过程非常繁琐,不过也正符合我们的实际工作,要知道,我们实际工作中,远超乎这些繁琐流程,中间还会报各种奇奇怪怪的错,有非常多的细节要处理,如果没有耐心,估计都会疯掉,哈哈!
欢迎关注,欢迎在评论区留言!
数据源下载地址:http://download.csdn.net/detail/sdksdk0/9551559















 1086
1086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









