







今天在群里有朋友问到编译器是怎么识别不同数据类型和处理他们的。如果学过汇编或者编译原理应该很好理解。
没学过的话也没关系,这里大概讲解一下。
在计算机内部其实是没有变量类型的,只有由 段地址+偏移地址构成的内存地址 和各种寄存器标识符。
计算机并不知道每个内存地址中存储的是什么数据类型(里面只是一堆由0,1,0,1……构成的数据),这需要用户编写实际的代码告诉他如何去操作这些数据类型。
而编译器在代码编译阶段,根据关键字, 运算符,表达式,函数返回的结果来判断不同的数据类型,并调用相应的算法去处理这些类型。
一下举一个最典型的例子
在32位操作系统中一个int类型占用4个字节, 一个char类型占用1个字节。 无论你对他们进行任何运算(即使数据溢出)计算机只会操作这些数据类型所对应的内存地址
对于int类型来说,计算机会处理int类型对应的4个字节的地址
而对于char类型来说,计算机只会处理他对应的1个字节的地址。
如何证明这种观点是正确的呢? 你可以自己写一段代码来进行一些内部类型转换然后再看看计算机是如何处理了。
首先需要定义一种联合数据类型
typedef unsigned char BYTE;
union MEMORYBUFFER{
int num;
BYTE addr[4];
};我们还需要一个能够打印MEMORYBUFFER内存中实际存储数据的函数如下
void printDataMemoryMap(const MEMORYBUFFER& buff)
{
printf("\t\tBYTE0\t\tBYTE1\t\tBYTE2\t\tBYTE3\n");
printf("Address\t\t%08X\t%08X\t%08X\t%08X\n", &buff.addr[0], &buff.addr[1], &buff.addr[2], &buff.addr[3]);
printf("Value(HEX)\t%02X\t\t%02X\t\t%02X\t\t%02X\n", buff.addr[0], buff.addr[1], buff.addr[2], buff.addr[3]);
}接下来就可以进行试验了
首先,定义一个MEMORYBUFFER的类型的变量 buff, 调用Memset把4个字节的区块清0
MEMORYBUFFER buff;
memset(&buff, 0, sizeof(MEMORYBUFFER));
//print the original Memory Map when you call the memset(0) function.
printDataMemoryMap(buff);结果如下
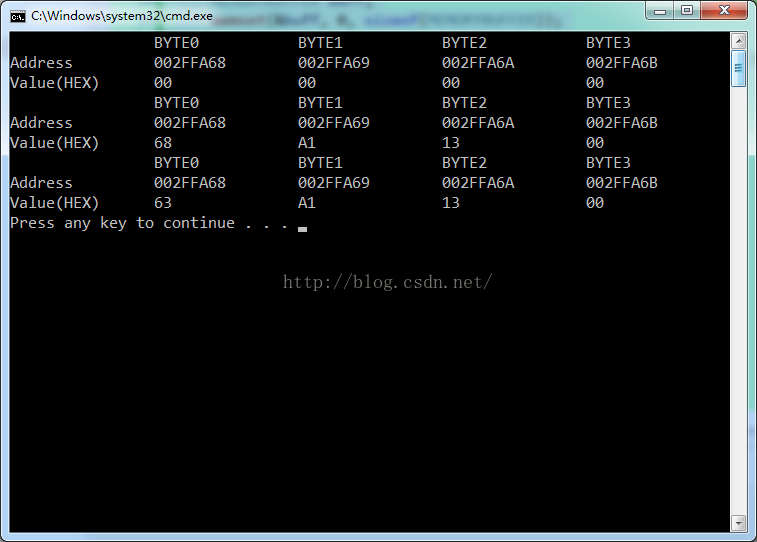
BYTE0 BYTE1 BYTE2 BYTE3
Address 002FFA68 002FFA69 002FFA6A 002FFA6B
Value(HEX) 00 00 00 00
接下来定义一个Int* 类型的指针并指向这块内存区域,然后进行一些数学运算 并打印出结果
int * ptrInt = (int*)&buff;
//Do some mathematical manipulation
*ptrInt = 15 * 20 + 3000 - 21 + 61000 + 1222225;
//print the Memory Map
printDataMemoryMap(buff);结果如下
BYTE0 BYTE1 BYTE2 BYTE3
Address 002FFA68 002FFA69 002FFA6A 002FFA6B
Value(HEX) 68 A1 13 00 //assign the Integer pointer to char pointer
unsigned char *ptrChar = (unsigned char*)&buff;
*ptrChar += 251; //Let the address 0 overflow.
printDataMemoryMap(buff); BYTE0 BYTE1 BYTE2 BYTE3
Address 002FFA68 002FFA69 002FFA6A 002FFA6B
Value(HEX) 63 A1 13 00可以看到结果只有BYTE0 最低位字节的数据发生了变化,其他字节都没有受到影响。
可见这段对char* 类型代码的操作因为告知了编译器char类型只能操作1个字节的内存地址,因此其他位的字节都不会受到影响
同时也证明了,编译器对数据进行某些操作是根据“数据类型”的不同而不同的,而一段内存地址是哪种数据类型是需要用户编写代码来告知编译器的。
参考完整的代码
#include <iostream>
typedef unsigned char BYTE;
union MEMORYBUFFER{
int num;
BYTE addr[4];
};
void printDataMemoryMap(const MEMORYBUFFER& buff)
{
printf("\t\tBYTE0\t\tBYTE1\t\tBYTE2\t\tBYTE3\n");
printf("Address\t\t%08X\t%08X\t%08X\t%08X\n", &buff.addr[0], &buff.addr[1], &buff.addr[2], &buff.addr[3]);
printf("Value(HEX)\t%02X\t\t%02X\t\t%02X\t\t%02X\n", buff.addr[0], buff.addr[1], buff.addr[2], buff.addr[3]);
}
int main()
{
MEMORYBUFFER buff;
memset(&buff, 0, sizeof(MEMORYBUFFER));
//print the original Memory Map when you call the memset(0) function.
printDataMemoryMap(buff);
int * ptrInt = (int*)&buff;
//Do some mathematical manipulation
*ptrInt = 15 * 20 + 3000 - 21 + 61000 + 1222225;
//print the Memory Map
printDataMemoryMap(buff);
//assign the Integer pointer to char pointer
unsigned char *ptrChar = (unsigned char*)&buff;
*ptrChar += 251; //Let the address 0 overflow.
printDataMemoryMap(buff);
return 0;
}运行结果














 442
442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









