






本文主要讨论聚类中聚类个数的确定问题。
本文地址:http://blog.csdn.net/shanglianlm/article/details/46671209
1. K的作用
Intuitively then, the optimal choice of k will strike a balance between maximum compression of the data using a single cluster, and maximum accuracy by assigning each data point to its own cluster.
2. 常用方法
2.1 经验法则(Rule of thumb)
[1] k≈n/2−−−√
2.2 弯形判据 (The Elbow Method)
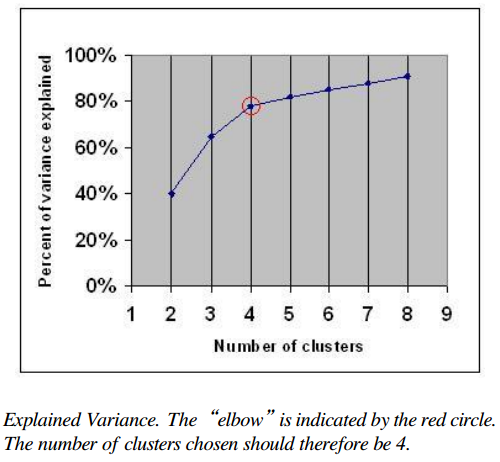
the percentage of variance V.S. the number of clusters
2.3 信息准则(Information Criterion Approach)
[2][3]如果聚类模型能写成一个似然函数(likelihood function)考虑使用:Akaike information criterion (AIC), Bayesian information criterion (BIC), or the Deviance information criterion (DIC)
[4]是关于k-meas的例子。
2.4 (An Information Theoretic Approach)
[5] 率失真理论 (Rate distortion theory)应用于选择k,通过信息理论标准最小化误差的同时最大化效率。 该策略通过运行一个标准的聚类算法为输入数据在k值从1到n生成一个失真曲线(distortion curve),接着基于数据维数选择的a negative power对失真曲线处理,最后寻找跳跃最大的点作为k。
2.5 轮廓(Choosing k Using the Silhouette)
[6][7]
The silhouette of a datum is a measure of how closely it is matched to data within its cluster and how loosely it is matched to data of the neighbouring cluster.
2.6 交叉验证法(Cross-validation)
[8]
2.7 文本数据 (Finding Number of Clusters in Text Databases)
[9] 矩阵 D∈Rn×m m:文本数量, n:项数量,t:D中非零项数量(D每行列至少有一个非零项),有:( m × n )/ t。
2.8 核矩阵 (Analyzing the Kernel Matrix)
不像先前的方法要求先验聚类,[10]直接从数据本身获得聚类个数。
1.形成核矩阵(数据映射到高维空间线性可分)
2.特征值分解核矩阵
3.分析特征值和特征向量
4.画图找弯点(elbow)
参考及引用文献:
[1] [Kanti Mardia et al. (1979). Multivariate Analysis. Academic Press.]
[2] [David J. Ketchen, Jr & Christopher L. Shook (1996). “The application of cluster analysis in Strategic Management Research: An analysis and critique”. Strategic Management Journal 17 (6): 441–458.]
[3] [Cyril Goutte, Peter Toft, Egill Rostrup, Finn Årup Nielsen, Lars Kai Hansen (March 1999). “On Clustering fMRI Time Series” . NeuroImage 9 (3): 298–310.]
[4] [Cyril Goutte, Lars Kai Hansen, Matthew G. Liptrot & Egill Rostrup (2001). “Feature-Space Clustering for fMRI Meta-Analysis” . Human Brain Mapping 13 (3): 165–183.]
[5] [Catherine A. Sugar and Gareth M. James (2003). “Finding the number of clusters in a data set: An information theoretic approach” . Journal of the American Statistical Association 98 (January): 750–763.]
[6] [Peter J. Rousseuw (1987). “Silhouettes: a Graphical Aid to the Interpretation and Validation of Cluster Analysis” . Computational and Applied Mathematics 20: 53–65.]
[7] [R. Lleti, M.C. Ortiz, L.A. Sarabia, M.S. Sánchez (2004). “Selecting Variables for k-Means Cluster Analysis by Using a Genetic Algorithm that Optimises the Silhouettes” . Analytica Chimica Acta 515: 87–100.]
[8] [Finding the Right Number of Clusters in kMeans and EM Clustering: v-Fold Cross-Validation” . Electronic Statistics Textbook. StatSoft. 2010. Retrieved 2010-05-03.]
[9] [Can, F.; Ozkarahan, E. A. (1990). “Concepts and effectiveness of the cover-coefficient-based clustering methodology for text databases” . ACM Transactions on Database Systems 15 (4): 483.]
[10] [Honarkhah, M and Caers, J (2010). “Stochastic Simulation of Patterns Using Distance-Based Pattern Modeling” . Mathematical Geosciences 42 (5): 487–517.]
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











