






Correctness
自然语言处理(NLP),机器学习(ML),信息检索(IR)等领域,评估(Evaluation)是一个必要的工作,而其评价指标往往有如下几点:准确率(Accuracy),精确率(Precision),召回率(Recall)和F1-Measure。
- True positive: “是垃圾邮件,预测也是垃圾邮件”。
- False positive(Error):”不是垃圾邮件,预测却是垃圾邮件”。
- False negative(Error):”是垃圾邮件,预测却不是垃圾邮件”。
- True negative:”不是垃圾邮件,预测也不是垃圾邮件”。
我们常常使用混淆矩阵(confusion matrix)表示:
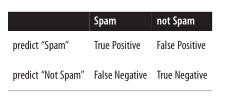
准确度(accuracy)的公式是 A=(TP+TN)/(TP+TN+FP+FN) ,它计算的是对于给定的测试数据集,分类器正确分类的样本数与总样本数之比。
def accuracy(tp, fp, fn, tn):
correct = tp + tn
total = tp + fp + fn + tn
return correct / total
print accuracy(70, 4930, 13930, 981070)精确率(precision)的公式是 P=TP/(TP+FP) ,它计算的是所有”正确被预测的item(TP)”占所有”实际被预测到的(TP+FP)”的比例。
def precision(tp, fp, fn, tn):
return tp / (tp + fp)
print precision(70, 4930, 13930, 981070) # 0.014召回率(recall)的公式是 R=TP/(TP+FN) ,它计算的是所有”正确被预测的item(TP)”占所有”应该预测到的item(TP+FN)”的比例。
def recall(tp, fp, fn, tn):
return tp / (tp + fn)
print recall(70, 4930, 13930, 981070) f1_score的公式是 F1=2PR/(P+R) ,它计算的是精确度和召回度的调和平均数( harmonic mean),其值必定在两者之间。
def f1_score(tp, fp, fn, tn):
p = precision(tp, fp, fn, tn)
r = recall(tp, fp, fn, tn)
return 2 * p * r / (p + r)通常一个模型的选择设计到在精确度与召回度之间进行权衡。你能把这种操作看成是FP与FN之间的一种权衡,预测“yes”太多,会让你有很多的FP;预测“no”太多会让你有很多FN。
设想一下,你有10个危险指标来预测白血病,你拥有这些指标越多,你就越有可能患有白血病。例如,你能做这样的一组连续实验:“如果你只拥有一个危险指标,预测你得白血病”;“如果你拥有二个指标,预测你得白血病”,随着阈值的升高,你的精确度也会增加(由于拥有的危险指标越多,越能检测出疾病),同时召回度降低(由于真正患者越来越难达到阈值),所以选择一个合适的阈值是至关重要的。















 2670
2670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









