







一. HDFS概述
1.HDFS是什么?
- 源自于Google的GFS论文
- 发表于2003年10月
- HDFS是GFS克隆版
- Hadoop Distributed File System
- 易于扩展的分布式文件系统
- 运行在大量普通廉价机器上,提供容错机制
- 为大量用户提供性能不错的文件存取服务
2.HDFS优缺点
优点
- 高容错性
- 数据自动保存多个副本
- 副本丢失后,自动恢复
- 适合批处理
- 移动计算而非数据
- 数据位置暴露给计算框架
- 适合大数据处理
- GB、 TB、甚至PB级数据
- 百万规模以上的文件数量
- 10K+节点规模
- 流式文件访问
- 一次性写入,多次读取
- 保证数据一致性
- 可构建在廉价机器上
- 通过多副本提高可靠性
- 提供了容错和恢复机制
缺点
- 低延迟数据访问
- 比如毫秒级
- 低延迟与高吞吐率
- 小文件存取
- 占用NameNode大量内存
- 寻道时间超过读取时间
- 并发写入、文件随机修改
- 一个文件只能有一个写者
- 仅支持append
二. HDFS基本架构和原理
1.HDFS设计思想
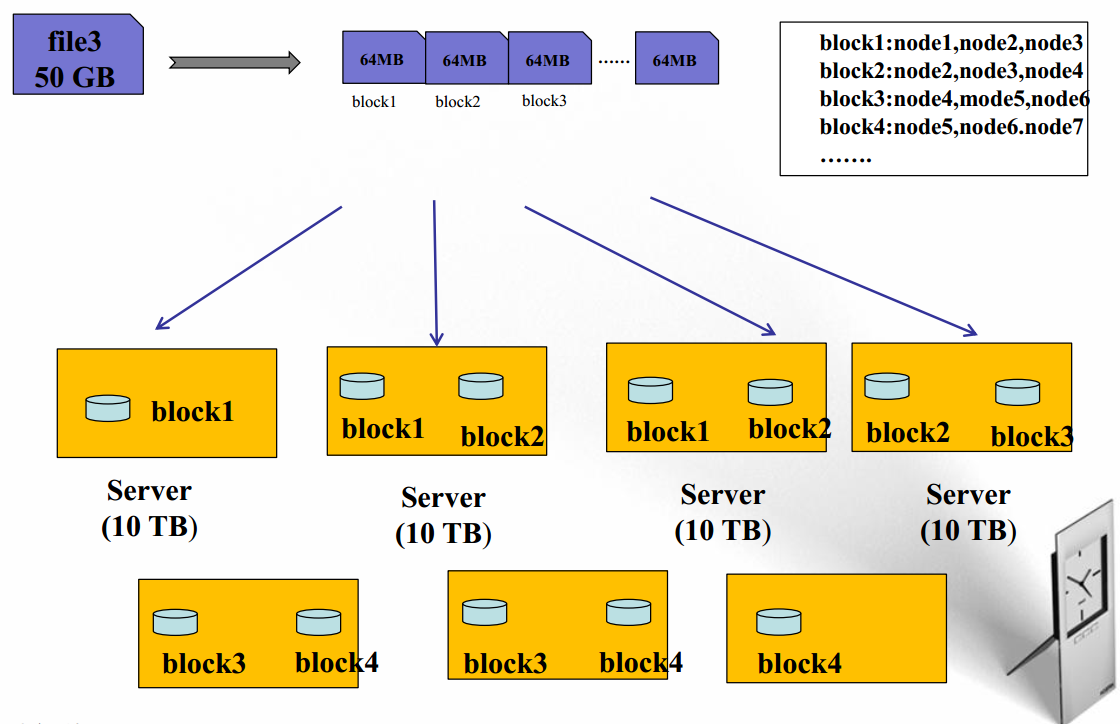
解释:从HDFS的设计思想上可知,HDFS最适合处理大容量的单个数据,可以将该数据分成n个block,每个block是64M,每个block存取多份,具体份数是通过hdfs-site.xml文件中的fs.replication配置,而且每个block存取的节点不能完全重叠,但要保证最终可以合成原文件。
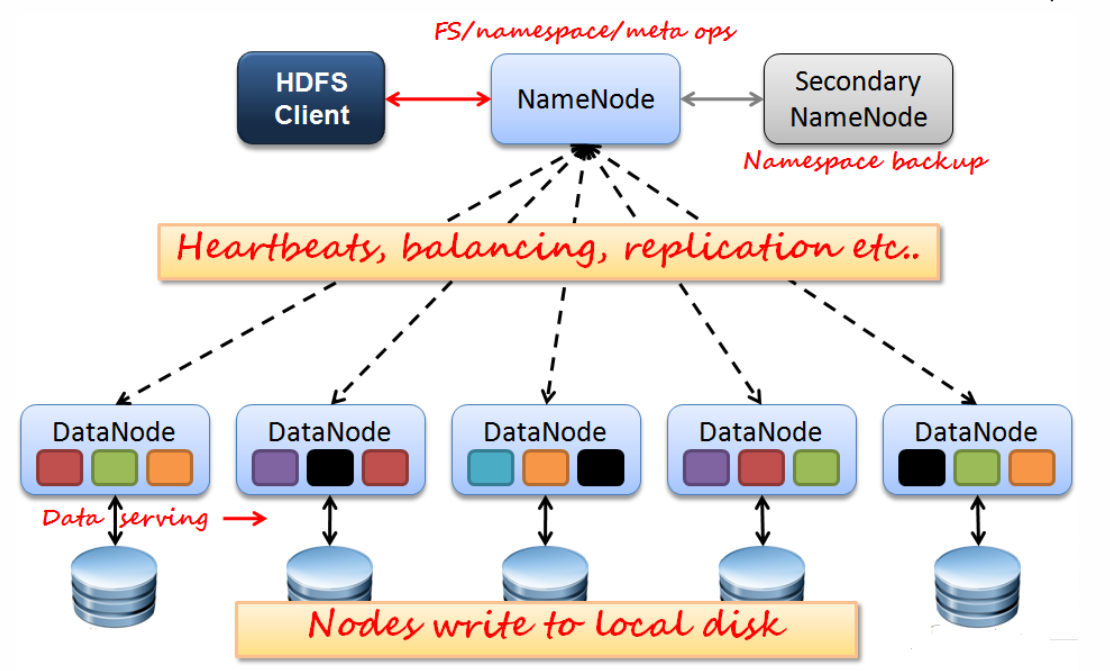
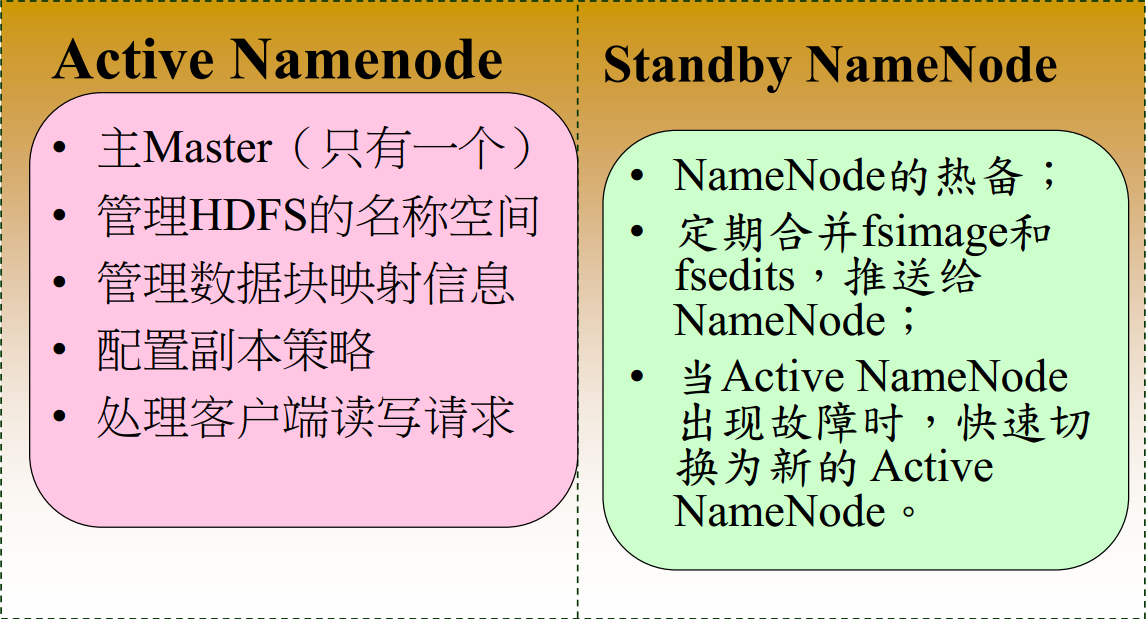
2.HDFS架构
3.HDFS数据块(block)
- 文件被切分成固定大小的数据块
- 默认数据块大小为64MB,可配置
- 若文件大小不到64MB,则单独存成一个block
- 为何数据块如此之大
- 数据传输时间超过寻道时间(高吞吐率)
- 一个文件存储方式
- 按大小被切分成若干个block,存储到不同节点上
- 默认情况下每个block有三个副本
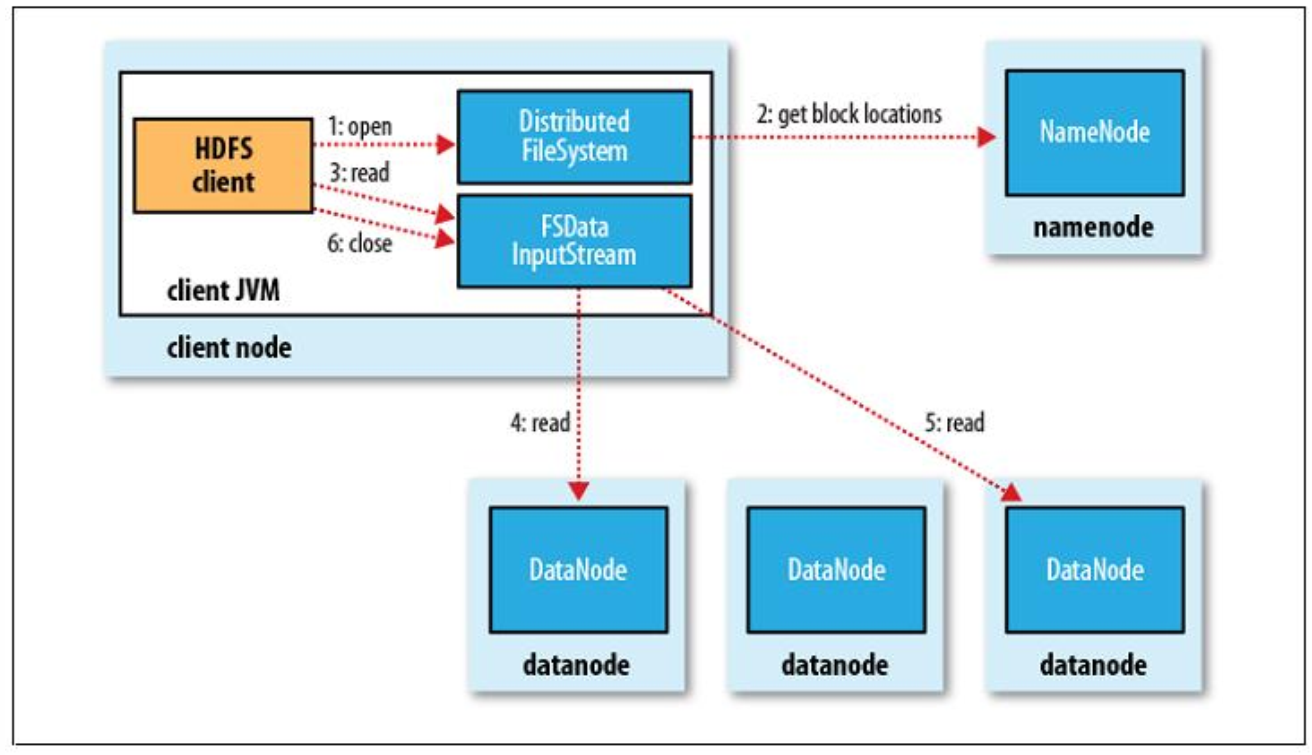
4.HDFS读写流程
读流程
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 459
459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









