







 本文介绍了聚类算法的应用和几种常见的方法,包括层次聚类、K均值算法和CURE算法。层次聚类分为凝聚式和分裂式,点分配法则通过将点分配到最近的簇中。K均值算法在欧式空间中使用,通过迭代寻找质心直到收敛。CURE算法不依赖于簇的特定形状,使用代表点来表示簇。
本文介绍了聚类算法的应用和几种常见的方法,包括层次聚类、K均值算法和CURE算法。层次聚类分为凝聚式和分裂式,点分配法则通过将点分配到最近的簇中。K均值算法在欧式空间中使用,通过迭代寻找质心直到收敛。CURE算法不依赖于簇的特定形状,使用代表点来表示簇。
Clustering
Overview of methods
首先我们说几个典型应用,了解为什么需要聚类算法,然后介绍下聚类的集中方法,具体的细节在后面的小节中详细说。

但是在实际应用中,聚类问题并没有图中这么简单,往往有大量的数据,且数据时高维的(10 or 10,000dimensions)处理起来比较复杂,而且在高维空间中点间的距离看起来都是近似的。
Some Clustering Applications
- clustering sky objects
- clustering CD’s
- clustering documents
聚类分析试图将相似对象归入同一簇,将不相似的对象归到不同簇。相似这一概念取决于所选的相似度计算方法,到底使用哪种相似度计算方法取决于具体应用。
Distance Measurement
对物品的不同表示方法,对应的距离度量方式也不同:

Overview:Methods of Clustering
- 层次法(Hierarchical)
- 凝聚式Agglomerative (bottom up)
每个点都初始化为一个“簇”,重复地将具有最近距离的两个簇合并成一个 - 分裂式Division (top down)
将整个分布作为一个簇,然后根据距离重复分裂为不同的簇
- 凝聚式Agglomerative (bottom up)
- 点分配法(Point Assignment)
保留一些列的簇,将点划分到距离最近的簇中。
层次聚类(Hierarchical Clustering)
我们主要讲凝聚式的层次聚类。仅适用于小型数据集。
主要操作:重复地将距离最近的簇进行合并操作。
因此,对于层次聚类算法,我们必须确定一下几个问题:
Three Problems:
- 簇如何表示?
- 如何选择进行合并的簇?
- 簇的合并操作合适停止(停止条件)?
首先我们从较简单的欧式空间讨论层次聚类问题,然后一一解答上面的问题。
欧式空间
1. 在欧式空间中用质心(centroid)来表示簇,即簇中点的平均。
2. 计算簇的质心间的距离来表示簇间距离
3. 我们可以聚类到只剩一个簇为止,然而返回一个簇并没有实际意义,但是,合并的过程可以通过树形来表示,这种合并过程的表示往往具有很强的实际意义。当然,我们也可以通过实现指定簇的数目或者是指定最小确信距离等方法来确定停止条件。具体地后面讲解。
非欧式空间
在非欧式空间中,点集没有质心的概念,因此无法通过质心来表示cluster,因此我们从簇中选择一个点来代表簇,该点应该是距离簇内所有的点最近的点,称之为簇的中心(clustroid)。
然后簇间的距离计算和质心的距离计算一样,通过计算中心点间的距离来表示簇间距离。
下面这张图可以形象地说明质心和中心的区别:
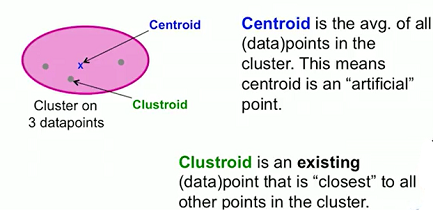
那么我们如何来定义这个中心点呢?
我们说clustroid = point “closest” to other points. 那么我们如何定义这个closest呢?
选择中心点的方法,使得选出的点如下值最小 :
- 该点到簇中另外一点的最大距离(maximum)
- 该点到簇中其它各点的平均距离(avg)
- 该店到簇中其它各点的距离平方和(sum of squares)
前面我们已经讨论了前两个问题的解决,下面我们说第三条,也就是簇合并的停止条件如何确定。
停止条件(Termination Condition)
- 选择k个簇,当合并到k个时停止。前提是我们确信数据集的簇的数目。
- 如果在某个点时,现有簇的最佳合并会产生一个不恰当的簇时停止合并。i.e, a “bad” cluster.这里对于簇的好坏使用”cohesion“进行度量,当低于某个cohesion值时则认为是不恰当的簇。
Cohesion的定义
- 簇的直径:簇中任意两点之间的最大距离
我们可以设置为,当合并后的簇的直径大于某个阈值时,停止合并,半径同理。 - 簇的半径:簇中任意一点到质心(中心)的最大距离
- 基于密度的方法:簇的单位体积中点的数目。
当密度低于某个阈值时停止合并。
Implementation
定义两个簇的距离为两个簇中所有点对之间的平均距离,其中计算距离的两个点分别属于不同的簇。然后选取距离最近的合并。
时间复杂度为 O(N3)
使用优先队列进行优化后能减少到 O(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1765
1765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









