







 随机模拟方法,又称蒙特卡罗方法,是一种利用随机数(或更准确地说是伪随机数)来解决各种问题的技术。这种方法适用于确定性算法不易求解或无法求解的问题,通过计算机模拟获取近似解。文章介绍了随机模拟的基本思路,包括建立概率统计模型、进行模拟试验和分析结果。接着,详细讨论了蒙特卡罗方法在圆周率计算和积分中的应用。此外,还探讨了常见的采样方法,如直接采样、接受-拒接采样、重要性采样和MCMC采样,特别是马尔科夫链的基础、Metropolis-Hastings算法以及Gibbs Sampling。Gibbs Sampling在高维空间的贝叶斯分析中具有重要意义。最后,文章提到了MCMC方法的收敛性判断和一些检查方法。
随机模拟方法,又称蒙特卡罗方法,是一种利用随机数(或更准确地说是伪随机数)来解决各种问题的技术。这种方法适用于确定性算法不易求解或无法求解的问题,通过计算机模拟获取近似解。文章介绍了随机模拟的基本思路,包括建立概率统计模型、进行模拟试验和分析结果。接着,详细讨论了蒙特卡罗方法在圆周率计算和积分中的应用。此外,还探讨了常见的采样方法,如直接采样、接受-拒接采样、重要性采样和MCMC采样,特别是马尔科夫链的基础、Metropolis-Hastings算法以及Gibbs Sampling。Gibbs Sampling在高维空间的贝叶斯分析中具有重要意义。最后,文章提到了MCMC方法的收敛性判断和一些检查方法。
随机模拟方法简介
随机模拟方法又称为蒙特卡罗方法(Monte Carlo Method)。蒙特卡洛模拟方法的原理是当问题或对象本身具有概率特征时,可以用计算机模拟的方法产生抽样结果,根据抽样计算统计量或者参数的值;随着模拟次数的增多,可以通过对各次统计量或参数的估计值求平均的方法得到稳定结论。由于涉及到时间序列的反复生成,蒙特卡洛模拟法是以高容量和高速度的计算机为前提条件的,因此只是在近些年才得到广泛推广。
从上面的描述我们不难看出随机模拟方法主要是针对那些确定算法不好解或者解不出来的情况。因此是一种典型的寻求近似解的方法。
基本思路
针对实际问题建立一个简单易行的概率统计模型,使问题所求的解为该模型的概率分布或者数字特征,比如:某个事件的概率或者是某个随机变量的期望值。
对模型中的随机变量建立抽样方法,在计算机上进行模拟试验,得到足够的随机抽样,并对相关事件进行统计
对试验结果进行分析,给出所求解的估计及其精度(方差)的估计
蒙特卡罗方法在数学中的应用
通常蒙特卡洛方法通过构造匹配一定规则的随机数来解决数学上的各种问题。对于那些由于计算过于复杂而难以得到解析解或者根本没有解析解的问题,蒙特卡洛方法是一种有效的求出数值解的方法。一般蒙特卡洛方法在数学中最常见的应用就是蒙特卡洛积分。下面是蒙特卡罗方法的两个简单应用:
圆周率
蒙特卡洛方法可用于近似计算圆周率:让计算机每次随机生成两个0到1之间的数,看以这两个实数为横纵坐标的点是否在单位圆内。生成一系列随机点,统计单位圆内的点数与总点数,(圆面积和正方形面积之比为PI:4,PI为圆周率),当随机点获取越多时,其结果越接近于圆周率(然而准确度仍有争议:即使取10的9次方个随机点时,其结果也仅在前4位与圆周率吻合)。用蒙特卡洛方法近似计算圆周率的先天不足是:第一,计算机产生的随机数是受到存储格式的限制的,是离散的,并不能产生连续的任意实数;上述做法将平面分区成一个个网格,在空间也不是连续的,由此计算出来的面积当然与圆或多或少有差距。
蒙特卡罗积分
举个简单的例子,假设我们要求f(x)的积分 ∫baf(x)dx
但是f(x)的形式比较复杂不好求积分,使用蒙特卡罗积分方法转化为 ∫baf(x)q(x)q(x)dx
把q(x)看作是x在区间[a,b]内的概率分布,前面的分数部分看做一个函数,然后再q(x)下抽取n个样本,当n足够大时,可以利用均值来近似(大数定理), 1n∑if(xi)p(xi)
因此只要q(x)比较容易采样就行。
随机模拟三个要素:随机数,逻辑模型,反复试验。其基本思路就是要把待解决的问题转化为一种可以通过某种采样方法可以解决的问题,因此随机模拟方法的核心就是如何对一个概率分布得到样本,即抽样(sampling)。
常见的采样方法
直接采样
通过对均匀分布采样,实现对任意分布采样。
一般而言均匀分布 Uniform(0,1)的样本是相对容易生成的。 通过线性同余发生器可以生成伪随机数,我们用确定性算法生成[0,1]之间的伪随机数序列后,这些序列的各种统计指标和均匀分布 Uniform(0,1) 的理论计算结果非常接近。这样的伪随机序列就有比较好的统计性质,可以被当成真实的随机数使用。
而我们常见的概率分布,无论是连续的还是离散的帆布,都可以基于Uniform(0,1)的样本生成。
直接采样步骤:
- 从Uniform(0,1)随机产生一个样本z
- 另z=h(y),其中h(y)为y的累积概率分布CDF
- 计算 y=h−1(z)
- 结果y为对p(y)的采样
注:需要知道累积概率分布的解析表达式,且累积概率分布函数存在反函数
但是如果h(x)不能确定或者没有无法解析求逆则直接抽样不再合适。对于复杂的现实模型其实是不常用的。
接受-拒接采样
简称拒绝采样,基本思想:假设我们需要对一个分布f(x)进行采样,但是却很难直接进行采样,所以我们想通过另外一个容易采样的分布g(x)的样本,用某种机制去除掉一些样本,从而使得剩下的样本就是来自与所求分布f(x)的样本。
- 给定目标分布密度 π(x)
- 建议密度(proposal density)q(x)和常数M,使得
对q(x)采样比较容易
q(x)的形状比较接近 π(x)
对任意x,有 π(x)≤Mq(x)(包络原则) - 通过对q(x)采样实现对 π(x) 采样
采样过程:
产生样本 X∼q(x),和U∼Uniform[0,1]
若 U≤π(X)/Mq(x),则接受X ,接受的样本服从分布 π(x)
等价于:
Y=Mq(X)U,若Y≤π(X) ,则接受X
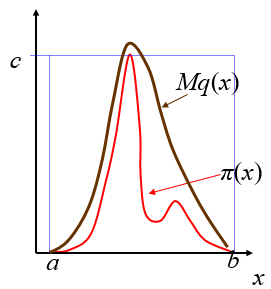
在高维空间,接受-拒绝采样会出现两个问题,一是合适的proposal density q(x)比较难找,而是很难确定一个准确的M值。这两个问题会导致拒绝率很高,无用计算增加。
重要性采样
通过从已知采样的概率q(x)采样,近似积分
I=∫f(x)π(x)dx=∫f(x)π(x)q(x)q(x)dx
从q(x)中抽取N个样本,上述式子就约等于 1N∑Nif(xi)π(xi)q(xi) 。这相当于给每一个样本赋予了一个权重 w(xi)=π(xi)q(xi)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1282
1282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









