







第一部分(必做):计算机基础类(25分)
(所有选择题都是多项选择)
1.(2分)假设进栈次序是e1,e2, e3, e4,那可能的出栈次序是()
A、e2, e4, e3, e1 B、e2, e3, e4, e1 C、e3, e2, e4, e1 D、e1, e2, e4, e3.
解析:随手画一下就可以找到答案。
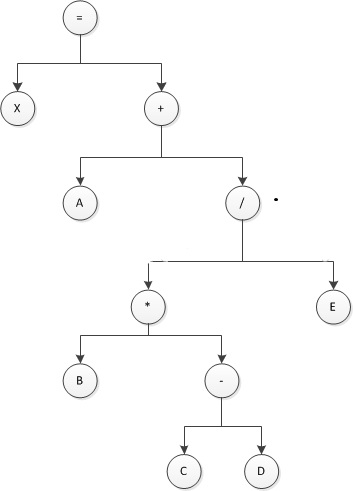
2.(2分)表达式X=A+B*(C-D)/E的后缀表示形式可以是()
A、XAB+CDE/-*= B、XA+BC-DE/*= C、XABCD-*E/+= D、XABCDE+*/=
解析:前缀表达式(Prefix Notation)是指将运算符写在前面操作数写在后面的不包含括号的表达式,也叫做波兰表达式,对应于二叉树的前序遍历。
后缀表达式(Postfix Notation)与之相反,是指运算符写在操作数后面的不包含括号的算术表达式,也叫做逆波兰表达式,对应于二叉树的中序遍历 。
中缀表达式(Infix Notation)就是常用的将操作符放在操作数中间的算术表达式。前缀表达式和后缀表达式相对于中缀表达式最大的不同就是去掉了表示运算符优先级的括号,二叉树的后序遍历。
所以这道题的做法就是先根据表达式写出树的结构,然后写出二叉树的后续遍历。
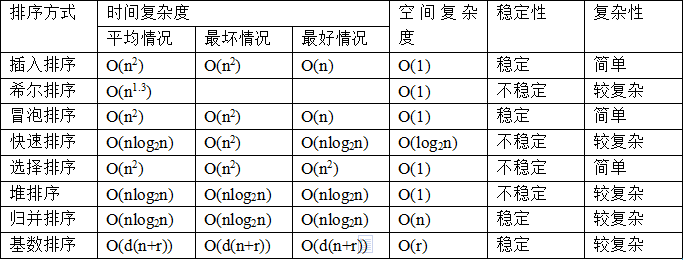
3.(2分)以下排序算法是非稳定排序的是()
A、冒泡排序 B、归并排序 C、快速排序 D、堆排序 E、希尔排序
解析:排序算法稳定性:保证排序前两个相等的数据其在序列中的先后位置顺序与排序后它们两个先后位置顺序相同。然后就是下面的这个表。
4.(2分)一个包含n个结点的四叉树,每一个节点都有4个指向孩子节点的指针,这4n个指针有(3n+1)个空指针。
解析:一共4n个指针,除去根节点,其它节点都要有指针指,则空指针有 4n - (n-1) = 3n+1。
5.(2分)
int func(unsigned int i)
{
unsigned int temp = i;
temp = (temp & 0x55555555) + ((temp & 0xaaaaaaaa)>>1);
temp = (temp & 0x33333333) + ((temp & 0xcccccccc)>>2);
temp = (temp & 0x0f0f0f0f) + ((temp & 0xf0f0f0f0)>>4);
temp = (temp & 0xff00ff) + ((temp & 0xff00ff00)>>8);
temp = (temp & 0xffff) + ((temp & 0xffff0000)>>16);
return temp;
}请问func(0x7f530829)的返回值是()
A、15 B、16 C、17 D、18
解析:求数的二进制表示中1的个数的“平行算法”,思路就是先将n写成二进制形式,然后相邻位相加,重复这个过程,直到只剩下一位。
0x7f530829写成二进制是0111 1111 0101 0011 0000 1000 0010 1001,数一下。
6.(2分)进程和线程的差别有()
A、操作系统只调度进程,不调度线程
B、线程共享内存地址空间,进程不共享
C、线程可以共享内存数据,但进程不可以
D、进程间可以通过IPC通信,但线程不可以
解析:在操作系统设计上,从进程演化出线程,进程和线程都可以调度;线程之间的通信只有通过读写同一个地址空间的内存来完成,进程间也可以用共享内存来通信。
7.(2分)关于段页式管理中,地址映像表是()
A、每个进程一张段表,一张页表 B、进程的每个段一张段表,一张页表
C、每个进程一张段表,每段一张页表 D、每个进程一张页表,每段一张段表
解析:段页式内存管理是基本分段存储管理方式和基本分页存储管理方式原理的结合,即先将用户程序分成若干个段,再把每个段分成若干个页,并为每一个段赋予一个段名。
8.(2分)关于TCP协议,下面哪种说法是错误的()
A、TCP关闭连接过程中,两端的socket都会经过TIME_WAIT状态
B、对一个Established状态的TCP连接,调用shutdown函数可以让主动调用的一方进入半关闭状态
C、TCP协议默认保证了当TCP的一端发生意外崩溃(当机、网线断开或路由器故障),另一端能自动检测到连接失效
D、在成功建立连接的TCP上,只有在Established状态才能收发数据,其他状态都不可以。
解析:A不对,只有sever端才会出现TIME_WAIT状态,如下图:
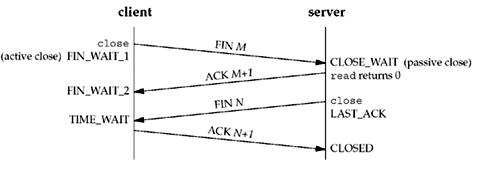
C不对,当TCP连接发生一些物理上的意外情况时,例如网线断开,linux上的TCP实现会依然认为该连接有效,而windows则会在一定时间后返回错误信息。
9.(2分)关于主键PrimaryKey和索引index的说法哪些是错误的?()
A、唯一索引的列允许为NULL值
B、一个关系表中的外键必定是另一表中的主键
C、一个表中只能有一个唯一性索引
D、索引主要影响查询过程,对数据的插入影响不大
解析:B不对,一定是主键或者唯一键;
C不对,关于主键和唯一索引:
1.主键一定是唯一性索引,唯一性索引并不一定就是主键;
2.一个表中可以有多个唯一性索引,但只能有一个主键;
3.主键列不允许空值,而唯一性索引列允许空值。
10.(2分)数据库的事务隔离级别一般分为4个级别,其中可能发生“不可重复读”的事务级别有()
A、SERIALIZABLE
B、READ COMMITTED
C、READ UNCOMMITTED
D、REPEATABLE READ
解析:四个级别
串行化(SERIALIZABLE):所有事务都一个接一个地串行执行,这样可以避免幻读(phantom reads)。对于基于锁来实现并发控制的数据库来说,串行化要求在执行范围查询(如选取年龄在10到30之间的用户)的时候,需要获取范围锁(range lock)。如果不是基于锁实现并发控制的数据库,则检查到有违反串行操作的事务时,需要滚回该事务。
可重复读(REPEATABLE READ):所有被Select获取的数据都不能被修改,这样就可以避免一个事务前后读取数据不一致的情况。但是却没有办法控制幻读,因为这个时候其他事务不能更改所选的数据,但是可以增加数据,因为前一个事务没有范围锁。
读已提交(READ COMMITED):被读取的数据可以被其他事务修改。这样就可能导致不可重复读。也就是说,事务的读取数据的时候获取读锁,但是读完之后立即释放(不需要等到事务结束),而写锁则是事务提交之后才释放。释放读锁之后,就可能被其他事物修改数据。该等级也是SQL Server默认的隔离等级。
读未提交(READ UNCOMMITED):这是最低的隔离等级,允许其他事务看到没有提交的数据。这种等级会导致脏读(Dirty Read)。
11.(5分)如果F(n)为该数列的第n项,那么这句话可以写成如下形式:
F(1)=1,F(2)=1,F(n)=F(n-1)+F(n-2)(n>=3)
请实现该函数F(n)的求解,并给出算法复杂度,要求算法复杂度小于O(n^2)。
解析:肯定不能呢个用递归了~那个算法基本是每个Fibnac数求解了一遍又一遍,下面是最简单的迭代实现。
int Fib(int index)
{
if(index<1)
{
return-1;
}
int a1=1,a2=1,a3=1;
for(int i=0;i<index-2;i++)
{
a3=a1+a2;
a1=a2;
a2=a3;
}
return a3;
}第二部分(必做):程序设计(25分)
1.(2分)下面的程序的输出是什么?
#include<stdio.h>
int main()
{
int n;
char y[10] = “ntse”;
char*x = y;
n= strlen(x);
*x= x[n];
x++;
printf(“x=%s\n”,x);
printf(“y=%s\n”,y);
}x=tse
y=
解析:char *x = y之后,x和y都只想一个10字节的内存空间,前4个字节中放的是ntse,第五个字节放的是/0,后面都是空的。n = strlen(x),得到n=4。*x=x[n],将数组第一个元素换为x[4],即/0,x++,x指向的是数组的第二个空间。内存布局如下:
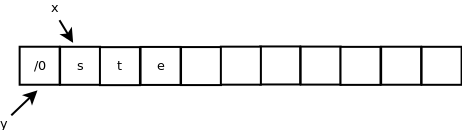
2.(2分)请给出下面程序的输出结果,并说明原因。
#include<vector>
#include<iostream>
using namespace std;
template<class t>
class array{
public:
array(int size);
size_t getVectorSize() {return _data.size();}
size_t getSize() {return _size;}
private:
vector<t> _data;
size_t _size;
};
template<class t>
array<t>::array(int size):_size(size),_data(_size)
{ }
int main()
{
array<int>*arr= new array<int>(3);
cout<<arr->getVectorSize()<<endl;
cout<<arr->getSize()<<endl;
return 0;
}0
3
解析:主要考察构造函数列表,看上去首先是_size赋值为3,然后用_size作为参数构造vector.BUT!
类成员的初始化顺序是和成员在类中的声明顺序一致的!所以_data是在_size之前就初始化好了,调用的默认构造函数,所以里面没有元素。
编译器:gcc4.7
3.(2分)CAS(CompareAndSwap),是用来实现lock-free编程的重要手段之一,多数处理器都支持这一原子操作,其用伪代码描述如下:
template bool CAS(T* addr, T expected, Tvalue)
{
if(*addr== expected){
*addr= value;
return true;
}
return false;
}请完成下面填空,实现全局计数器的原子递增操作。
int count = 0;
void count_atomic_inc(int *addr)
{
int oldval = 0;
int newval = 0;
do{
oldval= *addr;
newval= + 1;
}until CAS( , , )
}解析:CAS的原理是,将旧值与一个期望值进行比较,如果相等,则更新旧值,类型T = {char, short, int, __int64, ...}等,以及指针(pointer to any type)。
until 等价于while(!XX)
详解无锁的数据结构(Lock-Free)及CAS(Compare-and-Swap)机制
4.(2分)下面的程序会输出几个“-”?
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int main(void)
{
int i;
for(i=0;i<2;i++){
fork();
printf(“-”);
fflush(stdout);
}
return 0;
}6
解析:把循环展开
fork();
printf(“-”);
fflush(stdout);
fork();
printf(“-”);
fflush(stdout);假设最开始的进程树是p0
则进程树如下:
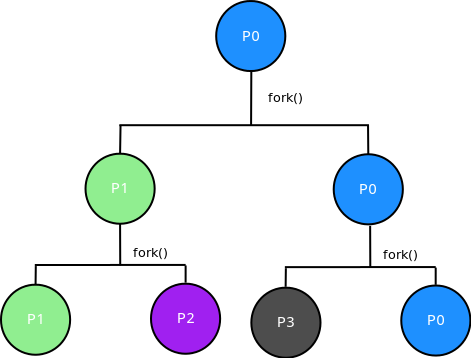
fork之后的代码父进程和子进程都会执行。
注意fflush,没有这句话的情况结果还不同。参考一个fork的面试题。
5.(4分)写程序判断当前CPU是大端CPU还是小端CPU,并做简要说明。
最简单的方式就是利用union的特性,由于联合的大小和最大成员的大小一样,里面的成员是共享存储空间的。
int checkCPU( ){
union w {
int a;
char b;
} c;
c.a = 1;
return(c.b ==1);
}解析:
大端格式:在这种格式中,字数据的高字节存储在低地址中,而字数据的低字节则存放在高地址中,
小端格式:与大端存储格式相反,在小端存储格式中,低地址中存放的是字数据的低字节,高地址存放的是字数据的高字节。
现在主流的CPU,intel系列的是采用的little endian的格式存放数据,而motorola系列的CPU采用的是big endian,ARM则同时支持 big和little,网络编程中,TCP/IP统一采用大端方式传送数据,所以有时我们也会把大端方式称之为网络字节序。
C/C++语言编写的程序里数据存储顺序是跟编译平台所在的CPU相关的,而 JAVA编写的程序则唯一采用big endian方式来存储数据。
6.(5分)利用位运算实现两个整数的加法运算,请代码实现,并做简要说明。
int Add(int a, int b)
{
int sum = a ^ b;
int carry = a & b;
while (carry != 0) {
a = sum;
b = carry << 1;
sum = a ^ b;
carry = a & b;
}
return sum;
}首先用sum记录a和b二进制中不同的位置为1(异或运算,不同为1),carry记录相同位为1(与运算,相同为1得1),这时候a+b就可以化为sum+(carry<<1),不断将carry右移,当carry为0的时候,sum的值就是最终结果。
参照剑指offer 47不用加减乘除做加法
7.(8分)图深度遍历问题

a) 写出上述图的深度优先遍历的顺序(遍历起点是节点1)
12485367
解析:深度遍历思想
(1)访问初始顶点v并标记顶点v已访问。
(2)查找顶点v的第一个邻接顶点w。
(3)若顶点v的邻接顶点w存在,则继续执行;否则回溯到v,再找v的另外一个未访问过的邻接点。
(4)若顶点w尚未被访问,则访问顶点w并标记顶点w为已访问。
(5)继续查找顶点w的下一个邻接顶点wi,如果v取值wi转到步骤(3)。直到连通图中所有顶点全部访问过为止。
b) 若用邻接矩阵Matrix存储该矩阵,写出该矩阵

解析:设G=(V,E)是具有n个顶点的图,则G的邻接矩阵是具有如下性质的n阶方阵:

c) 若用非递归方式实现深度优先遍历,请叙述大致的实现思想
用一个顺序栈来记录访问过的顶点。
d) 用你熟悉的任何语言实现非递归深度优先遍历
void DFS( int v)
{
cout << " v"<< v ;
int top = -1 ;
visited[v] = true ;
stack[++top] = v ;
while ( top != -1)
{
v = stack[top] ;
for (int i = 0 ; i < MAX_NODE ; i++)
{
if (Matric[v][i] == 1 &&!visited[i])
{
cout << " v" << i ;
visited[i] = true ;
stack[ ++top ] = i ;
break ;
}
}
if( i == MAX_NODE)
{
top -- ;
}
}
} 第三部分(选做):C++开发工程师必做,其他选做(15分)
1.(6分)给定一个巨大的文本文件,写一个程序随机输出文件任意k行(k不大,k行能放入内存),要求每一行出现概率相等,请给出核心算法,算法复杂度以及简要的算法原理说明。
先选中前k个,从第k+1个元素到最后一个元素为止,以1/i(i = k+1,k+2,...,N)的概率选中第i个元素,并且随机替代掉一个原先选中的元素,这样一直遍历完所有的元素之后,得到k个元素。可以保证最后都是随机获取。
原理:每次都是以 k/i 的概率来选择。
证明:假设n-1时候成立,即前n-1个数据被返回的概率都是1/n-1,当前正在读取第n个数据,以1/n的概率返回它。那么前n-1个数据中数据被返回的概率为:(1/(n-1))*((n-1)/n)= 1/n,假设成立。
参考google蓄水池算法。
2.(9分)Spin Lock是一种较为常见与使用的互斥方法,下面是一种其实现方式:
typedef int lock_t
void initlock(void volatile lock_t*lock_status){
*lock_status= 0;
}
void lock(void volatile lock_t* lock_status){
while(test_and_set(lock_status)== 1);
}
void unlock(void volatile lock_t*lock_status){
*lock_status= 0;
}a) volatile关键字的作用
volatile关键词影响编译器编译的结果,用volatile声明的变量表示该变量随时可能发生变化,与该变量有关的运算,不要进行编译优化,以免出错。
b) 怎样优化lock函数(提示:多CPU下如何提高CPUCache效率)
c) 上述代码可能存在的问题(内存模型考虑)















 866
866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









