








作者:橘子派
声明:版权所有,转载请注明出处,谢谢。
实验环境:
Windows10
Sublime
Anaconda 1.6.0
Python3.6
语言识别数据集的基本数据分析方法,包括SVM算法。
#运用sklearn的SVM来训练数据集,测试测试集
from sklearn import svm, metrics
import glob, os.path, re, json
def check_freq(fname):
name = os.path.basename(fname)
lang = re.match(r'^[a-z]{2,}', name).group()
with open(fname, "r", encoding="utf-8") as f:
text = f.read()
text = text.lower()
cnt = [0 for n in range(0, 26)]
code_a = ord("a")
code_z = ord("z")
for ch in text:
n = ord(ch)
if code_a <= n <= code_z:
cnt[n - code_a] += 1
total = sum(cnt)
freq = list(map(lambda n: n / total, cnt))
return (freq, lang)
def load_files(path):
freqs = []
labels = []
file_list = glob.glob(path)
for fname in file_list:
r = check_freq(fname)
freqs.append(r[0])
labels.append(r[1])
return {"freqs":freqs, "labels":labels}
data = load_files("./data/train/*.txt")
#读取训练集
test = load_files("./data/test/*.txt")
#读取测试集
with open("./data/freq.json", "w", encoding="utf-8") as fp:
json.dump([data, test], fp)
clf = svm.SVC()
clf.fit(data["freqs"], data["labels"])
#训练数据集
predict = clf.predict(test["freqs"])
#预测测试集
ac_score = metrics.accuracy_score(test["labels"], predict)
#生成测试精度
cl_report = metrics.classification_report(test["labels"], predict)
#生成交叉验证的报告
print(ac_score)
#显示数据精度
print(cl_report)
#显示交叉验证数据集报告
运行结果图
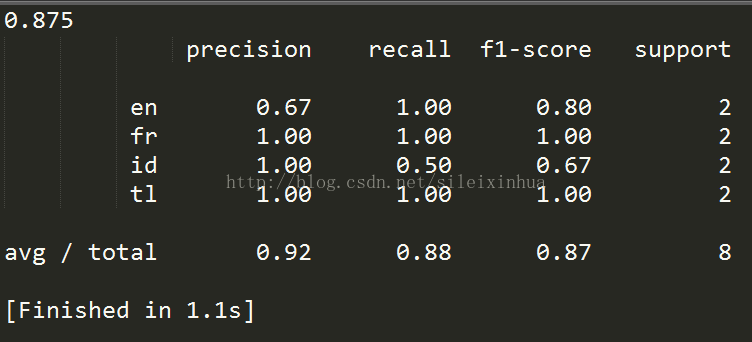
交叉验证三组测试集平均预测精度为0.875
参考文献:
《统计学习方法》
《
Web scraping and machine learning by python》















 6322
6322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









