







(一)、RDD定义
不可变 分布式对象集合
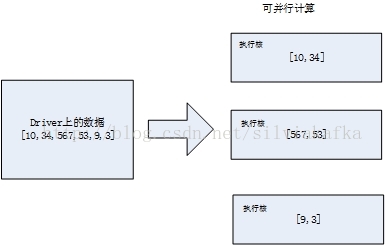
比如下图是RDD1的数据,它的Redcord是数字,分布在三个节点上,并且其内容不可变

创建RDD有两种方式:
1) Driver中分发(parallelize方法)
通过parallelize方法,将驱动程序(Driver)里的集合(复制过去)创建为分布式数据集(分区数默认和执行资源核数保持一致)
List<Integer> data = Arrays.asList(10,34,567,53,9,3);
JavaRDD<Integer> distData = sc.parallelize(data);//它的Redcord是Integer
2) 读取外部数据集(本地文件,HDFS......)
JavaRDD<String> distFile = sc.textFile("data.txt");//它的Redcord是String,默认按行分隔
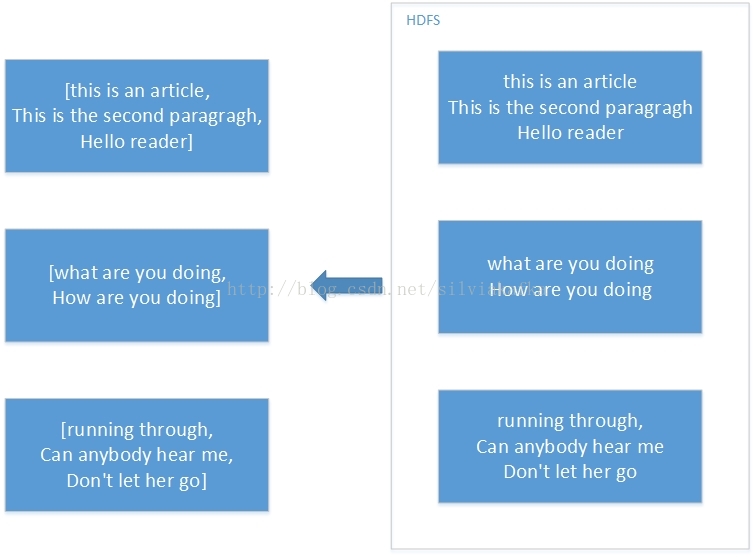
textFile("/my/directory"), textFile("/my/directory/*.txt"),
可以用通配符,读文件夹里所有文件里面所有的数据,返回RDD,每个文件的每一行String数据算一个Record
wholeTextFiles ()也是读取文件夹里所有文件里面所有的数据,但返回的是pairRDD,每个Record是(filename, content) pair
(二)、RDD分区数
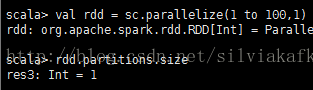
1) Parallelize生成的RDD
默认分区数 = 并行线程数(分配到的CPU核数)
(和spark官网说的:如果不指定,默认会根据分配的资源来设置分区数 一致)
bin/spark-shell --master yarn --num-executors 2 --executor-memory 512m

bin/spark-shell --master yarn-client --num-executors4 --executor-memory 512m

指定分区,指定为多少,分区数就为多少

2) 读取外部数据集生成的RDD
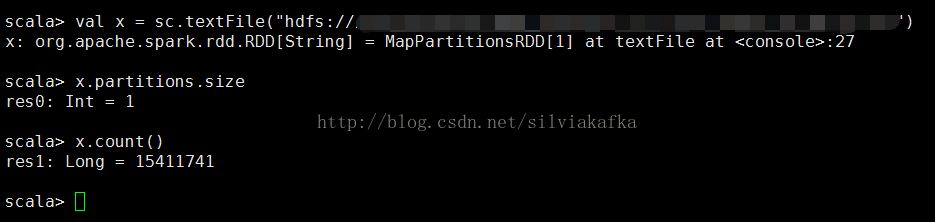
① 对于HDFS上的文件
HDFS文件个数为N,默认就生成N个partition
小实验1:HDFS上某个目录有533个文件(小于128M的文件,因此每个文件只占一个block),读取此目录进行操作,可以看到生成的task数是533

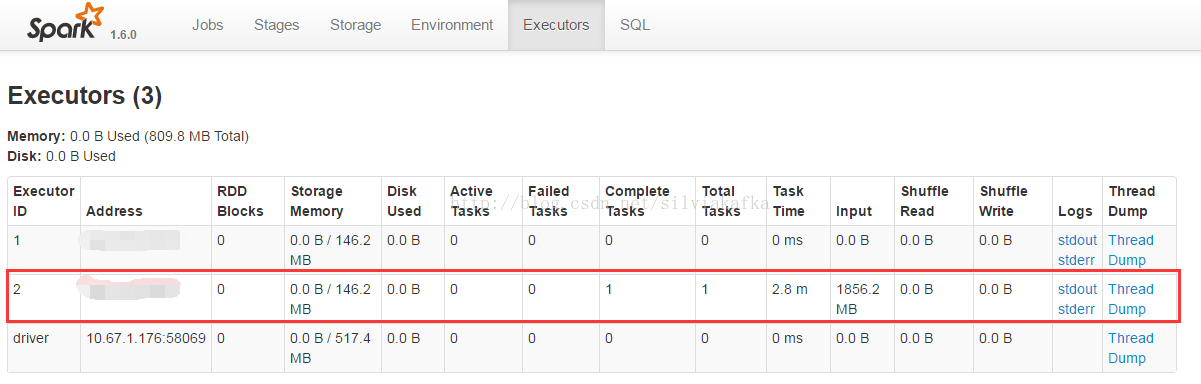
小实验2:HDFS上某个文件1.81G(大于128M的文件,文件在HDFS上占多个block)

使用spark-shell进行测试,其中spark-shell分配2个核。对它运行count操作,可以看到只生成了一个task,而且Executor只用到一个。说明它的partition数的确是1,与其占的block数多少无关。

② 对于本地的文件夹
例如:4个文件的文件夹,默认会生成4个partition
API可以指定minPartitions分区数,sc.textFile(“”,minPartitions)
如果minPartitions小于文件数4,则分区数是文件个数4
如果minPartitions大于文件数4,则分区数是文件个数的倍数8,12....

(Partitions.size会返回结果到driver,是否是action操作呢?
实验证明:并没有提交job,并不是action)
(三)、 RDD操作
RDDs支持 2种操作:1、transformations转换操作,2、Action行动操作
① Transformation操作:由一个RDD生成新的RDD
② Action操作:对RDD计算出一个结果,把结果返回给Driver或者把结果存储到外部存储系统(如HDFS)或者对所有元素应用action操作
Transformations是惰性(lazy)的,调用它时并不做任何操作。只有在调用Action操作时,才会去计算前面的Transformation操作
Transformation实际上是一种链式的逻辑Action,记录了RDD演变的过程调用时,只是做一个记录。调用Action时,才实质触发Transformation开始计算的动作
其中有的是需要传入函数进去的,Function<T,R>,FlatMapFunction<T,R>,PairFunction<T,R>,Function2<T1,T2,R>,对应关系见图 图片请发大看(按住ctrl键的同时,鼠标往上滚动)(涉及的代码在文章最后都有贴出来)
1) 转换操作:

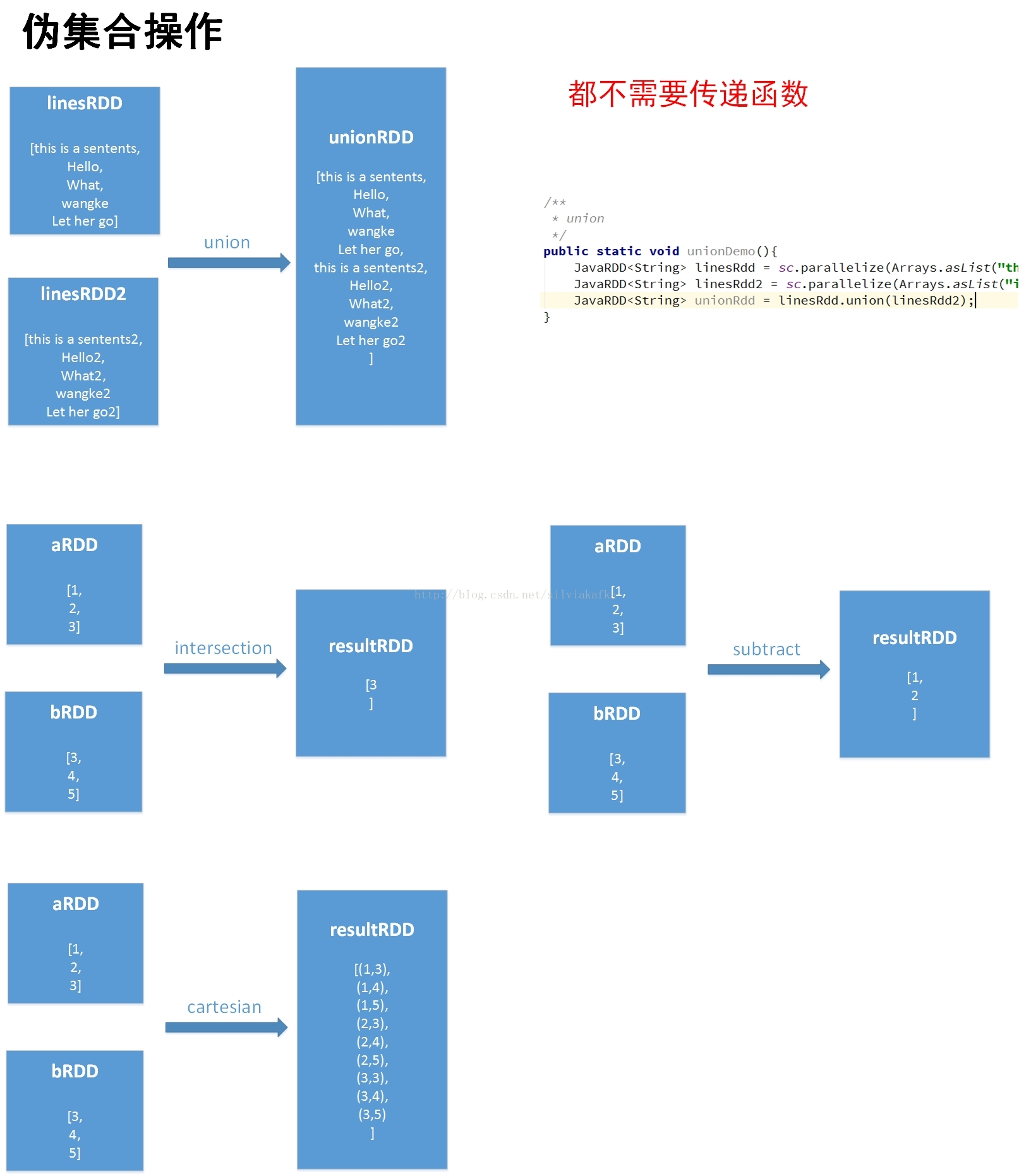
map,filter,flatMap,union (方法的返回值是RDD)
2) RDD行动操作

a. 返回给Driver值:
reduce,fold,aggregate, take(n),top(),first(),collect, count(),countByValue()
(方法的返回值是String,Integer,List......等)
Reduce和fold都要求函数的返回值与RDD的Record类型相同,比如都是Integer的RDD,则Reduce和fold的运算结果就是Integer
Aggregate则摆脱这一限制,可以返回给driver任意类型
collect,take,top都是返回List数据给driver
注意:collect是把RDD的所有数据返回到Driver上,要保证所有数据必须能放入单台机器的内存中,否则会导致Driver run out of memory,会崩掉
RDD的first方法:随机,直接在RDDlist取出第一个,取出的是哪一个就是哪一个。如果数据定义了顺序,则可以取出第一条Record。
count返回long类型的计数值
b. 把结果存储到外部存储系统
saveAsTextFile
c. foreach:
对所有元素应用action操作,对RDD中的每个元素进行操作,而不需要把RDD发回本地Driver
比如进行网络发送数据,或者将数据存储到数据库中
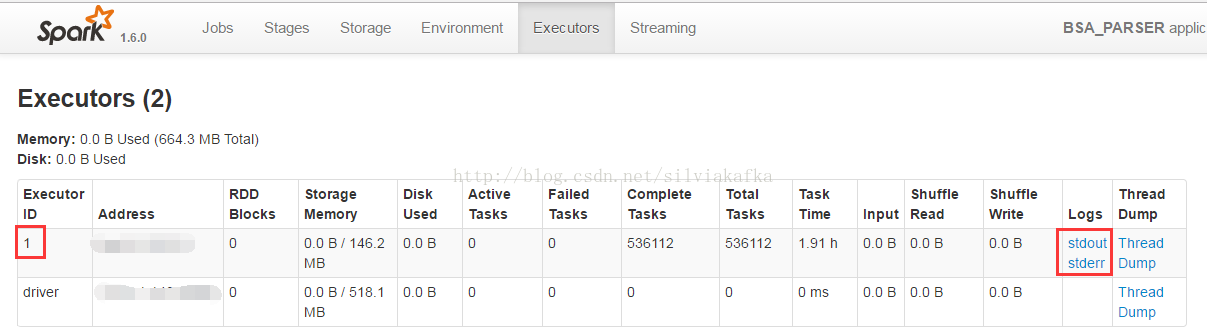
注意:如果调用println操作,它不会回写到Driver,而是写到executor的stdout上,通过通过下面这种方式可以看到输出
如果想在driver上看到输出,则RDD.collect()之后再打印
3) 特殊操作
Persist
当我们多次使用同一个RDD,如果按照我们往常的写法,那么每次计算都要重新计算RDD及其依赖,举个例子(这里内容有点超纲,具体原理可见下章教程)
RDD2 = RDD1.map().filter()
Int a = RDD2.reduce()
RDD3 = RDD2.filter()
Int b = RDD3.reduce()
这里面有两个action,会触发顺序提交两个job,第一个job提交结束之后提交第二个job
第一个job,它计算出DAG图,就是RDD1-->map->filter-->RDD2-->reduce它会从RDD1开始计算起,直到reduce返回结果到driver
第二个job,它计算出DAG图,就是RDD1-->map->filter-->RDD2-->filter-->RDD3-->reduce它会从RDD1开始计算起,直到reduce返回结果到driver
可以看到这两个job把RDD1-->map->filter-->RDD2都执行了一遍,造成重复计算,所以可以使用persist操作 RDD2.persist()。就只要对RDD2计算一次即可,后面直接使用该RDD,而不需要反复计算多次该RDD,那么第二个Job就不在需要计算RDD2了,直接RDD2-->filter-->RDD3-->reduce
RDD的cache()方法其实调用的就是persist方法,缓存策略均为MEMORY_ONLY;可以通过persist方法手工设定StorageLevel来满足工程需要的存储级别;MEMORY_ONLY(JVM的堆空间中),MEMORY_AND_DISK(如果数据在内存中放不下,则溢写到磁盘上)等等
注意:cache或者persist并不是action;
四、pairRDD
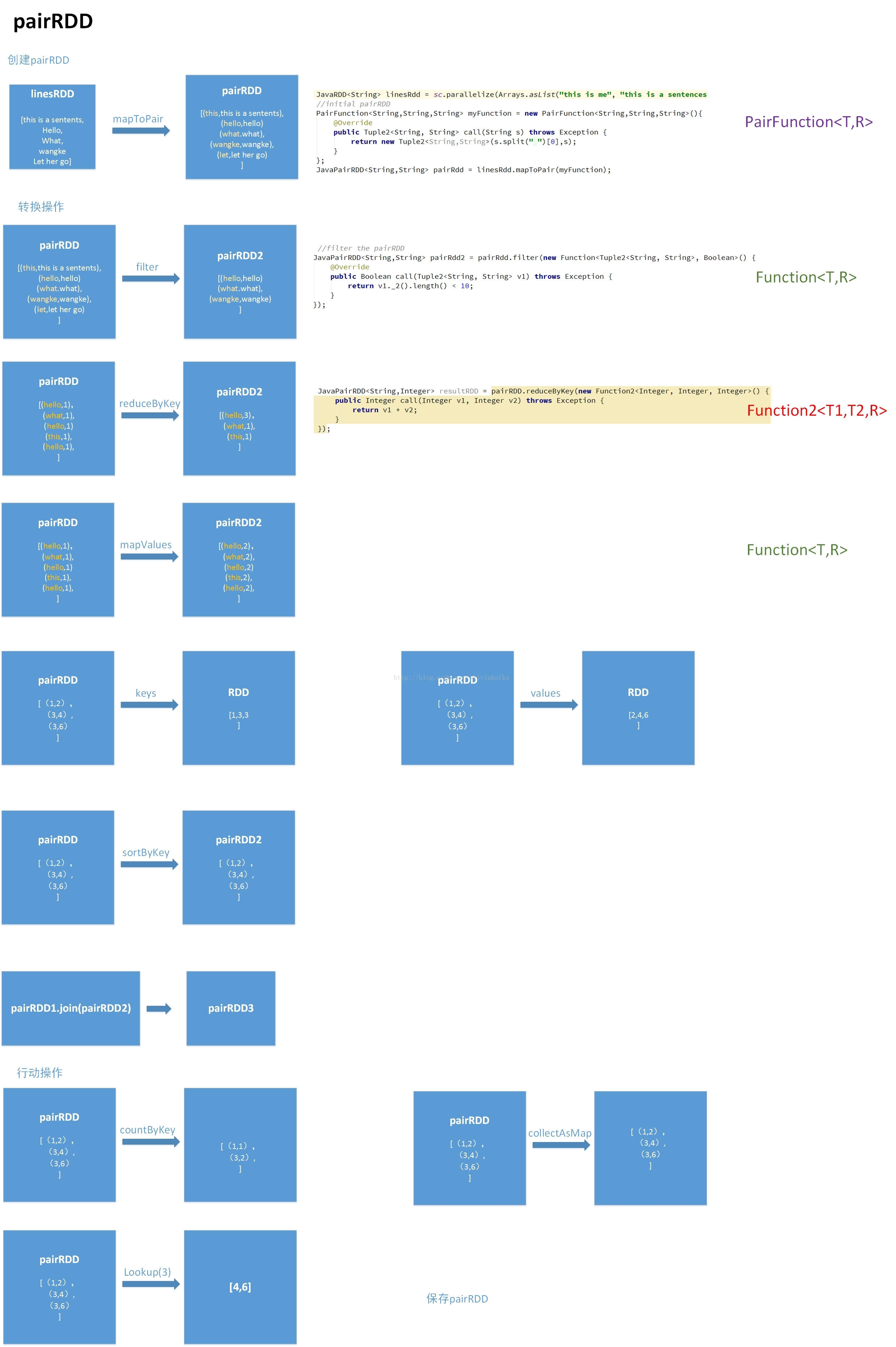
创建pairRDD:mapToPair
pairRDD转换操作
filter(func),reduceByKey(func),mapValues(func)
Keys(),values()
sortByKey()
五、 textFile读取本地文件的坑
在官方说明中,使用本地文件系统,保证worker上都可访问这个路径就可以获取本地文件
If using a path on the local filesystem, the file must also be accessible at the same path on worker nodes. Either copy the file to all workers or use a network-mounted shared file system.
但好像并不行
在Yarn模式下提交时,一直报找不到该文件,就算在所有节点上都放该文件
在Standalone的模式下,如果是单机集群,那么可以找到该文件;如果是多台集群,不同机器上同一个文件路径的文件内容不同,读出的结果却只是某一个机器上的文件内容。
此处一直没弄明白,还请高手指点
/**
* RDD中各值的平方
*/
public static void mapDemo(){
JavaRDD<Integer> numberRdd = sc.parallelize(Arrays.asList(1,2,3,4));
JavaRDD<Integer> resultRddnumber = numberRdd.map(new Function<Integer, Integer>() {
@Override
public Integer call(Integer v1) throws Exception {
return v1 * v1;
}
});
List result = resultRddnumber.collect();
long count = resultRddnumber.count();
System.out.println(StringUtils.join(result, ","));
System.out.println("count is :" +count );
}
/**
* flatMap方法
*/
public static void flatMapDemo(){
JavaRDD<String> linesRdd = sc.parallelize(Arrays.asList("this is a sentences","another sentences","what are you saying"));
JavaRDD<String> wordRdd = linesRdd.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String s) throws Exception {
return Arrays.asList(s.split(" "));
}
});
System.out.println(StringUtils.join(wordRdd.collect(), ","));
System.out.println("count is :" + wordRdd.count());
}
/**
* filter
*/
public static void filterDemo(){
JavaRDD<String> linesRdd = sc.parallelize(Arrays.asList("this is a sentences","another wangke sentences","what are you saying"));
JavaRDD<String> filterRdd = linesRdd.filter(new Function<String, Boolean>() {
@Override
public Boolean call(String v1) throws Exception {
return v1.contains("wangke");
}
});
System.out.println(StringUtils.join(filterRdd.collect(), ","));
System.out.println("count is :" + filterRdd.count());
}
/**
* union
*/
public static void unionDemo(){
JavaRDD<String> linesRdd = sc.parallelize(Arrays.asList("this is a sentences","another wangke sentences","what are you saying"));
JavaRDD<String> linesRdd2 = sc.parallelize(Arrays.asList("i'm saying","we can be together"));
JavaRDD<String> unionRdd = linesRdd.union(linesRdd2);
System.out.println(StringUtils.join(unionRdd.collect(), ","));
System.out.println("count is :" + unionRdd.count());
}
/**
* reduce 返回值类型必须要和我们所操作的RDD中的元素类型相同
*/
public static void reduceDemo(){
JavaRDD<Integer> numberRdd = sc.parallelize(Arrays.asList(1,2,3,4));
Integer result = numberRdd.reduce(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
System.out.println("result is :" +result);
}
/**
* reduce2
*/
public static void reduceDemo2(){
JavaRDD<String> linesRdd = sc.parallelize(Arrays.asList("this ","is a sentences"," what are you saying"));
String result = linesRdd.reduce(new Function2<String, String, String>() {
@Override
public String call(String v1, String v2) throws Exception {
return v1+v2;
}
});
System.out.println("result is :" +result);
}
/**
* reduce2
*/
public static void forEachDemo(){
List<Integer> data = Arrays.asList(5, 1, 1, 4, 4, 2, 2);
JavaRDD<Integer> javaRDD = sc.parallelize(data,3);
javaRDD.foreach(new VoidFunction<Integer>() {
public void call(Integer integer) throws Exception {
System.out.println(integer);
//把此数据发到一个网络服务器上
//把数据存到数据库中
}
});
}
/**
* aggregate
*/
class AvgCount implements Serializable{
public int total;//数字总和
public int num;//数字个数
public AvgCount(int total, int num) {
this.total = total;
this.num = num;
}
}
public void aggregateDemo(){
JavaRDD<Integer> numberRdd = sc.parallelize(Arrays.asList(1,2,3,4));
Function2<AvgCount,Integer,AvgCount> addAndCount = new Function2<AvgCount,Integer,AvgCount>(){
@Override
public AvgCount call(AvgCount v1, Integer v2) throws Exception {
v1.total=+v2;
v1.num=+1;
return v1;
}
};
Function2<AvgCount,AvgCount,AvgCount> combine = new Function2<AvgCount,AvgCount,AvgCount>(){
@Override
public AvgCount call(AvgCount v1, AvgCount v2) throws Exception {
v1.total=+v2.total;
v1.num=+v2.num;
return v1;
}
};
AvgCount initial = new AvgCount(0,0);
AvgCount result = numberRdd.aggregate(initial,addAndCount,combine);
}
/**
* pairRDD
*/
public static void pairRDD(){
JavaRDD<String> linesRdd = sc.parallelize(Arrays.asList("this is me", "this is a sentences", " what are you saying,i'm a very very long sentence"));
//initial pairRDD
PairFunction<String,String,String> myFunction = new PairFunction<String,String,String>(){
@Override
public Tuple2<String, String> call(String s) throws Exception {
return new Tuple2<String,String>(s.split(" ")[0],s);
}
};
JavaPairRDD<String,String> pairRdd = linesRdd.mapToPair(myFunction);
//filter the pairRDD
JavaPairRDD<String,String> pairRdd2 = pairRdd.filter(new Function<Tuple2<String, String>, Boolean>() {
@Override
public Boolean call(Tuple2<String, String> v1) throws Exception {
return v1._2().length() < 10;
}
});
List<Tuple2<String, String>> myResult = pairRdd2.collect();
for(Tuple2<String, String> t:myResult){
System.out.println("key:"+t._1()+" value:"+t._2());
}
JavaPairRDD<String,Integer> pairRDD = null;//仅仅是为了演示
JavaPairRDD<String,Integer> resultRDD = pairRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
}














 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









