







背景:
使用Spark主要是使用Spark Streaming,Spark Streaming的魔力之所在于:
1. 流式处理,如今是一个流处理时代,一切与流不相关的都是无效的数据。
2. 流式处理才是真正的对大数据的印象。Spark Streaming的流式处理非常强大的一个功能是可以在线处理,ML,Spark SQL等流进来的数据,这也是Spark提供的一体化,多元化的技术架构设计带来的优势。
3. Spark Streaming本身是一个程序,Spark Streaming在处理数据的时候会不断感知数据。所以对构建复杂的Spark应用程序,就极为有参考价值。在做Spark实验的时候,如果想分析数据的如何流进来,是怎么样被计算的,我们就可以通过Spark Streaming来实现,将batch Interval设置时间非常大,这样里面的很多细节就可以通过log日志观察,这就相当于过去摄影师将李小龙的功夫,然后慢放这样就可以看的更加清晰。
一: Spark Streaming另类在线实验
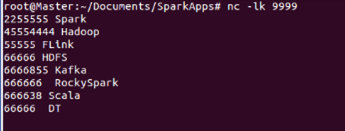
- 启动9999端口,往里面追加数据。如下图所示:
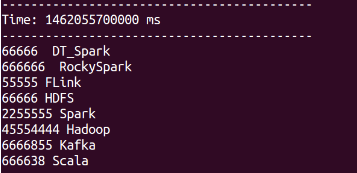
- Spark Streaming会在设定的时间间隔中不断的循环,接收数据,然后计算,打印如下:
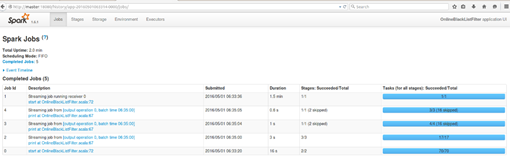
- 通过master:18080端口查看作业的运行,实质上运行了一个Job,然后web端显示运行了5个Job.为啥这样?继续下去一探究竟!!
- 先查看Job Id 为0的Job,然后DAG里面的操作我们在实际的代码中并不用这些操作,Spark Streaming在计算的时候会自动的为我们启动一些Job。
第一个Job会在4个Worker上启动,为了负载均衡,这样后续计算的时候,就可以最大化的使用集群资源。
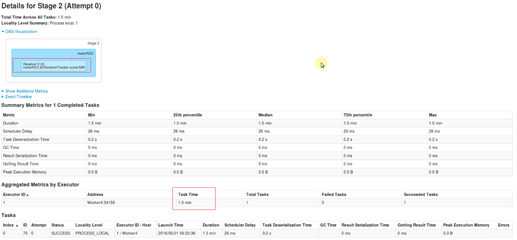
- Job Id为1的Job数据接收器Receiver运行了1.5min,而此时的Receiver的启动是通过Job,而Receiver运行在Executor中且以一个Task的方式去接收数据,和普通的Job接收数据没有区别,这样的话,我们就可以在一个Spark Application中启动很多的Job,不同的Job之间可以相互配合,而Spark Streaming默认启动一个Job是Receiver接收数据。因此对于构建复杂的实现奠定了一个非常好的基础,可以根据其扩展满足自己需要的业务逻辑,并且也可以启动多个Receiver.
- Receiver的Locality Level是PROCESS_LOCAL(内存节点),Spark Streaming默认接收数据是MEMORY_AND_DISK_2的方式,由此也可以看出,默认情况下如果是小数据的话,Spark默认会将数据放入到内存中.
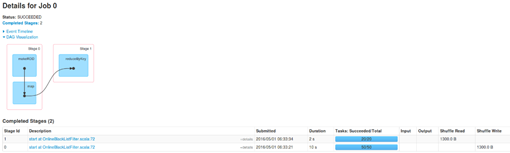
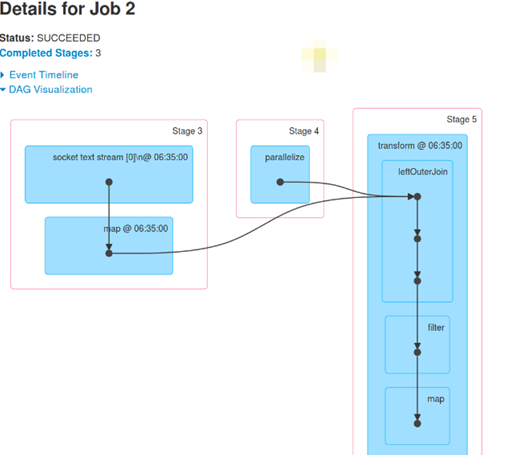
- Job Id为2的Job,DAG视图如下:
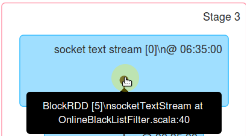
此时的BlockRDD来自于socketTextStream,实质是InputDStream根据时间间隔产生RDD。
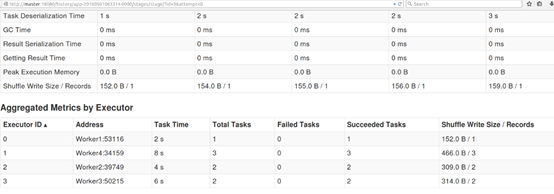
虽然是在一台机器上接收数据的,但是在4个Executor中完成计算的,这样就可以最大化利用集群资源。
二: 瞬间理解Spark Streaming本质
Spark Streaming是基于Spark Core上的一个应用程序,可伸缩,高吞吐,容错(这里主要是借助Spark Core的容错方式)处理在线数据流,数据可以有不同的来源,以及同时处理不同来源的数据。Spark Streaming处理的数据可以结合ML和Graph
Spark Streaming本身是随着流进来的数据按照时间为单位生成Job,然后触发Job,再Cluster执行的一个流式处理引擎,本质上说是加上了时间维度的批处理。 - Spark Streaming支持从多种数据源中读取数据,如Kafka,Flume,HDFS,Kinesis,Twitter等,并且可以使用高阶函数如map,reduce,join,window等操作,处理后的数据可以保存到文件系统,数据库,Dashboard等。
- Spark Streaming的工作原理
实时接收数据流,以时间的维度将数据拆分成多个Batch,然后将每个Batch进行计算,最后的结果也是以batch的方式组成的。
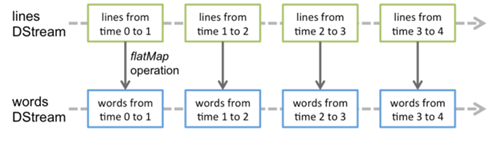
- Spark Streaming提供了一个更高级的抽象,DStream,代表了一个持续不断的数据流,DStream的创建可以通过输入数据源(Kafka,Flume和Kinesis),或者通过算子如(Map,reduce,join,window),DStream内部就是一系列持续不断产生的RDD。而每个RDD都包含了一个时间段的数据。
- 对DStream应用算子比如map,其实底层被翻译为DStream中的每个RDD操作,每个DStream执行一个map,都会生成新的DStream,但是在底层实质是对RDD进行map操作,然后产生新的RDD,这个过程是通过Spark Core完成的,Spark Streaming对Spark Core进行了一层封装,隐藏了细节,对开发者提供了方便,易用的API。
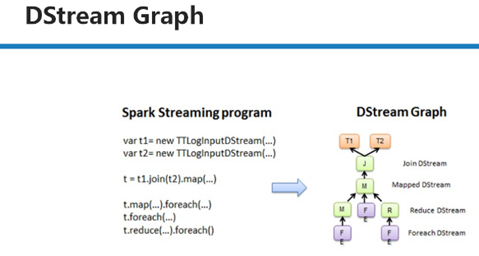
对DStream的操作会产生Graph,图中的T1,T2为输入数据,对其进行join,map,foreach等操作,然后产生新的DStream这样就构成了一个Graph,最后在计算的时候会回溯。
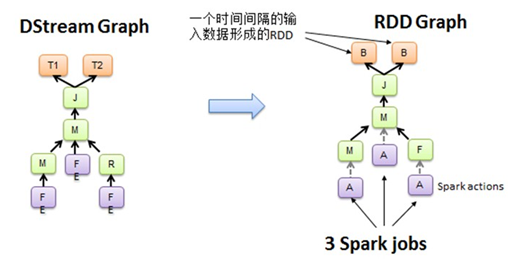
Spark Streaming中Job的产生,以时间的维度,不断产生batch,在算子的操作下,不生产新的DStream,内部实质是产生新的RDD,具体在计算的时候,这样就将DStream Graph转成了RRD Graph。然后再有Spark Core引擎计算。
- Receiver的Locality Level是PROCESS_LOCAL(内存节点),Spark Streaming默认接收数据是MEMORY_AND_DISK_2的方式,由此也可以看出,默认情况下如果是小数据的话,Spark默认会将数据放入到内存中.




总结:
本次课程在很短的时间内对于Spark Streaming在处理数据的逻辑上有了本质的理解,后续的课程中会将深入理解,这其中的诸多细节过程,真相也会慢慢浮出水平。作为三把斧系列,好戏还在后面!!














 1148
1148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









