







1. Caffe配置参数
解析:
(1)lr_mult:权重参数w的学习率倍数。
(2)decay_mult:偏置参数b的学习率倍数。
(3)xavier:Understanding the difficulty of training deep feedforward neural networks。
(4)dropout_ratio:丢弃数据的概率。
(5)weight_decay:权重衰减,即weight和bias的权重乘以这个值。
(6)pool:池化方法,默认为MAX。目前可用的方法有MAX,AVE,STOCHASTIC。
(7)bias_term:是否开启偏置项,默认为true。
(8)Siamese Network:孪生网络。
(9)pad:指定输入的每一边加上多少像素个数,默认为0。
(10)rand_skip:在开始的时候跳过rand_skip个输入数据,这个对异步SGD有效。
(11)shuffle:随机打乱顺序,默认值为false。
(12)new_height,new_width:把所有的图像resize到这个大小,默认值为0。
2. 多通道图像
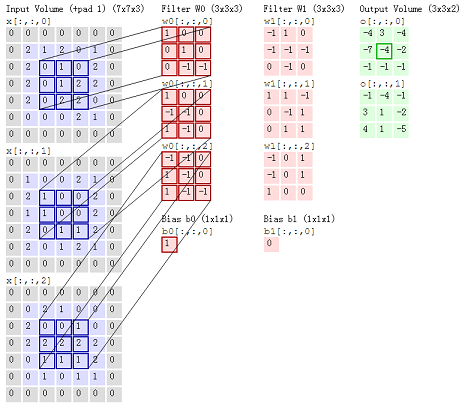
解析:一个通道中的某个区域(蓝框)和它对应的卷积核(红框)做卷积,多个通道的卷积结果线性相加,再加上偏
置量(最下的单个红框),得到卷积结果(最右列中心的绿色框)。
3. MS COCO数据集
解析:COCO(Common Objects in Context)是一个新的图像识别、分割和图像语义数据集。
说明:图像语义分割数据集SIFT Flow,PASCAL-Context,PASCAL VOC,NYUDv2。
4. SqueezeNet模型
解析:SqueezeNet主要是为了降低CNN模型参数数量而设计的。
5. Invalid MEX-file 'D:\caffe-master\Build\x64\Release\matcaffe\+caffe\private\caffe_.mexw64': 找不到指定的模块。
解析:Path=D:\caffe-master\Build\x64\Release。
6. input_param { shape: { dim: 10 dim: 3 dim: 32 dim: 32 } }
解析:dim: 10表示对待识别样本进行数据增广的数量。一般会进行5次crop,之后分别flip。如果不进行数据增广,那
么可以设置成1。
7. Caffe中的卷积计算过程
解析:Caffe中的卷积计算是将卷积核矩阵和输入图像矩阵变换为两个大的矩阵A与B,然后A与B进行矩阵相乘得到结
果C(利用GPU进行矩阵相乘的高效性)。
(1)矩阵A
M为卷积核个数,K = k * k,等于卷积核大小,即第一个矩阵每行为一个卷积核向量,总共有M行,表示有M个卷积
核。
(2)矩阵B
- N = ((image_h + 2 * pad_h – kernel_h)/stride_h + 1)*((image_w+2*pad_w–kernel_w)/stride_w + 1)。
- image_h:输入图像的高度。
- image_w:输入图像的宽度。
- pad_h:在输入图像的高度方向两边各增加pad_h个单位长度。
- pad_w:在输入图像的宽度方向两边各增加pad_w个单位长度。
- kernel_h:卷积核的高度。
- kernel_w:卷积核的宽度。
- stride_h:高度方向的滑动步长。
- stride_w:宽度方向的滑动步长。
(3)矩阵C
矩阵C为矩阵A和矩阵B相乘的结果,得到一个M*N的矩阵,其中每行表示一个输出图像即feature map,共有M个输出
图像(输出图像数目等于卷积核数目)。
说明:Caffe中使用src/caffe/util/im2col.cu中的im2col和col2im来完成矩阵的转换操作。[2]
8. Inception Network
解析:
(1)Inception V1 Network
(2)Inception V2 Network
(3)Inception V3 Network
(4)Inception V4 Network
(5)Inception ResNet V2 Network
参考文献:
[1] Convolutional Neural Networks for Visual Recognition:http://cs231n.stanford.edu/
[2] 在Caffe中如何计算卷积?:https://www.zhihu.com/question/28385679
















 186
186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











