







 本文介绍了如何使用深度Q学习(DQN)和卷积神经网络(CNN)实现一个打砖块游戏。通过处理原始图像数据,利用最近四帧作为输入,增加了时间序列信息。训练过程中,网络结构基于DeepMind的DQN论文,用CNN处理图像,然后进行全连接层计算每个动作的价值。经过长时间训练,agent能逐渐学会准确接球。
本文介绍了如何使用深度Q学习(DQN)和卷积神经网络(CNN)实现一个打砖块游戏。通过处理原始图像数据,利用最近四帧作为输入,增加了时间序列信息。训练过程中,网络结构基于DeepMind的DQN论文,用CNN处理图像,然后进行全连接层计算每个动作的价值。经过长时间训练,agent能逐渐学会准确接球。
1.Acknowledgement
本篇文章中神经网络的结构主要来自于DeepMind的这篇论文
https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf
2. 实现效果
我们要实现的这个游戏,在openai的gym里面,叫做breakout,使用的是v3版本,初始化环境的时候需要声明一下
我们想要实现的效果,基本上是这样的

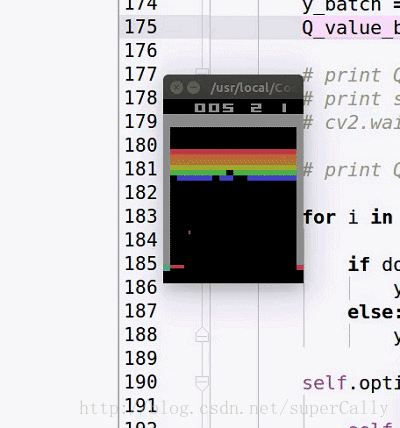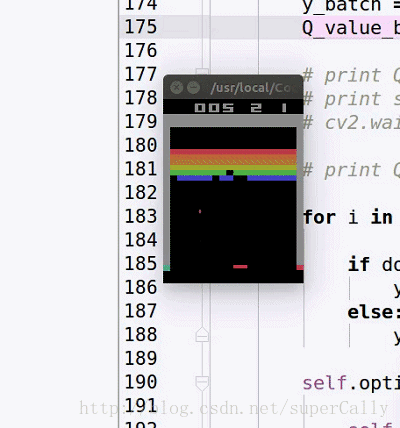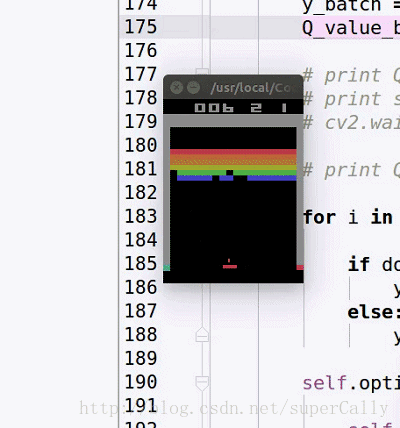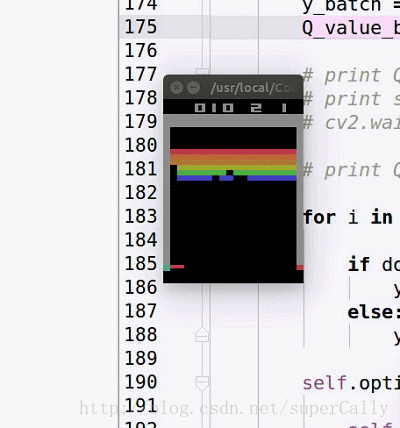
输入就是每一帧的图像,输出是当前应该采取的动作
一开始agent只会做随机的运动,在训练了一段时间之后,就可以精准的接住球了
3. 基本框架
基本框架这之前基本相同,都是采用Q-Learning算法

具体解释看这篇文章
http://blog.csdn.net/supercally/article/details/54767499
4. 与之前简单版本的区别
最大的区别有这几点:
1. 输入是原始的图像数据
输入是210 * 160 * 3的图像,我们稍作处理,把边上不需要的像素去掉之后降阶采样灰度化,将80 * 80 * 1的图像作为算法的输入
2. 用最近的四帧的序列作为输入
神经网络的输入不是单帧的图像,而是最近的连续四帧图像作为输入。这也很好理解,因为这样就加入了时间序列。对于打砖块这个游戏,如果只用一帧作输入的话,虽然砖块在同一个位置,但是可能是向好几个方向运动的,agent无法判断它的价值。
但是如果我们添加了最近几帧,agent就可以根据前后的时间判断出是向哪个方向运动的,这个状态就完整了
3. 卷积神经网络的结构
在用神经网络判断价值方面,与之前不同。之前简单的训练网络是用了一个隐层的网络来实现的,但是对于处理图像的任务,我们使用的是卷积神经网络
使用的网络的结构是这样的
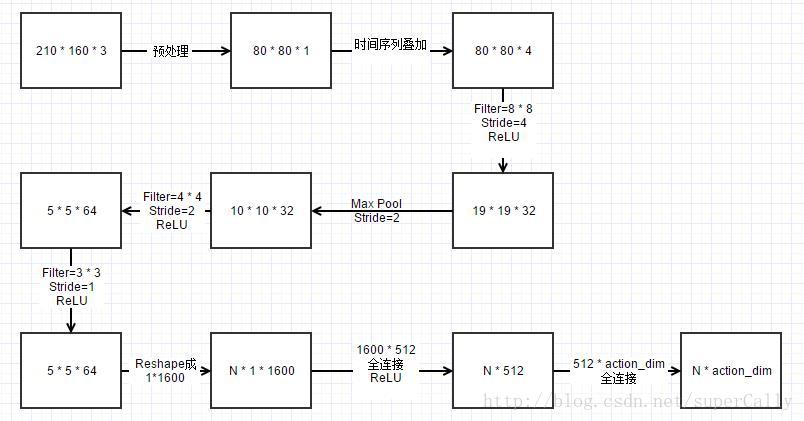
卷积神经网络的大小这样计算
Sizeoutput=W−F
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 866
866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









