







目标
打砖块是gym游戏中相对复杂一些的游戏,不同于CartPole游戏,状态空间较少,基本上10分钟左右训练就可以玩到最高分,打砖块要训练非常长的时间,因此对于更进一步去理解和优化DQN非常有帮助。
第一版尝试
打砖块的基础
打砖块的reward设置是敲打到砖块:reward = 1
5次球都未接到或者全部砖块打完了done = 1
state就是整个游戏中的全体像素
预处理
图片预处理
首先图片可以转为单通道,且像素只需要具体游戏区内的部分,且分辨率可以降低,因此预处理如下:
def preprocess(img):
img_temp = img[31:195]
img_temp = img_temp.mean(axis = 2)
img_temp = cv2.resize(img_temp,(IMG_SIZE,IMG_SIZE))
img_temp = (img_temp - 127.5) / 127.5
return img_temp
状态预处理
单张图片很难表述出球运动的方向,为了更好的表现出游戏中的状态就需要连续多张图片,这里我取了连续4张图片。
网络设计
这里贴出代码,先使用三层卷积网络降维后
def create_Q_network(self):
# network weights
input_layer = Input(shape=(IMG_SIZE,IMG_SIZE,4), name="unet_input")
#converlution
cnn1 = Convolution2D(nb_filter=32, nb_row=8, nb_col=8, border_mode='same', subsample=(4, 4))(input_layer)
cnn1 = ReLU()(cnn1)
cnn2 = Convolution2D(nb_filter=64, nb_row=4, nb_col=4, border_mode='same', subsample=(2, 2))(cnn1)
cnn2 = ReLU()(cnn2)
cnn2 = Convolution2D(nb_filter=64, nb_row=3, nb_col=3, border_mode='same', subsample=(1, 1))(cnn1)
cnn2 = ReLU()(cnn2)
#full connect
fc0 = Flatten()(cnn2)
fc1 = Dense(512)(fc0)
#get Q_value
q_value= Dense(self.action_dim)(fc1)
self.model = Model(input=[input_layer], output=[q_value], name='Q_net')
self.model.compile(loss='mse',optimizer=Adam(lr=self.learning_rate))
第二版本尝试
由于第一版读取整个图片,且需要连续4帧,在图片处理环节就需要消耗大量时间,且获得得信息其实与真正乒乓球相关得只有球得坐标以及板子的位置,且仅需要两帧就可以用于表述需要的状态,因此我改进了状态变量的,之用了4个维度。
def preprocess(img):
img_temp = img.mean(axis = 2)
# img_temp = cv2.resize(img_temp,(IMG_SIZE,IMG_SIZE))
x = -1
y = -1
flag = 0
if len(np.where((img_temp[100:189,8:152])!= 0)[0]) != 0:
x = np.where((img_temp[100:189,8:152])!= 0)[0][0]
y = np.where((img_temp[100:189,8:152])!= 0)[1][0]
if len(np.where((img_temp[193:,8:152])!= 0)[0]) != 0:
x = np.where((img_temp[193:,8:152])!= 0)[0][0] + 93
y = np.where((img_temp[193:,8:152])!= 0)[1][0]
flag = 1
# x = -2
# y = -2
p = int(np.where(img_temp[191:193,8:152])[1].mean() - 7.5)
#return img_temp
return (x,y,p,flag)
for step in range(STEP):
print("episode:%d step:%d" % (episode,step))
action = agent.egreedy_action(state_shadow)
next_state,reward,done,_ = env.step(action)
(x2,y2,p2,flag) = preprocess(next_state)
next_state_shadow = np.array([x1,y1,x2,y2,p2])
# Define reward for agent
#reward_agent = -1 if done else 0.1
#加大落下的惩罚
if flag == 1:
reward = -10
done = True
else:
reward = 0.1
agent.perceive(state_shadow,action,reward,next_state_shadow,done)
# if cur_loss is not None:
# total_loss += cur_loss
total_reward += reward
state_shadow = next_state_shadow
x1,y1,p1 = x2,y2,p2
if done:
break
经过14000 episode的迭代的效果如下:
测试出的Reward虽然整体有上升的趋势但:
- 测试集上波动太过明显
- 整体reward未达到期望(以我设定的step满足大于20才是比较好的效果也就是基本一个球不掉)

第三版本尝试
引入prioritised,改变训练样本的权重。训练了差多15个小时左右,平均收益任然不是很理想,不过玩起来的感觉还不错了
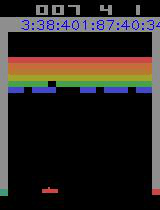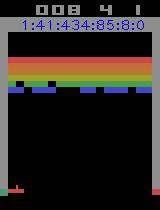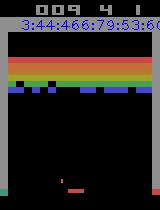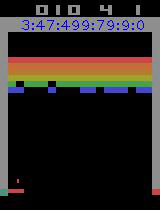
代码目录:
https://github.com/hlzy/operator_dnn















 188
188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









