







声明:此博客由本人经过实验楼的实验整理得来。
1. Spark概念
Spark是UC Berkeley AMP lab开发的一个集群计算的框架,类似于Hadoop,但有很多的区别(详细见3.4)。最大的优化是让计算任务的中间结果可以存储在内存中,不需要每次都写入HDFS,更适用于需要迭代的MapReduce算法场景中,可以获得更好的性能提升。例如一次排序测试中,对100TB数据进行排序,Spark比Hadoop快三倍,并且只需要十分之一的机器。
2. 关于Spark的文章
2.1 大数据技术生态圈
2.2 Spark与Hadoop的对比
3.安装
下面记录一下自己的安装过程和在安装时出现的一下问题,这里说一下自己用的是CentOS6.5的linux系统。
3.1 安装前的准备
- java环境,一般linux中都有
- python环境,一般linux中会默认安装
- scala环境,需要下载
- spark 软件,需要下载
安装JAVA
//检查java的版本,满足安装spark要求
//如果版本不足,或者没有可自行安装
java version "1.8.0_111"
Java(TM) SE Runtime Environment (build 1.8.0_111-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.111-b14, mixed mode)安装Scala
安装过程非常的简单,如下:
wget http://labfile.oss.aliyuncs.com/courses/456/scala-2.11.7.tgz
tar zxvf scala-2.11.7.tgz
sudo mv scala-2.11.7 /opt/ 安装Python
可以看到已经有了,如果没有请自行安装,很简单可以通过yum源进行安装。
[yqtao@yqtao ~]$ python
Python 2.6.6 (r266:84292, Aug 18 2016, 15:13:37)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-17)] on linux2安装Spark
Spark官方下载链接:http://spark.apache.org/downloads.html
按照下图进行选择,并选择下载tgz类型的文件。
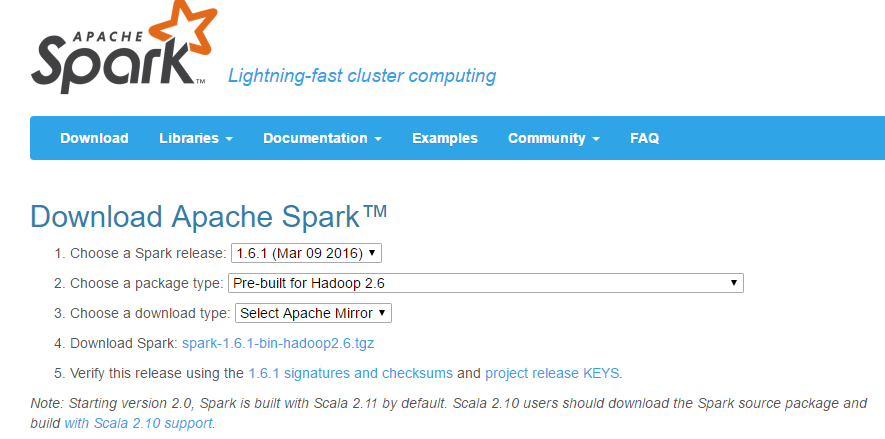
接下来我用secureCRT将下载好的压缩文件传到我的linux中。
//解压并将其转移到/opt/目录下
tar zxvf spark-1.6.1-bin-hadoop2.6.tgz
sudo mv spark-1.6.1-bin-hadoop2.6 /opt/3.2 配置路径与日志
为了避免每次都输入/opt/spark-1.6.1-bin-hadoop2.6这一串前缀,我们将必要的路径放到PATH环境变量中。
# 添加配置到bshrc
# 这里要注意的是大小写别写错
# 练习一下书写
echo "export PATH=$PATH:/opt/spark-1.6.1-bin-hadoop2.6/bin" >> ~/.bashrc
# 使bashrc起作用
source ~/.bashrc
# 测试下spark-shell的位置是否可以找到
[yqtao@yqtao ~]$ which spark-shell
/opt/spark-1.6.1-bin-hadoop2.6/bin/spark-shell进入到spark的配置目录/opt/spark-1.6.1-bin-hadoop2.6/conf进行配置:
# 进入配置目录
cd /opt/spark-1.6.1-bin-hadoop2.6/conf
# 基于模板创建日志配置文件
cp log4j.properties.template log4j.properties
# 使用vim编辑文件log4j.properties
# 修改log4j.rootCategory为WARN, console,可避免测试中输出太多信息
log4j.rootCategory=WARN, console
# 基于模板创建配置文件
sudo cp spark-env.sh.template spark-env.sh
# 使用vim编辑文件spark-env.sh
# 添加以下内容设置spark的环境变量
export SPARK_HOME=/opt/spark-1.6.1-bin-hadoop2.6
export SCALA_HOME=/opt/scala-2.11.7到此,安装基本结束,非常的简单,下面进行简单的测试。
4. 测试
这里仅仅对python版本的spark进行测试,不对scala进行测试。
用命令pyspark即可启动spark
[yqtao@yqtao ~]$ pyspark
Python 2.6.6 (r266:84292, Aug 18 2016, 15:13:37)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-17)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
16/11/18 23:16:47 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/11/18 23:16:47 WARN Utils: Your hostname, yqtao resolves to a loopback address: 127.0.0.1; using 192.168.202.128 instead (on interface eth0)
16/11/18 23:16:47 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 1.6.1
/_/
Using Python version 2.6.6 (r266:84292, Aug 18 2016 15:13:37)
SparkContext available as sc, HiveContext available as sqlContext.
>>> 这里可能会出现一个错误:java.net.UnknownHostException: XXXX Name or service not known
[yqtao@yqtao ~]$ hostname
yqtao
#在这里进行ping主机的时候会出现错误
#当然这里已经更改过了
[yqtao@yqtao ~]$ ping yqtao
PING yqtao (127.0.0.1) 56(84) bytes of data.
64 bytes from localhost (127.0.0.1): icmp_seq=1 ttl=64 time=0.024 ms
64 bytes from localhost (127.0.0.1): icmp_seq=2 ttl=64 time=0.267 ms
64 bytes from localhost (127.0.0.1): icmp_seq=3 ttl=64 time=0.037 ms
64 bytes from localhost (127.0.0.1): icmp_seq=4 ttl=64 time=0.108 ms方法如下:
vim /etc/hosts
#在文件的最后加上
#这里要换成自己的主机名
127.0.0.1 hostname下面实现一些简单的功能:
首先打开pyspark,可以看到一行提示:
SparkContext available as sc, HiveContext available as sqlContext.
告诉我们可以用sc访问上下文。
>>> file=sc.textFile("/etc/protocols")
# 获得行数
>>> file.count()
160
# 获得第一行的内容
>>> file.first()
u'# /etc/protocols:'5. 启动Spark服务
启动主节点:
# 进入到spark目录
cd /opt/spark-1.6.1-bin-hadoop2.6
# 启动主节点
# 这里要有root权限
./sbin/start-master.sh在浏览器中打开:
http://localhost:8080这里是在linux中的系统中。
如下图所示:spark://localhost.localdomain:7070是启动从节点的参数。
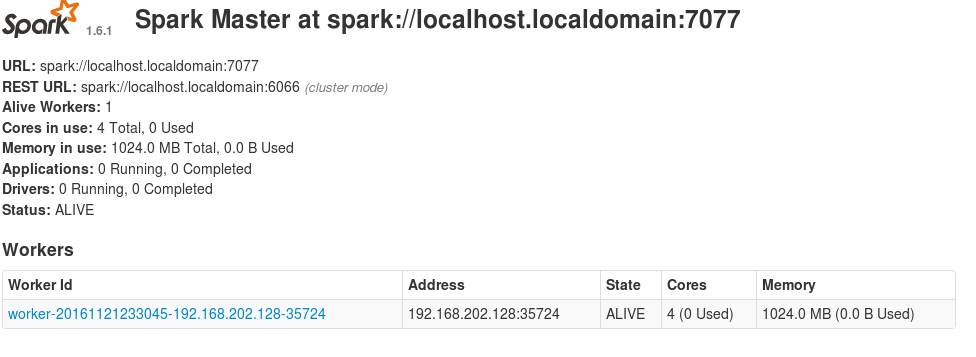
启动slave节点:
[root@yqtao spark-1.6.1-bin-hadoop2.6]# ./sbin/start-slave.sh spark://localhost.localdomain:7070
使用pyspark连接master再次进行上述的文件行数测试
MASTER=spark://localhost.localdomain:7070 pyspark
刷新master的web页面,可以看到新的Running Applications,如下图所示:
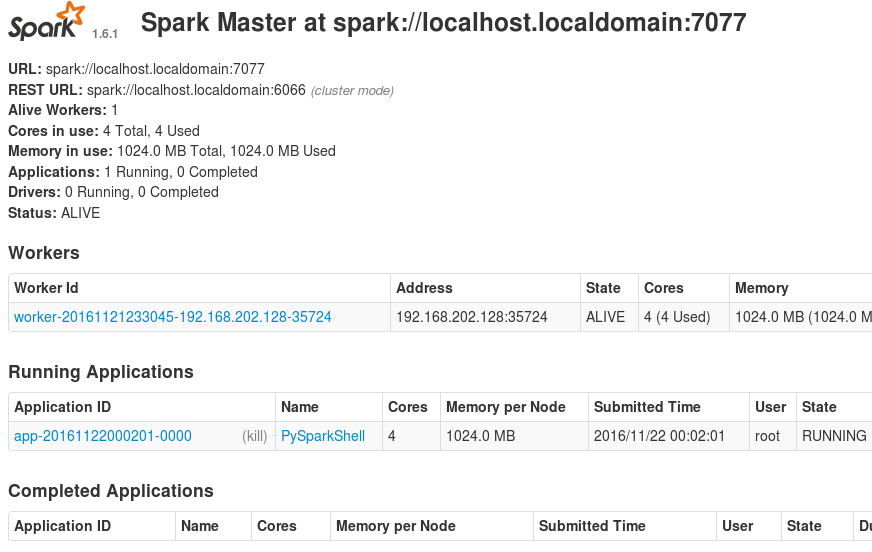
终止服务:./sbin/stop-all.sh














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









