







正则表达式基础
正则表达式是用于处理字符串的强大工具,熟练的使用正则表达式将会对字符串的编程非常具有帮助。
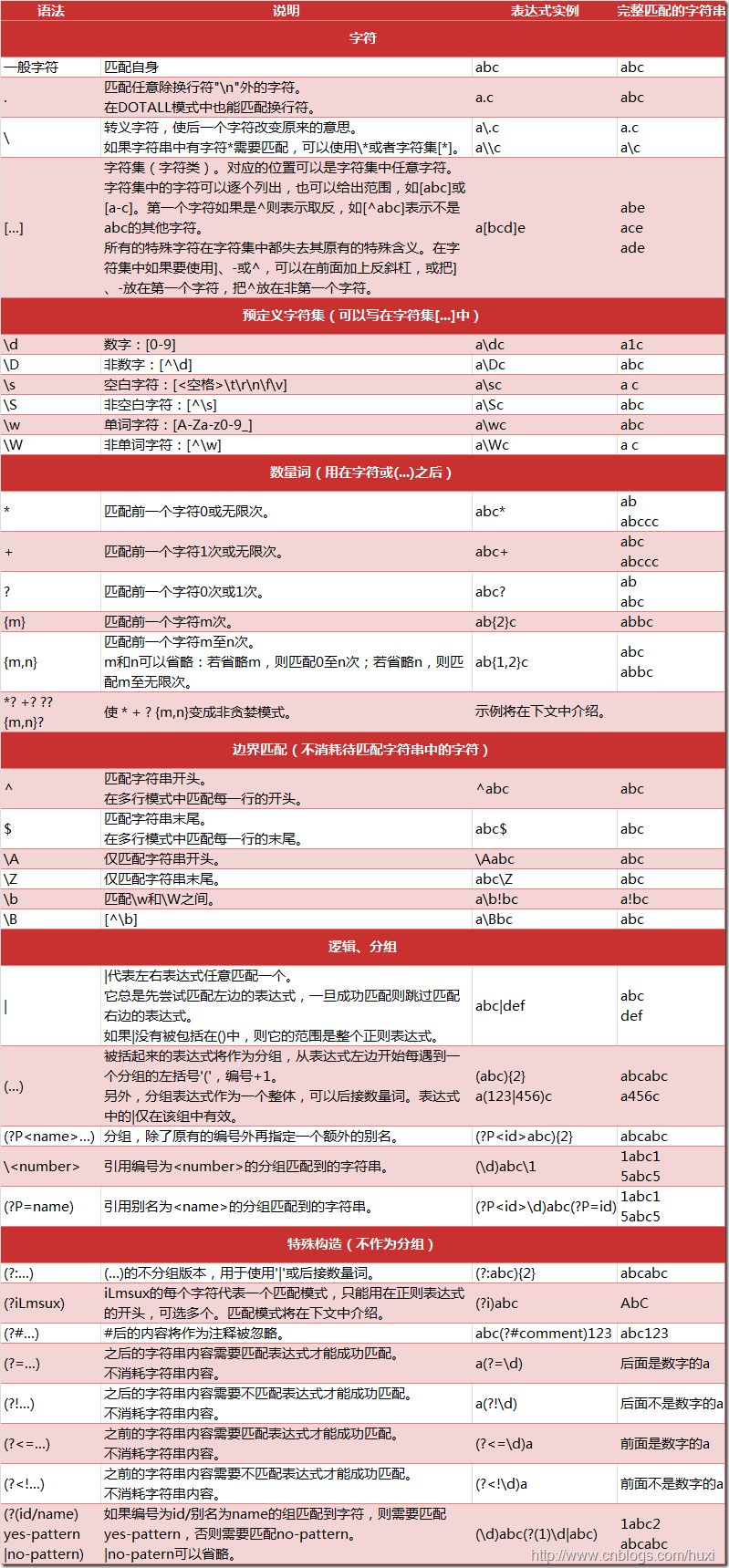
下图列出了Python支持的正则表达式元字符和语法:
引用:Python正则表达式指南
这张图片简直是神图,搞懂了这个,就搞懂了一些普通的正则表达式的内容了。
原生字符:
在大多数正则表达式中,会使用\作为转移字符,如我们要表示一个数字,则要写成\\d才行,但是python中的原生字符很好的解决这个问题,即可以写成r'\d'的形式。
例如:
s = 'ABC\\-001' # Python的字符串
# 对应的正则表达式字符串变成:
# 'ABC\-001'
s = r'ABC\-001' # Python的字符串
# 对应的正则表达式字符串不变:
# 'ABC\-001'因此,有了原生字符,就可以避免少些\的烦恼了。
Match
要使用Python的需要导入正则表达式的模块re.
match 对象是一次匹配的结果,包含匹配的信息。
# 如下模式串hello,要匹配的串hello,world
>>> import re
>>> match=re.match(r'hello','hello,world')
>>> match.group() #获得分组信息
'hello'匹配电话号码,假设形式为000-00000前面三个数字,后面5-8个数字
>>> import re
>>> match=re.match(r'\d{3}\-\d{5,8}','010-123456')
>>> if match:
... print match.group()
... else:
... print 'false'
...
010-123456 #输出的结果分组
在匹配的过程中可以进行分组提取子串,在Python中用()可以提取分组信息
# 这里-要使用\-
>>> match=re.match(r'^(\d{3})\-(\d{5,8})$','010-12345')
>>> match.group(0)
'010-12345'
>>> match.group(1) #获得分组
'010'
>>> match.group(2)
'12345'下面一个更加复杂的例子:
这里是一条 Apache日志
180.76.15.161 - - [06/Dec/2014:06:49:26 +0800] "GET / HTTP/1.1" 200 10604 "-" "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)"Apache日志内容从左到右依次是:
- 远程IP地址
- 客户端记录
- 浏览者记录
请求的时间,包括三项内容:
- 日期
- 时间
- 时区
服务器收到的请求,包括三项内容:
- METHOD:请求的方法,GET/POST等
- RESOURCE:请求的目标链接地址
- PROTOCOL:HTTP版本
- 状态代码,表示请求是否成功
- 发送的字节数
- 发出请求时所在的URL
- 客户端的详细信息:操作系统及浏览器等
这里我们提取的信息为:
1. 客户端的IP
2. 请求日期
3. 请求的URL
4. HTTP状态码(如200)
>>> import re
# 注意要使用原生字符
>>> s=r'180.76.15.161 - - [06/Dec/2014:06:49:26 +0800] "GET / HTTP/1.1" 200 10604 "-" "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)"'
# pattern为正则表达式模式串
# re.compile将其编译成pattern对象
>>> pattern=re.compile(r'^(\S+) (\S+) (\S+) \[([\w/]+)([\w:/]+)\s([+\-]\d{4})\] \"(\S+) (\S+) (\S+)\" (\d{3}) (\d+)')
>>> m=pattern.match(s)
# 分组信息
>>> m.group(1)
'180.76.15.161'
>>> m.group(4)
'06/Dec/2014'
>>> m.group(8)
'/'
>>> m.group(10)
'200'Split
split即以匹配到的子串作为分割点对字符串进行分割然后生成一个列表。
最常见的的一种方式为:
# 以空格为分隔符
>>> m=re.split(' ','i am a good boy!')
>>> m
['i', 'am', 'a', 'good', 'boy!']
# 注意如果多出了一个空格
>>> m=re.split(' ','i am a good boy!')
>>> m
['i', '', 'am', 'a', 'good', 'boy!']>>> import re
# 匹配数字
>>> pattern=re.compile(r'\d+')
>>> m=pattern.split('one1two2three3four')
# m是一个列表
>>> m
['one', 'two', 'three', 'four']参考资料:
1. Python正则表达式指南
2. 正则表达式















 371
371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









