









概述
scikit-learn 是机器学习领域非常热门的一个开源库,基于Python 语言写成。可以免费使用。 而且使用非常的简单,文档感人,非常值得去学习。
下面是一张scikit-learn的图谱:
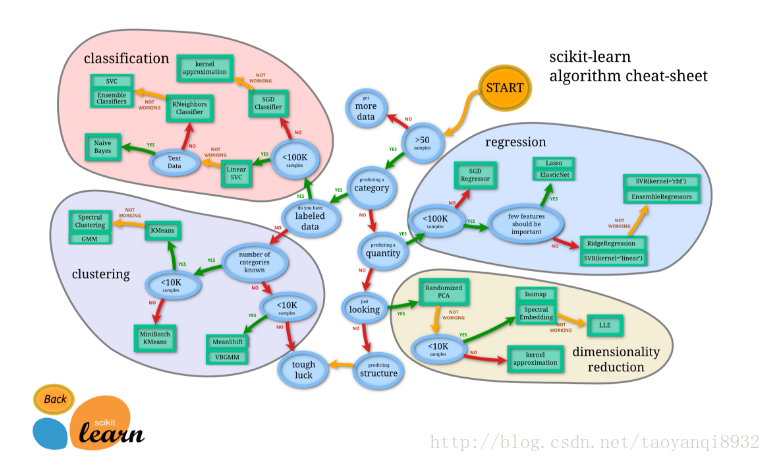
我们可以看到,机器学习分为四大块,分别是 classification (分类), clustering (聚类), regression (回归), dimensionality reduction (降维)。
安装scikit-learn
如果使用的是ubuntu则非常的简单,直接sudo apt-get install scikit-learn即可,这里可能会有要你安装别的依赖,也是同样的安装方法,如果是别的linux版本,可使用pip等工具进行安装。
测试:
# 不报错则表示安装成功
>>> import sklearn
>>> 安装XGBDT
本质上还是GBDT,只是对GBDT进行了一些更改,叫X (Extreme) GBoosted,它把速度和效率做到了极致。在scikit-learn目前还没有这个分类器,因此要进行单独的安装。
这里对linux的安装进行说明,其余操作系统见:
http://xgboost.readthedocs.io/en/latest/build.html
# 拉取源码包
git clone --recursive https://github.com/dmlc/xgboost
cd xgboost
# 编译
make -j4
# python包的安装
# 首先安装工具
sudo apt-get install python-setuptools
# 进入目录,安装
cd python-package
sudo python setup.py install
# 测试不报错,成功
>>> import xgboost
>>> scikit-learn测试
测试的数据为,美国一个区域的糖尿病的情况,具有以下的信息:
Attribute Information:
1. Number of times pregnant
2. Plasma glucose concentration a 2 hours in an oral glucose tolerance test
3. Diastolic blood pressure (mm Hg)
4. Triceps skin fold thickness (mm)
5. 2-Hour serum insulin (mu U/ml)
6. Body mass index (weight in kg/(height in m)^2)
7. Diabetes pedigree function
8. Age (years)
9. Class variable (0 or 1)
第9个是标签,即我们要预测的情况,0表示没有患病,1表示患病,数据集下载地址:
https://archive.ics.uci.edu/ml/datasets/Pima+Indians+Diabetes
完整代码如下,可以进行一键测试多个算法:
#!usr/bin/env python
#-*- coding: utf-8 -*-
import time
from sklearn import metrics
import numpy as np
from numpy import *
from sklearn import cross_validation
# Multinomial Naive Bayes Classifier
def naive_bayes_classifier(train_x, train_y):
from sklearn.naive_bayes import MultinomialNB
model = MultinomialNB(alpha=0.01)
model.fit(train_x, train_y)
return model
# KNN Classifier
def knn_classifier(train_x, train_y):
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=10)
model.fit(train_x, train_y)
return model
# Logistic Regression Classifier
def logistic_regression_classifier(train_x, train_y):
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(penalty='l2')
model.fit(train_x, train_y)
return model
# Random Forest Classifier
def random_forest_classifier(train_x, train_y):
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=100)
model.fit(train_x, train_y)
return model
# Decision Tree Classifier
def decision_tree_classifier(train_x, train_y):
from sklearn import tree
model = tree.DecisionTreeClassifier()
model.fit(train_x, train_y)
return model
# GBDT(Gradient Boosting Decision Tree) Classifier
def gradient_boosting_classifier(train_x, train_y):
from sklearn.ensemble import GradientBoostingClassifier
model = GradientBoostingClassifier(n_estimators=40)
model.fit(train_x, train_y)
return model
# SVM Classifier
def svm_classifier(train_x, train_y):
from sklearn.svm import SVC
model = SVC(kernel='rbf', probability=True)
model.fit(train_x, train_y)
return model
# SVM Classifier using cross validation
def svm_cross_validation(train_x, train_y):
from sklearn.grid_search import GridSearchCV
from sklearn.svm import SVC
model = SVC(kernel='rbf', probability=True)
param_grid = {'C': [1e-3, 1e-2, 1e-1, 1, 10, 100, 1000], 'gamma': [0.001, 0.0001]}
grid_search = GridSearchCV(model, param_grid, n_jobs = 1, verbose=1)
grid_search.fit(train_x, train_y)
best_parameters = grid_search.best_estimator_.get_params()
for para, val in best_parameters.items():
print para, val
model = SVC(kernel='rbf', C=best_parameters['C'], gamma=best_parameters['gamma'], probability=True)
model.fit(train_x, train_y)
return model
# XGBoost Classfier
def extreme_gradient_boosting_classifier(train_x,train_y):
import xgboost
model = xgboost.XGBClassifier()
model.fit(train_x,train_y)
return model
# read dataset
def read_data():
dataset = np.loadtxt('diabetes.txt',delimiter=',')
x = dataset[:,:8]
y = dataset[:,8]
seed = 7
test_size = 0.33
# split the dataset
train_x,test_x,train_y,test_y = cross_validation.train_test_split \
(x,y,test_size=test_size,random_state=seed)
return train_x, test_x, train_y, test_y
if __name__ == '__main__':
test_classifiers = ['NB','RF','SVM','KNN','LR','DT','GBDT','XGBDT']
classifiers = {'NB':naive_bayes_classifier,
'KNN':knn_classifier,
'LR':logistic_regression_classifier,
'RF':random_forest_classifier,
'DT':decision_tree_classifier,
'SVM':svm_classifier,
'SVMCV':svm_cross_validation,
'GBDT':gradient_boosting_classifier,
'XGBDT':extreme_gradient_boosting_classifier
}
print 'reading training and testing data...'
train_x, test_x, train_y, test_y = read_data()
num_train, num_feat = train_x.shape
num_test, num_feat = test_x.shape
is_binary_class = (len(np.unique(train_y)) == 2)
print '******************** Data Info *********************'
print '#training data: %d, #testing_data: %d, dimension: %d' % (num_train, num_test, num_feat)
for classifier in test_classifiers:
print '******************* %s ********************' % classifier
start_time = time.time()
model = classifiers[classifier](train_x, train_y)
print 'training took %fs!' % (time.time() - start_time)
predict = model.predict(test_x)
if is_binary_class:
precision = metrics.precision_score(test_y, predict)
recall = metrics.recall_score(test_y, predict)
print 'precision: %.2f%%, recall: %.2f%%' % (100 * precision, 100 * recall)
accuracy = metrics.accuracy_score(test_y, predict)
print 'accuracy: %.2f%%' % (100 * accuracy) 运行结果,可以看到在此问题上XGBDT效果稍微好一点,但是这是没有经过调参的,可以进行调参等预处理操作来改善效果。
yqtao@yqtao:~/machine-learn$ python sklean.py
reading training and testing data...
******************** Data Info *********************
#training data: 514, #testing_data: 254, dimension: 8
******************* NB ********************
training took 0.001360s!
precision: 48.35%, recall: 47.83%
accuracy: 62.60%
******************* RF ********************
training took 0.198425s!
precision: 71.26%, recall: 67.39%
accuracy: 78.35%
******************* SVMCV ********************
Fitting 3 folds for each of 14 candidates, totalling 42 fits
[Parallel(n_jobs=1)]: Done 42 out of 42 | elapsed: 1.5s finished
kernel rbf
C 1
verbose False
probability True
degree 3
shrinking True
max_iter -1
decision_function_shape None
random_state None
tol 0.001
cache_size 200
coef0 0.0
gamma 0.0001
class_weight None
training took 1.536800s!
precision: 69.84%, recall: 47.83%
accuracy: 73.62%
******************* KNN ********************
training took 0.003870s!
precision: 71.21%, recall: 51.09%
accuracy: 74.80%
******************* LR ********************
training took 0.003629s!
precision: 70.83%, recall: 55.43%
accuracy: 75.59%
******************* DT ********************
training took 0.002498s!
precision: 61.18%, recall: 56.52%
accuracy: 71.26%
******************* GBDT ********************
training took 0.033451s!
precision: 70.73%, recall: 63.04%
accuracy: 77.17%
******************* XGBDT ********************
training took 0.232969s!
precision: 70.45%, recall: 67.39%
accuracy: 77.95%参考资料:
http://scikit-learn.org/stable/
http://blog.csdn.net/zouxy09/article/details/48903179
http://blog.csdn.net/matrix_space/article/details/50541217















 3234
3234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









