






Preface
这是一篇加上我自己理解的译文,原文是kdnuggets网站上的一篇文章,也被收录进了Python Machine Learning Notebook中FAQ中。
昨天我看今日头条上也推送了这篇的译文:《在需要监督学习的情况下,选择深度学习还是随机森林或支持向量机》,但我觉得还是看原文,自己理解后,“翻译一遍更好”。
Comprehension & Translation
If we tackle a supervised learning problem, my advice is to start with the simplest hypothesis space first. I.e., try a linear model such as logistic regression. If this doesn’t work “well” (i.e., it doesn’t meet our expectation or performance criterion that we defined earlier), I would move on to the next experiment.
如果让我处理一个机器学习问题,我的建议是从最简单的模型开始,比如可以从线性模型,如Logistic Regression 模型尝试。如果它的效果不好,比如说结果不满足我们的期望或者不满足我们之前定好的性能评价标准,这时候我们进行下一阶段的尝试实验。
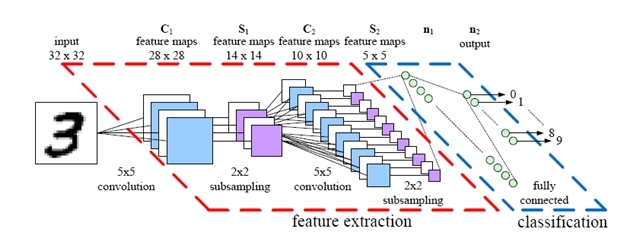
Random Forest vs. SVMs
I would say that random forests are probably THE “worry-free” approach - if such a thing exists in ML: There are no real hyperparameters to tune (maybe except for the number of trees; typically, the more trees we have the better). On the contrary, there are a lot of knobs to be turned in SVMs: Choosing the “right” kernel, regularization penalties, the slack variable, …
我想说的是,Random Forests可能是最不让人费心(worry-free)的一种方法 — 如果不让人费心的方法真的在机器学习中存在的话:它没有真正的超参数(hyperparameters)要我们去调(可能除了Random Forests中trees的数量,一般的来说,设置越多的trees,结果越好)。
相反的是,在SVMs中,有许多的参数需要去调试:选择正确的核函数(kernel),正则化惩罚项(regularization penalties),松弛变量(slack variable)……
Both random forests and SVMs are non-parametric models (i.e., the complexity grows as the number of training samples increases). Training a non-parametric model can thus be more expensive, computationally, compared to a generalized linear model, for example. The more trees we have, the more expensive it is to build a random forest. Also, we can end up with a lot of support vectors in SVMs; in the worst-case scenario, we have as many support vectors as we have samples in the training set. Although, there are multi-class SVMs, the typical implementation for multi-class classification is One-vs.-All; thus, we have to train an SVM for each class – in contrast, decision trees or random forests, which can handle multiple classes out of the box.
Random Forests以及SVMs都是非参数的模型方法(模型复杂度随着训练样本的增加而增长)。训练一个非参数模型因此会非常的耗时,相比较于一个生成的线性模型。在Random Forests中设置越多的trees,构建Random Forests所需要的代价也会随之增大。同样的,我们也可以通过在SVMs中设置许多的支持向量来完成,在最坏的情况下,SVMs中设置的支持向量的个数会与训练集中样本的个数相等。尽管也有多类SVMs,通过One-vs.-All的机制来实现多类分类,因此,我们需要对每一类训练一个SVM — 相比之下,Decision Trees 或者 Random Forests开箱即用地处理多类问题。
To summarize, random forests are much simpler to train for a practitioner; it’s easier to find a good, robust model. The complexity of a random forest grows with the number of trees in the forest, and the number of training samples we have. In SVMs, we typically need to do a fair amount of parameter tuning, and in addition to that, the computational cost grows linearly with the number of classes as well.
来做一个总结,Random Forests对一个从业者来说更容易去训练数据,更容易发现一个好的、鲁棒性强的模型。Random Forests的复杂性随着“森林”中trees和训练样本的数量的增多而增大。在SVMs中,我们不出意外的需要做大量的参数调整的工作,计算复杂度也会随着类别的增加而线性增长。
Deep Learning
As a rule of thumb, I’d say that SVMs are great for relatively small data sets with fewer outliers. Random forests may require more data but they almost always come up with a pretty robust model.
And deep learning algorithms… well, they require “relatively” large datasets to work well, and you also need the infrastructure to train them in reasonable time. Also, deep learning algorithms require much more experience: Setting up a neural network using deep learning algorithms is much more tedious than using an off-the-shelf classifiers such as random forests and SVMs. On the other hand, deep learning really shines when it comes to complex problems such as image classification, natural language processing, and speech recognition. Another advantage is that you have to worry less about the feature engineering part.
Again, in practice, the decision which classifier to choose really depends on your dataset and the general complexity of the problem – that’s where your experience as machine learning practitioner kicks in.
就经验来说,我会说SVMs非常适合用在存在较少极值的小样本数据集上。Random Forests可能会需要更多的数据,但是也会产生出更漂亮稳定的模型。
然后就是深度学习算法…额,它们需要“相对”大量大量的才能工作的好,你也需要在合理的时间内去训练一个架构。深度学习算法需要更大的代价:用深度学习算法设计一个神经网络比用现成的分类器如Random Forests、SVMs等乏味的多。但是另一方面,深度学习在遇到复杂的问题如图像分类、自然语言处理以及语音识别上表现很耀眼。深度学习的另一个优势是,你不用去担心特征工程的部分(因为深度学习会自动的提取特征)。
再强调以此,时实际操作中,选择什么样的分类器取决于你的数据集以及问题的一般复杂程度 — 这正是你作为一个机器学习实践者需要用你的经验干预的地方这也是你作为机器学习从业者会逐步获得的经验。。
If it comes to predictive performance, there are cases where SVMs do better than random forests and vice versa:
Caruana, Rich, and Alexandru Niculescu-Mizil. “An empirical comparison of supervised learning algorithms.” Proceedings of the 23rd international conference on Machine learning. ACM, 2006.
如果就预测性能而言,有许多情况下,SVMs比Random Forests要做的更高。反之也亦然,Random Forests在许多情况下比SVMs也要更好。下面这篇论文对监督学习算法做了对比:
Caruana, Rich, and Alexandru Niculescu-Mizil. “An empirical comparison of supervised learning algorithms.” Proceedings of the 23rd international conference on Machine learning. ACM, 2006.
The same is true for deep learning algorithms if you look at the MNIST benchmarks (http://yann.lecun.com/exdb/mnist/): The best-performing model in this set is a committee consisting of 35 ConvNets, which were reported to have a 0.23% test error; the best SVM model has a test error of 0.56%.
The ConvNet ensemble may reach a better accuracy (for the sake of this ensemble, let’s pretend that these are totally unbiased estimates), but without a question, I’d say that the 35 ConvNet committee is far more expensive (computationally). So, if you make that decision: Is a 0.33% improvement worth it? In some cases, it’s maybe worth it (e.g., in the financial sector for non-real time predictions), in other cases it perhaps won’t be worth it, though.
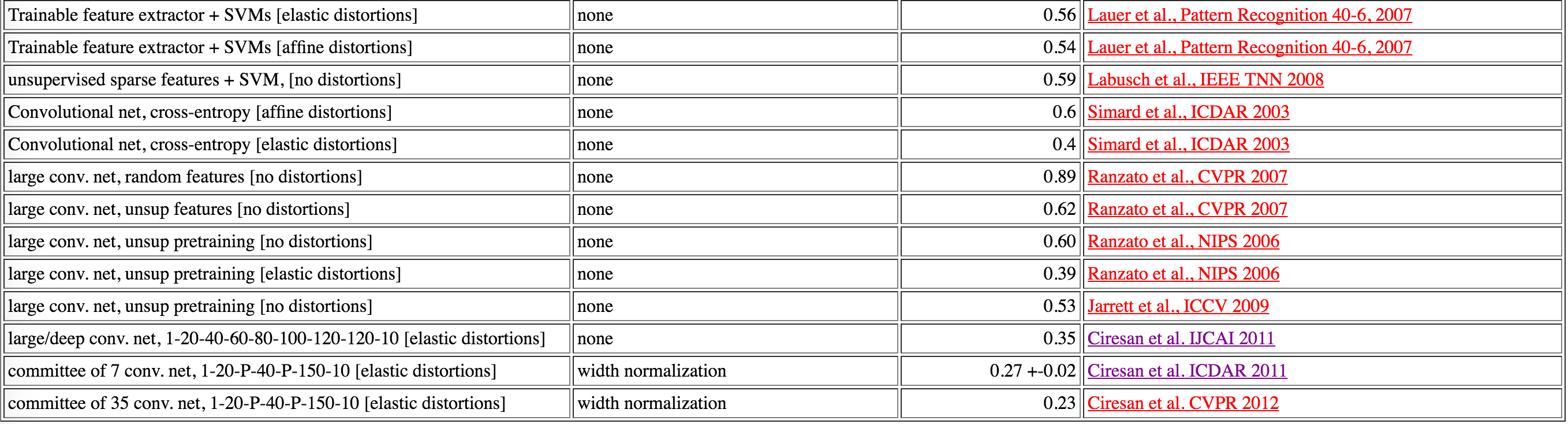
这个道理也同样适用于深度学习算法,如果你看MNIST标准集:对于这个数据集,最好的模型是由35个卷积层组合成的深度卷积网络,它只有0.23%的错误率;最好的SVM模型,其测试集上的错误率为0.56%。
深度卷积网络或许达到更好的精度(为了这样的结论,我们假设预测为无偏估计,也即系统误差为零的估计,无偏估计的数学解释,通俗解释)。但是毫无疑问的,35个卷积层组成的神经网络会付出高昂的代价(计算上的)。所以,如果让你做一定决定:为了这0.33%的提高,这样做值得吗?在某些情况下,或许会值得(如对于金融部门做非实时预测时)
,但是其他大部分情况下,这样做或许是不值得的。
So, my practical advice is:
Define a performance metric to evaluate your model
Ask yourself: What performance score is desired, what hardware is required, what is the project deadline
Start with the simplest model
If you don’t meet your expected goal, try more complex models (if possible)
所以,我的建议如下:
(1)先确定你的模型的效果评价指标;
(2)问你自己,你想要达到什么养的性能、效果,你需要什么样的硬件,你离项目的deadline还有多久;
(3)从最简单的模型开始(如最开始讲的线性模型,Logistic Regression);
(4)如果最简单的模型没有满足你的要求、期望,再开始尝试更复杂的模型(如果技术上可以的话)














 2983
2983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









