







caffe源码
本文主要包含如下内容:
- caffe源码
- caffeproto
- commonhpp和commoncpp
- internal_threadhpp和internal_threadcpp
- blobhpp和blobcpp
- layerhpp和layercpp
- nethpp和netcpp
- solverhpp和solvercpp
caffe.proto
位于src/caffe/proto目录下,该文件是一个消息格式文件,后缀为proto的文件即为消息协议原型定义文件,通过使用描述性语言来定义程序中需要用到的数据格式。
Caffe中,数据存储格式为Google Protocol Buffer,简称PB。PB是一种轻便、高效的结构化数据储存格式,可以用于结构化数据串行化,很适合做数据存储或RPC数据交换格式。它可以用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。
message表示需要传输的参数的结构体optional是一个可选成员,即消息中可以不包含该成员,如果包含成员而未进行初始化,会赋予默认默认值。required表明是必须包含该成员,且初值必须被提供。repeated表示可以重复多次的成员,出现零次也可以出现在成员中。属于blob的: BlobProto, BlobProtoVector, Datum
- 属于layer的: FillerParameter, LayerParameter,ArgMaxParameter,TransformationParameter, LossParameter, AccuracyParameter,ConcatParameter, ContrastiveLossParameter, ConvolutionParameter,
DataParameter, DropoutParameter, DummyDataParameter, EltwiseParameter,ExpParameter, HDF5DataParameter, HDF5OutputParameter, HingeLossParameter,ImageDataParameter, InfogainLossParameter, InnerProductParameter,LRNParameter, MemoryDataParameter, MVNParameter, PoolingParameter,PowerParameter, PythonParameter, ReLUParameter, SigmoidParameter,
SliceParameter, SoftmaxParameter, TanHParameter, ThresholdParameter等 - 属于net的: NetParameter, SolverParameter, SolverState, NetState, NetStateRule,
ParamSpec
自己定义proto,生成对应的.h和.c文件
package lm;
message helloworld
{
required int32 id = 1; // ID
required string str = 2; // str
optional int32 opt = 3; // optional field
} 控制台中输入:protoc -I=. --cpp_out=. ./caffe.proto,其中,-I表示proto所在路径,--cpp_out表示生成的头文件和实现文件所在的路径
生成对应的C++类的头文件Caffe.pb.h,以及对应的实现文件Caffe.pb.cc,里面是一些关于数据结构的标准化操作:
void CopyFrom();
void MergeFrom();
void Clear();
bool IsInitialized() const;
int ByteSize() const;
bool MergePartialFromCodedStream();
void SerializeWithCachedSizes() const;
SerializeWithCachedSizesToArray() const;
int GetCachedSize();
void SharedCtor();
void SharedDtor();
void SetCachedSize() const;
proto源码,粘贴重要部分
syntax = "proto2";
package caffe;
message BlobShape { //数据块形状,指定Blob的形状或维度
repeated int64 dim = 1 [packed = true]; //数据块形状定义为NUM*Channel*Height*Wight,采用高维数据的封装
}
message BlobProto { //数据块(数据 形状 微分)
optional BlobShape shape = 7; //维度
repeated float data = 5 [packed = true]; //前向传播计算数据
repeated float diff = 6 [packed = true]; //反向传播计算数据
repeated double double_data = 8 [packed = true];
repeated double double_diff = 9 [packed = true];
// 数据4D形状,已使用BlobShape shape代替
optional int32 num = 1 [default = 0];
optional int32 channels = 2 [default = 0];
optional int32 height = 3 [default = 0];
optional int32 width = 4 [default = 0];
}
...
message Datum { //数据层
optional int32 channels = 1; //图像通道数
optional int32 height = 2; //图像的高度
optional int32 width = 3; //图像的宽度
optional bytes data = 4; //真实的图像数据,以字节存储
optional int32 label = 5; //这张图片对应的标签
repeated float float_data = 6; //float类型的数据
optional bool encoded = 7 [default = false]; //是否需要解码
}
...
message NetParameter {
optional string name = 1; //网络的名字
repeated string input = 3; //输入blob的名字
repeated BlobShape input_shape = 8;
repeated int32 input_dim = 4; //输入层blob的维度
optional bool force_backward = 5 [default = false]; //网络是否进行反向传播
optional NetState state = 6;
optional bool debug_info = 7 [default = false];
repeated LayerParameter layer = 100; // ID 100 so layers are printed last.
repeated V1LayerParameter layers = 2;
}
...
message SolverParameter {
optional string net = 24;
optional NetParameter net_param = 25;
optional string train_net = 1; //训练网络的proto file
repeated string test_net = 2; //测试网络的Proto file
optional NetParameter train_net_param = 21; // Inline train net params.
repeated NetParameter test_net_param = 22; // Inline test net params.
optional NetState train_state = 26;
repeated NetState test_state = 27;
repeated int32 test_iter = 3; //每次测试时的迭代次数
optional int32 test_interval = 4 [default = 0]; //两次测试的间隔迭代次数
optional bool test_compute_loss = 19 [default = false]; //默认不计算loss
optional bool test_initialization = 32 [default = true]; //如果为真,则在训练前运行一次测试,以确保内存足够,并打印初始损失值
optional float base_lr = 5; //基础学习率
optional int32 display = 6; //打印信息的遍历间隔,设置为0则不打印
optional int32 average_loss = 33 [default = 1]; //打印最后一个迭代的平均loss
optional int32 max_iter = 7; //最大迭代次数
optional int32 iter_size = 36 [default = 1];
optional string lr_policy = 8; //学习率调节策略
optional float gamma = 9; // The parameter to compute the learning rate.
optional float power = 10; // The parameter to compute the learning rate.
optional float momentum = 11; //动量
optional float weight_decay = 12; //权值衰减
optional string regularization_type = 29 [default = "L2"];
optional int32 stepsize = 13; //学习速率的衰减步长
repeated int32 stepvalue = 34;
optional float clip_gradients = 35 [default = -1];
optional int32 snapshot = 14 [default = 0]; // The snapshot interval
optional string snapshot_prefix = 15; // The prefix for the snapshot.
optional bool snapshot_diff = 16 [default = false];
enum SnapshotFormat {
HDF5 = 0;
BINARYPROTO = 1;
}
optional SnapshotFormat snapshot_format = 37 [default = BINARYPROTO];
enum SolverMode {
CPU = 0;
GPU = 1;
}
optional SolverMode solver_mode = 17 [default = GPU];
optional int32 device_id = 18 [default = 0];
optional int64 random_seed = 20 [default = -1];
optional string type = 40 [default = "SGD"];
optional float delta = 31 [default = 1e-8];
optional float momentum2 = 39 [default = 0.999];
optional float rms_decay = 38 [default = 0.99];
optional bool debug_info = 23 [default = false];
optional bool snapshot_after_train = 28 [default = true];
enum SolverType {
SGD = 0;
NESTEROV = 1;
ADAGRAD = 2;
RMSPROP = 3;
ADADELTA = 4;
ADAM = 5;
}
optional SolverType solver_type = 30 [default = SGD];
}
...
message LayerParameter { //层参数(名称 类型 输入 输出 阶段 损失加权系数 全局乘数)
optional string name = 1; //类名称
optional string type = 2; //类类型
repeated string bottom = 3; //输入blob名称
repeated string top = 4; //输出blob名称
// The train / test phase for computation.
optional Phase phase = 10;
repeated float loss_weight = 5; //每层输出blob在目标损失函数中的加权系数,每层默认为0或1
repeated ParamSpec param = 6; //指定学习参数
repeated BlobProto blobs = 7; //每层数值参数的blobs
repeated bool propagate_down = 11; //指定是否向每个底部反向传播。如果未指定,Caffe将自动推断每个输入是否需要反向传播来计算参数梯度。如果为某些输入设置为true,则强制对这些输入的反向传播;如果某些输入设置为false,则跳过这些输入的反向传播。
repeated NetStateRule include = 8;
repeated NetStateRule exclude = 9;
optional TransformationParameter transform_param = 100;
optional LossParameter loss_param = 101;
//层类型指定参数
optional AccuracyParameter accuracy_param = 102;
optional ArgMaxParameter argmax_param = 103;
optional BatchNormParameter batch_norm_param = 139;
optional BiasParameter bias_param = 141;
optional ConcatParameter concat_param = 104;
optional ContrastiveLossParameter contrastive_loss_param = 105;
optional ConvolutionParameter convolution_param = 106;
optional CropParameter crop_param = 144;
optional DataParameter data_param = 107;
optional DropoutParameter dropout_param = 108;
optional DummyDataParameter dummy_data_param = 109;
optional EltwiseParameter eltwise_param = 110;
optional ELUParameter elu_param = 140;
optional EmbedParameter embed_param = 137;
optional ExpParameter exp_param = 111;
optional FlattenParameter flatten_param = 135;
optional HDF5DataParameter hdf5_data_param = 112;
optional HDF5OutputParameter hdf5_output_param = 113;
optional HingeLossParameter hinge_loss_param = 114;
optional ImageDataParameter image_data_param = 115;
optional InfogainLossParameter infogain_loss_param = 116;
optional InnerProductParameter inner_product_param = 117;
optional InputParameter input_param = 143;
optional LogParameter log_param = 134;
optional LRNParameter lrn_param = 118;
optional MemoryDataParameter memory_data_param = 119;
optional MVNParameter mvn_param = 120;
optional ParameterParameter parameter_param = 145;
optional PoolingParameter pooling_param = 121;
optional PowerParameter power_param = 122;
optional PReLUParameter prelu_param = 131;
optional PythonParameter python_param = 130;
optional RecurrentParameter recurrent_param = 146;
optional ReductionParameter reduction_param = 136;
optional ReLUParameter relu_param = 123;
optional ReshapeParameter reshape_param = 133;
optional ScaleParameter scale_param = 142;
optional SigmoidParameter sigmoid_param = 124;
optional SoftmaxParameter softmax_param = 125;
optional SPPParameter spp_param = 132;
optional SliceParameter slice_param = 126;
optional TanHParameter tanh_param = 127;
optional ThresholdParameter threshold_param = 128;
optional TileParameter tile_param = 138;
optional WindowDataParameter window_data_param = 129;
}
// Data 参数
message DataParameter {
// 只支持下面两种数据格式
enum DB {
LEVELDB = 0;
LMDB = 1;
}
// 指定数据路径
optional string source = 1;
// 指定batchsize
optional uint32 batch_size = 4;
// 指定数据格式
optional DB backend = 8 [default = LEVELDB];
// 强制将图片转为三通道彩色图片
optional bool force_encoded_color = 9 [default = false];
// 预先存取多少个batch到host memory
// (每次forward完成之后再全部重新取一个batch比较浪费时间),
// increase if data access bandwidth varies).
optional uint32 prefetch = 10 [default = 4];
}common.hpp和common.cpp
命名空间的使用:google cv caffe,然后在项目中就可以随意使用.单例化caffe类,并且封装了boost和cuda随机数生成的函数,提供了统一接口
common.hpp
#ifndef CAFFE_COMMON_HPP_
#define CAFFE_COMMON_HPP_
#include <boost/shared_ptr.hpp>
#include <gflags/gflags.h>
#include <glog/logging.h>
#include <climits>
#include <cmath>
#include <fstream>
#include <iostream>
#include <map>
#include <set>
#include <sstream>
#include <string>
#include <utility>
#include <vector>
#include "caffe/util/device_alternate.hpp"
#define STRINGIFY(m) #m
#define AS_STRING(m) STRINGIFY(m)
// 使用GFLAGS_GFLAGS_H_来检测是否为2.1版本,将命名空间google更改为gflags
#ifndef GFLAGS_GFLAGS_H_
namespace gflags = google;
#endif // GFLAGS_GFLAGS_H_
// 禁止某个类通过构造函数直接初始化为另一个类(copy,copy assignment),声明在private即可完成目的
#define DISABLE_COPY_AND_ASSIGN(classname) \
private:\
classname(const classname&);\
classname& operator=(const classname&)
// 模板类实例化,用float和double规范实例化一个类
#define INSTANTIATE_CLASS(classname) \
char gInstantiationGuard##classname; \
template class classname<float>; \
template class classname<double>
// 初始化GPU的前向传播函数
#define INSTANTIATE_LAYER_GPU_FORWARD(classname) \
template void classname<float>::Forward_gpu( \
const std::vector<Blob<float>*>& bottom, \
const std::vector<Blob<float>*>& top); \
template void classname<double>::Forward_gpu( \
const std::vector<Blob<double>*>& bottom, \
const std::vector<Blob<double>*>& top);
// 初始化GPU的反向传播函数
#define INSTANTIATE_LAYER_GPU_BACKWARD(classname) \
template void classname<float>::Backward_gpu( \
const std::vector<Blob<float>*>& top, \
const std::vector<bool>& propagate_down, \ //指定是否进行反向传播
const std::vector<Blob<float>*>& bottom); \
template void classname<double>::Backward_gpu( \
const std::vector<Blob<double>*>& top, \
const std::vector<bool>& propagate_down, \
const std::vector<Blob<double>*>& bottom)
//初始化GPU的前向传播和反向传播函数,即对其进行了封装
#define INSTANTIATE_LAYER_GPU_FUNCS(classname) \
INSTANTIATE_LAYER_GPU_FORWARD(classname); \
INSTANTIATE_LAYER_GPU_BACKWARD(classname)
// 一个简单的宏来标记未实现的代码_Not Implemented Yet
#define NOT_IMPLEMENTED LOG(FATAL) << "Not Implemented Yet"
// See PR #1236
namespace cv { class Mat; }
namespace caffe {
// 使用boost的shared_ptr智能指针,而不是C++11,因为现在的cuda不支持
using boost::shared_ptr;
// Common functions and classes from std that caffe often uses.
using std::fstream;
using std::ios;
using std::isnan;
using std::isinf;
using std::iterator;
using std::make_pair;
using std::map;
using std::ostringstream;
using std::pair;
using std::set;
using std::string;
using std::stringstream;
using std::vector;
// 一个全局初始化函数,初始化gflags和glog,您应该在主函数中调用该函数。目前,它初始化了google标志和谷歌日志记录。
void GlobalInit(int* pargc, char*** pargv);
// Caffe 类
class Caffe {
public:
~Caffe();
// Get 函数利用Boost的局部线程储存功能,Get()就是Caffe类
static Caffe& Get();
enum Brew { CPU, GPU };
// random number generator 随机数生成器
class RNG {
public:
RNG(); //利用系统的熵池或者时间来初始化RNG内部的generator_
explicit RNG(unsigned int seed);
explicit RNG(const RNG&);
RNG& operator=(const RNG&);
void* generator();
private:
class Generator;
shared_ptr<Generator> generator_;
};
// Getters for boost rng, curand, and cublas handles
inline static RNG& rng_stream() {
if (!Get().random_generator_) {
Get().random_generator_.reset(new RNG());
}
return *(Get().random_generator_);
}
#ifndef CPU_ONLY
inline static cublasHandle_t cublas_handle() { return Get().cublas_handle_; }
inline static curandGenerator_t curand_generator() {
return Get().curand_generator_;
}
#endif
/*设置CPU和GPU以及训练的时候线程并行数目*/
// Returns the mode: running on CPU or GPU.
inline static Brew mode() { return Get().mode_; }
// 变量的设置器设置模式
inline static void set_mode(Brew mode) { Get().mode_ = mode; }
// 手动设定随机数生成器的种子
static void set_random_seed(const unsigned int seed);
// Sets the device. Since we have cublas and curand stuff, set device also
// requires us to reset those values.
static void SetDevice(const int device_id);
// Prints the current GPU status. 显示当前GPU的状态
static void DeviceQuery();
// Check if specified device is available
static bool CheckDevice(const int device_id);
// 设置设备id
static int FindDevice(const int start_id = 0);
// Parallel training info
inline static int solver_count() { return Get().solver_count_; }
inline static void set_solver_count(int val) { Get().solver_count_ = val; }
inline static bool root_solver() { return Get().root_solver_; }
inline static void set_root_solver(bool val) { Get().root_solver_ = val; }
protected:
#ifndef CPU_ONLY
cublasHandle_t cublas_handle_;
curandGenerator_t curand_generator_;
#endif
shared_ptr<RNG> random_generator_;
Brew mode_;
int solver_count_;
bool root_solver_;
private:
// 实现中构造函数被声明为私有方法,这样从根本上杜绝外部使用构造函数生成新的实例
Caffe();
// 同时禁用拷贝函数与赋值操作符(声明为私有但是不提供实现)避免通过拷贝函数或赋值操作生成新实例。
DISABLE_COPY_AND_ASSIGN(Caffe);
};
} // namespace caffe
#endif // CAFFE_COMMON_HPP_internal_thread.hpp和internal_thread.cpp
InternalThread类实际上就是boost库的thread的封装,对线程进行控制和使用,类的构造函数默认初始化boost::thread,析构函数直接调用线程停止函数.成员函数包括开始线程,结束线程,判断线程是否开始,要求线程结束.
internal_thread.hpp
#ifndef CAFFE_INTERNAL_THREAD_HPP_
#define CAFFE_INTERNAL_THREAD_HPP_
#include "caffe/common.hpp"
namespace boost { class thread; }
namespace caffe {
/**
* Virtual class encapsulate boost::thread for use in base class
* The child class will acquire the ability to run a single thread,
* by reimplementing the virtual function InternalThreadEntry.
* 封装了pthread函数,继承的子类可以得到一个单独的线程,主要作用是
* 在计算当前的一批数据时,在后台获取新一批的数据。
*/
class InternalThread {
public:
InternalThread() : thread_() {} //构造函数
virtual ~InternalThread(); //析构函数
/**
* Caffe's thread local state will be initialized using the current
* thread values, e.g. device id, solver index etc. The random seed
* is initialized using caffe_rng_rand.
* caffe的线程局部状态将使用当前线程值来进行初始化,例如设备id,solver的编号,随机数种子.
*/
void StartInternalThread();
/** Will not return until the internal thread has exited. */
void StopInternalThread(); //停止内部线程函数
bool is_started() const; //线程退出之前不会返回
protected:
/* Implement this method in your subclass
with the code you want your thread to run. */
virtual void InternalThreadEntry() {} //定义了一个虚函数,要求继承类中实现相关代码
/* Should be tested when running loops to exit when requested. */
bool must_stop(); //是否应该进行通过测试以退出循环,检测终结条件的退出方式
private:
void entry(int device, Caffe::Brew mode, int rand_seed, int solver_count,
bool root_solver);
shared_ptr<boost::thread> thread_;
};
} // namespace caffe
#endif // CAFFE_INTERNAL_THREAD_HPP_internal_thread.cpp
#include <boost/thread.hpp>
#include <exception>
#include "caffe/internal_thread.hpp"
#include "caffe/util/math_functions.hpp"
namespace caffe {
InternalThread::~InternalThread() { //析构函数,调用停止内部线程函数
StopInternalThread();
}
bool InternalThread::is_started() const { //测试程序是否已经开启
return thread_ && thread_->joinable();
}
bool InternalThread::must_stop() { //自动检查终结条件的退出方式
return thread_ && thread_->interruption_requested();
}
void InternalThread::StartInternalThread() { //初始化线程
CHECK(!is_started()) << "Threads should persist and not be restarted.";
int device = 0;
#ifndef CPU_ONLY
CUDA_CHECK(cudaGetDevice(&device));
#endif
Caffe::Brew mode = Caffe::mode();
int rand_seed = caffe_rng_rand();
int solver_count = Caffe::solver_count();
bool root_solver = Caffe::root_solver();
try { //重新实例化一个thread对象给thread_指针,该线程的执行是entry函数
thread_.reset(new boost::thread(&InternalThread::entry, this, device, mode,
rand_seed, solver_count, root_solver));
} catch (std::exception& e) {
LOG(FATAL) << "Thread exception: " << e.what();
}
}
void InternalThread::entry(int device, Caffe::Brew mode, int rand_seed,
int solver_count, bool root_solver) { //线程所要执行的函数
#ifndef CPU_ONLY
CUDA_CHECK(cudaSetDevice(device));
#endif
Caffe::set_mode(mode);
Caffe::set_random_seed(rand_seed);
Caffe::set_solver_count(solver_count);
Caffe::set_root_solver(root_solver);
InternalThreadEntry();
}
void InternalThread::StopInternalThread() { //停止线程
if (is_started()) { //如果线程已经开始了
thread_->interrupt(); //打断线程
try {
thread_->join(); //等待线程结束
} catch (boost::thread_interrupted&) { //如果被打断,啥也不干
} catch (std::exception& e) { //如果发生其他错误则记录到日志
LOG(FATAL) << "Thread exception: " << e.what();
}
}
}
} // namespace caffeblob.hpp和blob.cpp
Blob是四维连续数组(4-D, type = float32),如果使用(n,k,h,w)表示的话,每一维的意思分别是:
- n: numbei.输入数据量,比如mini-batch的大小.
- c: channel.通道数量.
- h,w: height,width.图像的高度和宽度.
Blob里面定义的函数:
Reshape(): 改变一个blob的大小;
ReshapeLike(): 为data和diff重新分配一块空间
Num_axes(): 返回blob的维度,要是是4维的话,返回4.
Count(): 计算得到count = num * channels * height * width
Offset(): 可以得到输入blob数据(n,k,h,w)的偏移量位置
CopyFrom(): 从source拷贝数据,copy_diff来作为标志区分是拷贝data还是diff
FromProto(): 从proto读数据进来,反序列化
ToProto(): 把blob数据保存到proto中.
blob.hpp
主要是分配内存和释放内存。class yncedMemory定义了内存分配管理和CPU与GPU之间同步的函数。
Blob会使用SyncedMem自动决定什么时候去copy data以提高运行效率,通常情况是仅当gnu或cpu修改后有copy操作。
#ifndef CAFFE_BLOB_HPP_
#define CAFFE_BLOB_HPP_
#include <algorithm>
#include <string>
#include <vector>
#include "caffe/common.hpp" //单例化caffe类,并且封装了boost和cuda随机数生成的函数,提供了统一接口
#include "caffe/proto/caffe.pb.h"
#include "caffe/syncedmem.hpp"
const int kMaxBlobAxes = 32;
namespace caffe {
/**
* @brief A wrapper around SyncedMemory holders serving as the basic
* computational unit through which Layer%s, Net%s, and Solver%s
* interact.
*
* TODO(dox): more thorough description.
*/
template <typename Dtype>
class Blob {
public:
Blob() : data_(), diff_(), count_(0), capacity_(0) {} //默认构造函数:初始化列表 {空函数体}
// 当构造函数被声明 explicit 时,编译器将不使用它作为转换操作符,禁止单参数构造函数的隐式转换
explicit Blob(const int num, const int channels, const int height,
const int width); //可以通过设置数据维度(N,C,H,W)初始化
explicit Blob(const vector<int>& shape); //也可以通过传入vector<int>直接传入维数
/// @brief Deprecated; use <code>Reshape(const vector<int>& shape)</code>.
void Reshape(const int num, const int channels, const int height,
const int width);
/*
*Blob作为一个最基础的类,其中构造函数开辟一个内存空间来存储数据, Reshape 函数在 Layer 中的
*reshape或者forward操作中来 adjust the dimensions of a top blob 。同时在改变 Blob 大小时,
*内存将会被重新分配如果内存大小不够了,并且额外的内存将不会被释放。对 input 的 blob 进行 reshape,
* 如果立⻢调用 Net::Backward 是会出错的,因为 reshape 之后,要么 Net::forward 或者 Net::Reshape
* 就会被调用来将新的 input shape 传播到高层
*/
void Reshape(const vector<int>& shape);
void Reshape(const BlobShape& shape);
void ReshapeLike(const Blob& other);
// 内联函数:通过内联函数,编译器不需要跳转到内存其他地址去执行函数调用,也不需要保留函数对调用时的现场数据,好处是可以节省调用的开销,但代码总量上升
// 输出blol的形状,用于打印blob的log
inline string shape_string() const {
ostringstream stream;
for (int i = 0; i < shape_.size(); ++i) {
stream << shape_[i] << " ";
}
stream << "(" << count_ << ")";
return stream.str();
}
// 获取shape
inline const vector<int>& shape() const { return shape_; }
// 获取index维的大小,返回某一维的尺寸,对于维数(N,C,H,W),shape(0)返回N,shape(-1)返回W。
inline int shape(int index) const {
return shape_[CanonicalAxisIndex(index)];
}
// 返回Blob维度数,对于维数(N,C,H,W),返回4
inline int num_axes() const { return shape_.size(); }
// 返回Blob维度数,对于维数(N,C,H,W),返回N×C×H×W,当前data的大小
inline int count() const { return count_; }
/*
*多个count()函数,主要为了统计Blob的容量(volume), 或者是某一片(slice),从某个axis到具体某个axis的
*shape乘机
*/
// 获取某几维数据的大小,对于维数(N,C,H,W),count(0, 3)返回N×C×H
inline int count(int start_axis, int end_axis) const {
CHECK_LE(start_axis, end_axis);
CHECK_GE(start_axis, 0);
CHECK_GE(end_axis, 0);
CHECK_LE(start_axis, num_axes());
CHECK_LE(end_axis, num_axes());
int count = 1;
for (int i = start_axis; i < end_axis; ++i) {
count *= shape(i);
}
return count;
}
// 获取某一维到结束数据的大小,对于维数(N,C,H,W),count(1)返回C×H×W
inline int count(int start_axis) const {
return count(start_axis, num_axes());
}
// 标准化索引,主要对参数索引进行标准化,以满足要求,转换坐标轴索引[-N, N]为[0, N]
inline int CanonicalAxisIndex(int axis_index) const {
CHECK_GE(axis_index, -num_axes())
<< "axis " << axis_index << " out of range for " << num_axes()
<< "-D Blob with shape " << shape_string();
CHECK_LT(axis_index, num_axes())
<< "axis " << axis_index << " out of range for " << num_axes()
<< "-D Blob with shape " << shape_string();
if (axis_index < 0) {
return axis_index + num_axes();
}
return axis_index;
}
// Blob中的4个基本变量num,channel,height,width可以直接通过shape(0)shape(1)shape(2)shape(3)来访问
/// @brief Deprecated legacy shape accessor num: use shape(0) instead.
inline int num() const { return LegacyShape(0); }
/// @brief Deprecated legacy shape accessor channels: use shape(1) instead.
inline int channels() const { return LegacyShape(1); }
/// @brief Deprecated legacy shape accessor height: use shape(2) instead.
inline int height() const { return LegacyShape(2); }
/// @brief Deprecated legacy shape accessor width: use shape(3) instead.
inline int width() const { return LegacyShape(3); }
inline int LegacyShape(int index) const {
CHECK_LE(num_axes(), 4)
<< "Cannot use legacy accessors on Blobs with > 4 axes.";
CHECK_LT(index, 4);
CHECK_GE(index, -4);
if (index >= num_axes() || index < -num_axes()) {
// Axis is out of range, but still in [0, 3] (or [-4, -1] for reverse
// indexing) -- this special case simulates the one-padding used to fill
// extraneous axes of legacy blobs.
return 1;
}
return shape(index);
}
// 计算offset物理偏移量,(n,c,h,w)的偏移量为((n*channels()+c)*height()+h)*width()+w
inline int offset(const int n, const int c = 0, const int h = 0,
const int w = 0) const {
CHECK_GE(n, 0);
CHECK_LE(n, num());
CHECK_GE(channels(), 0);
CHECK_LE(c, channels());
CHECK_GE(height(), 0);
CHECK_LE(h, height());
CHECK_GE(width(), 0);
CHECK_LE(w, width());
return ((n * channels() + c) * height() + h) * width() + w;
}
inline int offset(const vector<int>& indices) const {
CHECK_LE(indices.size(), num_axes());
int offset = 0;
for (int i = 0; i < num_axes(); ++i) {
offset *= shape(i);
if (indices.size() > i) {
CHECK_GE(indices[i], 0);
CHECK_LT(indices[i], shape(i));
offset += indices[i];
}
}
return offset;
}
/**
* @brief Copy from a source Blob.
*
* @param source the Blob to copy from
* @param copy_diff: if false, copy the data; if true, copy the diff
* @param reshape: if false, require this Blob to be pre-shaped to the shape
* of other (and die otherwise); if true, Reshape this Blob to other's
* shape if necessary
*/
// 从source拷贝数据, copy_diff来作为标志区分是拷贝data还是diff。
void CopyFrom(const Blob<Dtype>& source, bool copy_diff = false,
bool reshape = false);
/*
* 这一部分函数主要通过给定的位置访问数据,根据位置计算与数据起始的偏差offset,在通过cpu_data*指针获* 得地址
*/
// 获取某位置的data_数据
inline Dtype data_at(const int n, const int c, const int h,
const int w) const {
return cpu_data()[offset(n, c, h, w)];
}
// 获取某位置的diff_数据
inline Dtype diff_at(const int n, const int c, const int h,
const int w) const {
return cpu_diff()[offset(n, c, h, w)];
}
inline Dtype data_at(const vector<int>& index) const {
return cpu_data()[offset(index)];
}
inline Dtype diff_at(const vector<int>& index) const {
return cpu_diff()[offset(index)];
}
inline const shared_ptr<SyncedMemory>& data() const {
CHECK(data_);
return data_;
}
inline const shared_ptr<SyncedMemory>& diff() const {
CHECK(diff_);
return diff_;
}
const Dtype* cpu_data() const; // 访问数据,只读数据
void set_cpu_data(Dtype* data); // 设置data_的cpu指针,只是修改了指针
const int* gpu_shape() const;
const Dtype* gpu_data() const; // 获取data_的gpu指针
const Dtype* cpu_diff() const; // 获取diff_的cpu指针
const Dtype* gpu_diff() const; // 获取diff_的gpu指针
Dtype* mutable_cpu_data(); // mutable方式可改写数据
Dtype* mutable_gpu_data();
Dtype* mutable_cpu_diff();
Dtype* mutable_gpu_diff();
void Update(); // 更新data_的数据,减去diff_的数据,就是合并data和diff
void FromProto(const BlobProto& proto, bool reshape = true); // 从proto读数据进来,其实就是反序列化
void ToProto(BlobProto* proto, bool write_diff = false) const; // blob数据保存到proto中
// 计算L1范数
/// @brief Compute the sum of absolute values (L1 norm) of the data.
Dtype asum_data() const;
/// @brief Compute the sum of absolute values (L1 norm) of the diff.
Dtype asum_diff() const;
// 计算L2范数
/// @brief Compute the sum of squares (L2 norm squared) of the data.
Dtype sumsq_data() const;
/// @brief Compute the sum of squares (L2 norm squared) of the diff.
Dtype sumsq_diff() const;
// 正规化,进行相应的尺度变化
/// @brief Scale the blob data by a constant factor.
void scale_data(Dtype scale_factor);
/// @brief Scale the blob diff by a constant factor.
void scale_diff(Dtype scale_factor);
/**
* @brief Set the data_ shared_ptr to point to the SyncedMemory holding the
* data_ of Blob other -- useful in Layer%s which simply perform a copy
* in their Forward pass.
*
* This deallocates the SyncedMemory holding this Blob's data_, as
* shared_ptr calls its destructor when reset with the "=" operator.
*/
void ShareData(const Blob& other); // Blob& other 赋值给data_
/**
* @brief Set the diff_ shared_ptr to point to the SyncedMemory holding the
* diff_ of Blob other -- useful in Layer%s which simply perform a copy
* in their Forward pass.
*
* This deallocates the SyncedMemory holding this Blob's diff_, as
* shared_ptr calls its destructor when reset with the "=" operator.
*/
void ShareDiff(const Blob& other); //Blob& other 赋值给diff_
bool ShapeEquals(const BlobProto& other); //判断other与本blob形状是否相同
protected:
shared_ptr<SyncedMemory> data_; //存储前向传递数据
shared_ptr<SyncedMemory> diff_; //存储反向传递梯度
shared_ptr<SyncedMemory> shape_data_;
vector<int> shape_; //参数维度
int count_; //Blob存储的元素个数(shape_所有元素乘积)
int capacity_; //当前Blob的元素个数(控制动态分配)
DISABLE_COPY_AND_ASSIGN(Blob); //禁止拷贝和赋值运算
}; // class Blob
} // namespace caffe
#endif // CAFFE_BLOB_HPP_blob.cpp
#include <climits>
#include <vector>
#include "caffe/blob.hpp"
#include "caffe/common.hpp"
#include "caffe/syncedmem.hpp"
#include "caffe/util/math_functions.hpp"
namespace caffe {
// 改变Blob的维度,将num,channels,height,width传递给vector<Dtype> shape
template <typename Dtype>
void Blob<Dtype>::Reshape(const int num, const int channels, const int height,
const int width) {
vector<int> shape(4);
shape[0] = num;
shape[1] = channels;
shape[2] = height;
shape[3] = width;
Reshape(shape);
}
template <typename Dtype>
// 完成blob形状shape_的记录,大小count_的计算,合适大小capacity_存储的申请
void Blob<Dtype>::Reshape(const vector<int>& shape) {
CHECK_LE(shape.size(), kMaxBlobAxes);
count_ = 1;
shape_.resize(shape.size());
if (!shape_data_ || shape_data_->size() < shape.size() * sizeof(int)) {
shape_data_.reset(new SyncedMemory(shape.size() * sizeof(int)));
} //为shape存储大小数据重新开辟空间
int* shape_data = static_cast<int*>(shape_data_->mutable_cpu_data());
for (int i = 0; i < shape.size(); ++i) {
CHECK_GE(shape[i], 0);
CHECK_LE(shape[i], INT_MAX / count_) << "blob size exceeds INT_MAX";
count_ *= shape[i];
shape_[i] = shape[i];
shape_data[i] = shape[i];
}
if (count_ > capacity_) { //由于count_超过了当前capacity,因此需要重新分配空间
capacity_ = count_;
data_.reset(new SyncedMemory(capacity_ * sizeof(Dtype))); // 只是构造了SyncedMemory对象,并未真正分配内存和显存,真正分配是在第一次访问数据时,为data_数据重新开辟空回
diff_.reset(new SyncedMemory(capacity_ * sizeof(Dtype))); // 为diff_数据重新开辟空间
}
}
template <typename Dtype> // BlobShape 在caffe.proto 中定义,将BlobShape类型的数据 转换为vector<int>
void Blob<Dtype>::Reshape(const BlobShape& shape) {
CHECK_LE(shape.dim_size(), kMaxBlobAxes);
vector<int> shape_vec(shape.dim_size());
for (int i = 0; i < shape.dim_size(); ++i) {
shape_vec[i] = shape.dim(i);
}
Reshape(shape_vec);
}
template <typename Dtype> //用已知Blob的shape来对shape_进行reshape
void Blob<Dtype>::ReshapeLike(const Blob<Dtype>& other) {
Reshape(other.shape());
}
//Blob初始化,用num,channels,height,width初始化
template <typename Dtype>
Blob<Dtype>::Blob(const int num, const int channels, const int height,
const int width)
// capacity_ must be initialized before calling Reshape
: capacity_(0) { //在Reshape之前,需要将capacity初始化
Reshape(num, channels, height, width);
}
//用shape 初始化
template <typename Dtype>
Blob<Dtype>::Blob(const vector<int>& shape)
// capacity_ must be initialized before calling Reshape
: capacity_(0) {
Reshape(shape);
}
//返回gpu中的数据,并返回内存指针
template <typename Dtype>
const int* Blob<Dtype>::gpu_shape() const {
CHECK(shape_data_);
return (const int*)shape_data_->gpu_data();
}
// 调用SyncedMemory的数据访问函数cpu_data(),并返回内存指针
template <typename Dtype>
const Dtype* Blob<Dtype>::cpu_data() const {
CHECK(data_);
return (const Dtype*)data_->cpu_data();
}
// 设置cpu 数据
template <typename Dtype>
void Blob<Dtype>::set_cpu_data(Dtype* data) {
CHECK(data);
data_->set_cpu_data(data);
}
template <typename Dtype>
const Dtype* Blob<Dtype>::gpu_data() const {
CHECK(data_);
return (const Dtype*)data_->gpu_data();
}
//调用SyncedMemory的数据访问函数cpu_diff(),并返回内存指针
template <typename Dtype>
const Dtype* Blob<Dtype>::cpu_diff() const {
CHECK(diff_);
return (const Dtype*)diff_->cpu_data();
}
template <typename Dtype>
const Dtype* Blob<Dtype>::gpu_diff() const {
CHECK(diff_);
return (const Dtype*)diff_->gpu_data();
}
template <typename Dtype>
Dtype* Blob<Dtype>::mutable_cpu_data() {
CHECK(data_);
return static_cast<Dtype*>(data_->mutable_cpu_data());
}
template <typename Dtype>
Dtype* Blob<Dtype>::mutable_gpu_data() {
CHECK(data_);
return static_cast<Dtype*>(data_->mutable_gpu_data());
}
template <typename Dtype>
Dtype* Blob<Dtype>::mutable_cpu_diff() {
CHECK(diff_);
return static_cast<Dtype*>(diff_->mutable_cpu_data());
}
template <typename Dtype>
Dtype* Blob<Dtype>::mutable_gpu_diff() {
CHECK(diff_);
return static_cast<Dtype*>(diff_->mutable_gpu_data());
}
//当前的blob的data_指向other.data()的数据
template <typename Dtype>
void Blob<Dtype>::ShareData(const Blob& other) {
CHECK_EQ(count_, other.count());
data_ = other.data();
}
template <typename Dtype>
void Blob<Dtype>::ShareDiff(const Blob& other) {
CHECK_EQ(count_, other.count());
diff_ = other.diff();
}
// The "update" method is used for parameter blobs in a Net, which are stored
// as Blob<float> or Blob<double> -- hence we do not define it for
// Blob<int> or Blob<unsigned int>.
template <> void Blob<unsigned int>::Update() { NOT_IMPLEMENTED; }
template <> void Blob<int>::Update() { NOT_IMPLEMENTED; }
// 更新单个参数权值,updata函数用于参数blob参数的更新
template <typename Dtype>
void Blob<Dtype>::Update() {
// We will perform update based on where the data is located.
switch (data_->head()) {
case SyncedMemory::HEAD_AT_CPU: // 参数更新,新参数(data_) = 原参数(data_) - 梯度(diff_)
// perform computation on CPU
caffe_axpy<Dtype>(count_, Dtype(-1),
static_cast<const Dtype*>(diff_->cpu_data()),
static_cast<Dtype*>(data_->mutable_cpu_data()));
break;
case SyncedMemory::HEAD_AT_GPU:
case SyncedMemory::SYNCED:
#ifndef CPU_ONLY
// perform computation on GPU // 在gpu上参数更新
caffe_gpu_axpy<Dtype>(count_, Dtype(-1),
static_cast<const Dtype*>(diff_->gpu_data()),
static_cast<Dtype*>(data_->mutable_gpu_data()));
#else
NO_GPU;
#endif
break;
default:
LOG(FATAL) << "Syncedmem not initialized.";
}
}
template <> unsigned int Blob<unsigned int>::asum_data() const {
NOT_IMPLEMENTED;
return 0;
}
template <> int Blob<int>::asum_data() const {
NOT_IMPLEMENTED;
return 0;
}
template <typename Dtype>
Dtype Blob<Dtype>::asum_data() const { //计算data_ L1范式,计算所有元素绝对值之和
if (!data_) { return 0; }
switch (data_->head()) {
case SyncedMemory::HEAD_AT_CPU:
return caffe_cpu_asum(count_, cpu_data());
case SyncedMemory::HEAD_AT_GPU:
case SyncedMemory::SYNCED:
#ifndef CPU_ONLY
{
Dtype asum;
caffe_gpu_asum(count_, gpu_data(), &asum);
return asum;
}
#else
NO_GPU;
#endif
case SyncedMemory::UNINITIALIZED:
return 0;
default:
LOG(FATAL) << "Unknown SyncedMemory head state: " << data_->head();
}
return 0;
}
template <> unsigned int Blob<unsigned int>::asum_diff() const {
NOT_IMPLEMENTED;
return 0;
}
template <> int Blob<int>::asum_diff() const {
NOT_IMPLEMENTED;
return 0;
}
template <typename Dtype>
Dtype Blob<Dtype>::asum_diff() const { //计算diff_ L1范式,所有元素的元素的绝对值之和
if (!diff_) { return 0; }
switch (diff_->head()) {
case SyncedMemory::HEAD_AT_CPU:
return caffe_cpu_asum(count_, cpu_diff());
case SyncedMemory::HEAD_AT_GPU:
case SyncedMemory::SYNCED:
#ifndef CPU_ONLY
{
Dtype asum;
caffe_gpu_asum(count_, gpu_diff(), &asum);
return asum;
}
#else
NO_GPU;
#endif
case SyncedMemory::UNINITIALIZED:
return 0;
default:
LOG(FATAL) << "Unknown SyncedMemory head state: " << diff_->head();
}
return 0;
}
template <> unsigned int Blob<unsigned int>::sumsq_data() const {
NOT_IMPLEMENTED;
return 0;
}
template <> int Blob<int>::sumsq_data() const {
NOT_IMPLEMENTED;
return 0;
}
template <typename Dtype>
Dtype Blob<Dtype>::sumsq_data() const { //计算data_ L2范式,计算所有元素的平方和
Dtype sumsq;
const Dtype* data;
if (!data_) { return 0; }
switch (data_->head()) {
case SyncedMemory::HEAD_AT_CPU:
data = cpu_data();
sumsq = caffe_cpu_dot(count_, data, data);
break;
case SyncedMemory::HEAD_AT_GPU:
case SyncedMemory::SYNCED:
#ifndef CPU_ONLY
data = gpu_data();
caffe_gpu_dot(count_, data, data, &sumsq);
#else
NO_GPU;
#endif
break;
case SyncedMemory::UNINITIALIZED:
return 0;
default:
LOG(FATAL) << "Unknown SyncedMemory head state: " << data_->head();
}
return sumsq;
}
template <> unsigned int Blob<unsigned int>::sumsq_diff() const {
NOT_IMPLEMENTED;
return 0;
}
template <> int Blob<int>::sumsq_diff() const {
NOT_IMPLEMENTED;
return 0;
}
template <typename Dtype>
Dtype Blob<Dtype>::sumsq_diff() const { //计算diff_ L2范式,计算所有元素的平方和
Dtype sumsq;
const Dtype* diff;
if (!diff_) { return 0; }
switch (diff_->head()) {
case SyncedMemory::HEAD_AT_CPU:
diff = cpu_diff();
sumsq = caffe_cpu_dot(count_, diff, diff);
break;
case SyncedMemory::HEAD_AT_GPU:
case SyncedMemory::SYNCED:
#ifndef CPU_ONLY
diff = gpu_diff();
caffe_gpu_dot(count_, diff, diff, &sumsq);
break;
#else
NO_GPU;
#endif
case SyncedMemory::UNINITIALIZED:
return 0;
default:
LOG(FATAL) << "Unknown SyncedMemory head state: " << data_->head();
}
return sumsq;
}
template <> void Blob<unsigned int>::scale_data(unsigned int scale_factor) {
NOT_IMPLEMENTED;
}
template <> void Blob<int>::scale_data(int scale_factor) {
NOT_IMPLEMENTED;
}
template <typename Dtype>
void Blob<Dtype>::scale_data(Dtype scale_factor) { //对data_乘上某个因子,data乘以sacle_factor
Dtype* data;
if (!data_) { return; }
switch (data_->head()) {
case SyncedMemory::HEAD_AT_CPU:
data = mutable_cpu_data();
caffe_scal(count_, scale_factor, data);
return;
case SyncedMemory::HEAD_AT_GPU:
case SyncedMemory::SYNCED:
#ifndef CPU_ONLY
data = mutable_gpu_data();
caffe_gpu_scal(count_, scale_factor, data);
return;
#else
NO_GPU;
#endif
case SyncedMemory::UNINITIALIZED:
return;
default:
LOG(FATAL) << "Unknown SyncedMemory head state: " << data_->head();
}
}
template <> void Blob<unsigned int>::scale_diff(unsigned int scale_factor) {
NOT_IMPLEMENTED;
}
template <> void Blob<int>::scale_diff(int scale_factor) {
NOT_IMPLEMENTED;
}
template <typename Dtype>
void Blob<Dtype>::scale_diff(Dtype scale_factor) { //对diff_乘上某个因子,diff乘以sacle_factor
Dtype* diff;
if (!diff_) { return; }
switch (diff_->head()) {
case SyncedMemory::HEAD_AT_CPU:
diff = mutable_cpu_diff();
caffe_scal(count_, scale_factor, diff);
return;
case SyncedMemory::HEAD_AT_GPU:
case SyncedMemory::SYNCED:
#ifndef CPU_ONLY
diff = mutable_gpu_diff();
caffe_gpu_scal(count_, scale_factor, diff);
return;
#else
NO_GPU;
#endif
case SyncedMemory::UNINITIALIZED:
return;
default:
LOG(FATAL) << "Unknown SyncedMemory head state: " << diff_->head();
}
}
// 检查当前的blob和已知的other的shape是否相同,相同则返回ture.当然,首先将BlobProto转换为shape类型
template <typename Dtype>
bool Blob<Dtype>::ShapeEquals(const BlobProto& other) {
if (other.has_num() || other.has_channels() ||
other.has_height() || other.has_width()) {
// Using deprecated 4D Blob dimensions --
// shape is (num, channels, height, width).
// Note: we do not use the normal Blob::num(), Blob::channels(), etc.
// methods as these index from the beginning of the blob shape, where legacy
// parameter blobs were indexed from the end of the blob shape (e.g., bias
// Blob shape (1 x 1 x 1 x N), IP layer weight Blob shape (1 x 1 x M x N)).
return shape_.size() <= 4 &&
LegacyShape(-4) == other.num() &&
LegacyShape(-3) == other.channels() &&
LegacyShape(-2) == other.height() &&
LegacyShape(-1) == other.width();
}
vector<int> other_shape(other.shape().dim_size());
for (int i = 0; i < other.shape().dim_size(); ++i) {
other_shape[i] = other.shape().dim(i);
}
return shape_ == other_shape;
}
// 从source拷贝数据, copy_diff来作为标志区分是拷贝data还是diff
template <typename Dtype>
void Blob<Dtype>::CopyFrom(const Blob& source, bool copy_diff, bool reshape) {
if (source.count() != count_ || source.shape() != shape_) {
if (reshape) {
ReshapeLike(source);
} else {
LOG(FATAL) << "Trying to copy blobs of different sizes.";
}
}
switch (Caffe::mode()) {
case Caffe::GPU:
if (copy_diff) {
caffe_copy(count_, source.gpu_diff(),
static_cast<Dtype*>(diff_->mutable_gpu_data()));
} else {
caffe_copy(count_, source.gpu_data(),
static_cast<Dtype*>(data_->mutable_gpu_data()));
}
break;
case Caffe::CPU:
if (copy_diff) {
caffe_copy(count_, source.cpu_diff(),
static_cast<Dtype*>(diff_->mutable_cpu_data()));
} else {
caffe_copy(count_, source.cpu_data(),
static_cast<Dtype*>(data_->mutable_cpu_data()));
}
break;
default:
LOG(FATAL) << "Unknown caffe mode.";
}
}
//从proto读数据进来,反序列化
template <typename Dtype>
void Blob<Dtype>::FromProto(const BlobProto& proto, bool reshape) {
if (reshape) {
vector<int> shape;
if (proto.has_num() || proto.has_channels() ||
proto.has_height() || proto.has_width()) {
// Using deprecated 4D Blob dimensions --
// shape is (num, channels, height, width).
shape.resize(4);
shape[0] = proto.num();
shape[1] = proto.channels();
shape[2] = proto.height();
shape[3] = proto.width();
} else {
shape.resize(proto.shape().dim_size());
for (int i = 0; i < proto.shape().dim_size(); ++i) {
shape[i] = proto.shape().dim(i);
}
}
Reshape(shape);
} else {
CHECK(ShapeEquals(proto)) << "shape mismatch (reshape not set)";
}
// copy data
Dtype* data_vec = mutable_cpu_data();
if (proto.double_data_size() > 0) {
CHECK_EQ(count_, proto.double_data_size());
for (int i = 0; i < count_; ++i) {
data_vec[i] = proto.double_data(i);
}
} else {
CHECK_EQ(count_, proto.data_size());
for (int i = 0; i < count_; ++i) {
data_vec[i] = proto.data(i);
}
}
if (proto.double_diff_size() > 0) {
CHECK_EQ(count_, proto.double_diff_size());
Dtype* diff_vec = mutable_cpu_diff();
for (int i = 0; i < count_; ++i) {
diff_vec[i] = proto.double_diff(i);
}
} else if (proto.diff_size() > 0) {
CHECK_EQ(count_, proto.diff_size());
Dtype* diff_vec = mutable_cpu_diff();
for (int i = 0; i < count_; ++i) {
diff_vec[i] = proto.diff(i);
}
}
}
// 把blob数据保存到proto中
template <>
void Blob<double>::ToProto(BlobProto* proto, bool write_diff) const {
proto->clear_shape();
for (int i = 0; i < shape_.size(); ++i) {
proto->mutable_shape()->add_dim(shape_[i]);
}
proto->clear_double_data();
proto->clear_double_diff();
const double* data_vec = cpu_data(); //定义指针,指针指向数据
for (int i = 0; i < count_; ++i) {
proto->add_double_data(data_vec[i]);
}
if (write_diff) {
const double* diff_vec = cpu_diff();
for (int i = 0; i < count_; ++i) {
proto->add_double_diff(diff_vec[i]);
}
}
}
template <>
void Blob<float>::ToProto(BlobProto* proto, bool write_diff) const {
proto->clear_shape();
for (int i = 0; i < shape_.size(); ++i) {
proto->mutable_shape()->add_dim(shape_[i]);
}
proto->clear_data();
proto->clear_diff();
const float* data_vec = cpu_data();
for (int i = 0; i < count_; ++i) {
proto->add_data(data_vec[i]);
}
if (write_diff) {
const float* diff_vec = cpu_diff();
for (int i = 0; i < count_; ++i) {
proto->add_diff(diff_vec[i]);
}
}
}
INSTANTIATE_CLASS(Blob);
template class Blob<int>;
template class Blob<unsigned int>;
} // namespace caffelayer.hpp和layer.cpp
layer中的主要参数:
LayerParameter layer_param_;//这个是protobuf文件中存储的layer参数vector<share_ptr<Blob<Dtype>>> blobs_;//这个存储的是layer的参数vector<bool> param_propagate_down_;//这个bool表示是否计算各个blob参数的diff,即传播误差
三个主要的接口
virtual void SetUp(const vector<Blob<Dtype>*>& bottom, vector<Blob<Dtype>*>* top);inline Dtype Forward(const vector<Blob<Dtype>*>& bottom, vector<Blob<Dtype>*>* top);inline void Backward(const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down, const <Blob<Dtype>*>* bottom);SetUp函数需要根据实际的参数设置进行实现,对各种类型的参数初始化;Forward和Backwar对应前向计算和反向更新,输入统一是bottom,输出为top,其中Backward里面有个peopagate_down参数,用来表示该Layer是否反向传播参数.Caffe::mode()具体选择使用CPU或GPU操作.
互斥体 mutex
一个互斥体一次只允许一个线程访问共享区.当一个线程想要访问共享区时,首先要做的就是锁住(Lock)互斥体.如果其他的线程已经锁住了互斥体,那么,就必须先等线程解锁了互斥体,这样就保证了同一时刻只有一个线程能访问共享区域.
metux有lock和unlock方法,boost::mutex为独占互斥类.构造与析构时则分别自动调用lock和unlock方法.
基类:layer.hpp
#ifndef CAFFE_LAYER_H_
#define CAFFE_LAYER_H_
#include <algorithm>
#include <string>
#include <vector>
#include "caffe/blob.hpp"
#include "caffe/common.hpp"
#include "caffe/layer_factory.hpp"
#include "caffe/proto/caffe.pb.h"
#include "caffe/util/math_functions.hpp"
namespace boost { class mutex; }
namespace caffe {
/**
* @brief An interface for the units of computation which can be composed into a
* Net.
*
* Layer%s must implement a Forward function, in which they take their input
* (bottom) Blob%s (if any) and compute their output Blob%s (if any).
* They may also implement a Backward function, in which they compute the error
* gradients with respect to their input Blob%s, given the error gradients with
* their output Blob%s.
*/
template <typename Dtype>
class Layer {
public:
/**
* You should not implement your own constructor. Any set up code should go
* to SetUp(), where the dimensions of the bottom blobs are provided to the
* layer.
* 显示的构造函数不需要重写,任何初始工作在SetUp()中完成
*/
// 构造方法只复制层参数说明的值,如果层说明参数中提供了权值和偏置参数,也复制. 继承自Layer类的子类都会显示的调用Layer的构造函数
explicit Layer(const LayerParameter& param)
: layer_param_(param), is_shared_(false) { //layer_param_是protobiuf文件中存储的layer参数
phase_ = param.phase(); //phase定义是训练还是测试,定义在proto中
// 在layer类中被初始化,如果blobs_size() > 0
// 在prototxt文件中一般没有提供blobs参数,所以这段代码一般不执行
if (layer_param_.blobs_size() > 0) {
blobs_.resize(layer_param_.blobs_size());
for (int i = 0; i < layer_param_.blobs_size(); ++i) { //申请空间,然后将传入的layer_param中的blob拷贝
blobs_[i].reset(new Blob<Dtype>());
blobs_[i]->FromProto(layer_param_.blobs(i));
}
}
}
// 虚析构
virtual ~Layer() {}
/**
* @brief Implements common layer setup functionality.实现每个对象的setup函数
* @param bottom the preshaped input blobs.bottom层的输入数据,blob中的存储空间已申请
* @param top
* the allocated but unshaped output blobs, to be shaped by Reshape.层的输出数据,blob对象已构造但是其中的存储空间未申请,具体空间大小需根据bottom blob大小和layer_param_共同决定,具体在Reshape函数现实
* Checks that the number of bottom and top blobs is correct.
* Calls LayerSetUp to do special layer setup for individual layer types,
* followed by Reshape to set up sizes of top blobs and internal buffers.
* Sets up the loss weight multiplier blobs for any non-zero loss weights.
* This method may not be overridden.
* 1. 检查输入输出blob个数是否满足要求,每个层能处理的输入输出数据不一样
* 2. 调用LayerSetUp函数初始化特殊的层,每个Layer子类需重写这个函数完成定制的初始化
* 3. 调用Reshape函数为top blob分配合适大小的存储空间
* 4. 为每个top blob设置损失权重乘子,非LossLayer为的top blob其值为零
*
* 此方法非虚函数,不用重写,模式固定
*/
// layer 初始化设置
void SetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) { //在模型初始化时重置 layers 及其相互之间的连接 ;
InitMutex();
CheckBlobCounts(bottom, top); //检查botton和top的blob是否正确
LayerSetUp(bottom, top); //调用layerSetup对每一具体的层做进一步设置,虚方法
Reshape(bottom, top); //用reshape来设置top blobs和internal buffer
SetLossWeights(top); //设置blob对每个非零的loss和weight
}
/**
* @brief Does layer-specific setup: your layer should implement this function
* as well as Reshape.定制初始化,每个子类layer必须实现此虚函数
*
* @param bottom
* the preshaped input blobs, whose data fields store the input data for
* this layer.输入blob, 数据成员data_和diff_存储了相关数据
*
* @param top
* the allocated but unshaped output blobs.输出blob, blob对象已构造但数据成员的空间尚未申请
*
* This method should do one-time layer specific setup. This includes reading
* and processing relevent parameters from the <code>layer_param_</code>.
* Setting up the shapes of top blobs and internal buffers should be done in
* <code>Reshape</code>, which will be called before the forward pass to
* adjust the top blob sizes.
* 此方法执行一次定制化的层初始化,包括从layer_param_读入并处理相关的层权值和偏置参数,调用Reshape函数申请top blob的存储空间,由派生类重写
*/
virtual void LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {} //需要在派生类中完成
/**
* @brief Whether a layer should be shared by multiple nets during data
* parallelism. By default, all layers except for data layers should
* not be shared. data layers should be shared to ensure each worker
* solver access data sequentially during data parallelism.
* 在数据并行期间时候应该有多个网络共享一个层.默认不应该共享数据层以外的所有图层
*/
virtual inline bool ShareInParallel() const { return false; }
/** @brief Return whether this layer is actually shared by other nets.
* If ShareInParallel() is true and using more than one GPU and the
* net has TRAIN phase, then this function is expected return true.
*/
inline bool IsShared() const { return is_shared_; }
/** @brief Set whether this layer is actually shared by other nets
* If ShareInParallel() is true and using more than one GPU and the
* net has TRAIN phase, then is_shared should be set true.
*/
inline void SetShared(bool is_shared) {
CHECK(ShareInParallel() || !is_shared)
<< type() << "Layer does not support sharing.";
is_shared_ = is_shared;
}
/**
* @brief Adjust the shapes of top blobs and internal buffers to accommodate
* the shapes of the bottom blobs.根据bottom blob的形状和layer_param_计算top blob的形状并为其分配存储空间
*
* @param bottom the input blobs, with the requested input shapes
* @param top the top blobs, which should be reshaped as needed
*
* This method should reshape top blobs as needed according to the shapes
* of the bottom (input) blobs, as well as reshaping any internal buffers
* and making any other necessary adjustments so that the layer can
* accommodate the bottom blobs.
* 每个子类Layer必须重写的Reshape函数,完成top blob形状的设置并为其分配存储空间
*/
//纯虚函数,形参为<Blob<Dtype>*>容器的const引用
virtual void Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) = 0;
/**
* @brief Given the bottom blobs, compute the top blobs and the loss.计算相应的output data blob, loss.
*
* @param bottom
* the input blobs, whose data fields store the input data for this layer
* @param top
* the preshaped output blobs, whose data fields will store this layers'
* outputs
* \return The total loss from the layer.
*
* The Forward wrapper calls the relevant device wrapper function
* (Forward_cpu or Forward_gpu) to compute the top blob values given the
* bottom blobs. If the layer has any non-zero loss_weights, the wrapper
* then computes and returns the loss.
*
* Your layer should implement Forward_cpu and (optionally) Forward_gpu.
* 这两个函数非虚函数,它们内部会调用如下虚函数(Forward_cpu and (optionally) Forward_gpu)完成数据前向传递和误差反向传播,
* 根据执行环境的不同每个子类Layer必须重写CPU和GPU版本
*/
inline Dtype Forward(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top); //从 bottom 层中接收数据,进行计算后将输出送入到 top 层中;
/**
* @brief Given the top blob error gradients, compute the bottom blob error
* gradients.
*
* @param top
* the output blobs, whose diff fields store the gradient of the error
* with respect to themselves
* @param propagate_down
* a vector with equal length to bottom, with each index indicating
* whether to propagate the error gradients down to the bottom blob at
* the corresponding index
* @param bottom
* the input blobs, whose diff fields will store the gradient of the error
* with respect to themselves after Backward is run
*
* The Backward wrapper calls the relevant device wrapper function
* (Backward_cpu or Backward_gpu) to compute the bottom blob diffs given the
* top blob diffs.
*
* Your layer should implement Backward_cpu and (optionally) Backward_gpu.
* 实现反向传播,给定top blob的erroe 果然gradient计算得到bottom的error gradient.输入为 output blobs.
*/
inline void Backward(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom);//给定相对于 top 层输出的梯度,计算其相对于输入的梯度,并传递到 bottom层。一个有参数的 layer 需要计算相对于各个参数的梯度值并存储在内部。
/**
* @brief Returns the vector of learnable parameter blobs.
* 返回可学习的参数blobs
*/
vector<shared_ptr<Blob<Dtype> > >& blobs() {
return blobs_;
}
/**
* @brief Returns the layer parameter.
* 返回层参数
*/
const LayerParameter& layer_param() const { return layer_param_; }
/**
* @brief Writes the layer parameter to a protocol buffer
* 把参数写进protocol buffer
*
*/
virtual void ToProto(LayerParameter* param, bool write_diff = false);
/**
* @brief Returns the scalar loss associated with a top blob at a given index.
*/
// 给定index返回相应的scalar loss
inline Dtype loss(const int top_index) const {
return (loss_.size() > top_index) ? loss_[top_index] : Dtype(0);
}
/**
* @brief Sets the loss associated with a top blob at a given index.
*/
inline void set_loss(const int top_index, const Dtype value) {
if (loss_.size() <= top_index) {
loss_.resize(top_index + 1, Dtype(0));
}
loss_[top_index] = value;
}
/**
* @brief Returns the layer type.
* 返回层类型
*/
virtual inline const char* type() const { return ""; }
//下面几个函数主要设置bottom或者top blob的数量状态,比较简单,通常需要layer类的派生类重写,因为不同层指定的输入输出数量不同
/**
* @brief Returns the exact number of bottom blobs required by the layer,
* or -1 if no exact number is required.
*
* This method should be overridden to return a non-negative value if your
* layer expects some exact number of bottom blobs.
*
*/
virtual inline int ExactNumBottomBlobs() const { return -1; } //返回需要bottom blob的确切数目,默认不需要确切的数目,返回-1
/**
* @brief Returns the minimum number of bottom blobs required by the layer,
* or -1 if no minimum number is required.
*
* This method should be overridden to return a non-negative value if your
* layer expects some minimum number of bottom blobs.
*/
virtual inline int MinBottomBlobs() const { return -1; } //返回需要bottom blob的最小数目,默认不需要最小的数目,返回-1
/**
* @brief Returns the maximum number of bottom blobs required by the layer,
* or -1 if no maximum number is required.
*
* This method should be overridden to return a non-negative value if your
* layer expects some maximum number of bottom blobs.
*/
virtual inline int MaxBottomBlobs() const { return -1; } //返回需要bottom blob的最大数目,默认不需要最大的数目,返回-1
/**
* @brief Returns the exact number of top blobs required by the layer,
* or -1 if no exact number is required.
*
* This method should be overridden to return a non-negative value if your
* layer expects some exact number of top blobs.
*/
virtual inline int ExactNumTopBlobs() const { return -1; }
/**
* @brief Returns the minimum number of top blobs required by the layer,
* or -1 if no minimum number is required.
*
* This method should be overridden to return a non-negative value if your
* layer expects some minimum number of top blobs.
*/
virtual inline int MinTopBlobs() const { return -1; }
/**
* @brief Returns the maximum number of top blobs required by the layer,
* or -1 if no maximum number is required.
*
* This method should be overridden to return a non-negative value if your
* layer expects some maximum number of top blobs.
*/
virtual inline int MaxTopBlobs() const { return -1; }
/**
* @brief Returns true if the layer requires an equal number of bottom and
* top blobs.
*
* This method should be overridden to return true if your layer expects an
* equal number of bottom and top blobs.
*/
virtual inline bool EqualNumBottomTopBlobs() const { return false; } //如果layer需要相同数量的底部和顶部斑点,则返回true
/**
* @brief Return whether "anonymous" top blobs are created automatically
* by the layer.
*
* If this method returns true, Net::Init will create enough "anonymous" top
* blobs to fulfill the requirement specified by ExactNumTopBlobs() or
* MinTopBlobs().
*/
virtual inline bool AutoTopBlobs() const { return false; } //匿名?
/**
* @brief Return whether to allow force_backward for a given bottom blob
* index.
*
* If AllowForceBackward(i) == false, we will ignore the force_backward
* setting and backpropagate to blob i only if it needs gradient information
* (as is done when force_backward == false).
*/
virtual inline bool AllowForceBackward(const int bottom_index) const {
return true;
} //用来设置是否强制梯度返回,因为有些层不需要梯度信息
/**
* @brief Specifies whether the layer should compute gradients w.r.t. a
* parameter at a particular index given by param_id.
*
* You can safely ignore false values and always compute gradients
* for all parameters, but possibly with wasteful computation.
*/
inline bool param_propagate_down(const int param_id) {
return (param_propagate_down_.size() > param_id) ?
param_propagate_down_[param_id] : false;
} //指定图层是否应该计算特定索引处的参数
/**
* @brief Sets whether the layer should compute gradients w.r.t. a
* parameter at a particular index given by param_id.
* 设置是否对某个学习参数blob计算梯度
*/
inline void set_param_propagate_down(const int param_id, const bool value) {
if (param_propagate_down_.size() <= param_id) {
param_propagate_down_.resize(param_id + 1, true);
}
param_propagate_down_[param_id] = value;
}
protected:
/** The protobuf that stores the layer parameters */
//protobuf文件中存储的layer参数,从protocal buffers格式的网络结构说明文件中读取
//protected类成员,构造函数中初始化
LayerParameter layer_param_;
/** The phase: TRAIN or TEST */
//层状态,参与网络的训练还是测试
Phase phase_;
/** The vector that stores the learnable parameters as a set of blobs. */
// 可学习参数层权值和偏置参数,使用向量是因为权值参数和偏置是分开保存在两个blob中的
// 在基类layer中初始化(只是在描述文件定义了的情况下)
vector<shared_ptr<Blob<Dtype> > > blobs_;
/** Vector indicating whether to compute the diff of each param blob. */
// 标志每个可学习参数blob是否需要计算反向传递的梯度值
vector<bool> param_propagate_down_;
/** The vector that indicates whether each top blob has a non-zero weight in
* the objective function.
*/
// 非LossLayer为零,LossLayer中表示每个top blob计算的loss的权重
vector<Dtype> loss_;
/** @brief Using the CPU device, compute the layer output.
* 纯虚函数,子类必须实现,使用cpu经行前向计算
*/
virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) = 0;
/**
* @brief Using the GPU device, compute the layer output.
* Fall back to Forward_cpu() if unavailable.
*/
/* void函数返回void函数
* 为什么这么设置,是为了模板的统一性
* template<class T>
* T default_value()
* {
return T();
* }
* 其中T可以为void
*/
virtual void Forward_gpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
// LOG(WARNING) << "Using CPU code as backup.";
return Forward_cpu(bottom, top);
}
/**
* @brief Using the CPU device, compute the gradients for any parameters and
* for the bottom blobs if propagate_down is true.
* 纯虚函数,派生类必须实现
*/
virtual void Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) = 0;
/**
* @brief Using the GPU device, compute the gradients for any parameters and
* for the bottom blobs if propagate_down is true.
* Fall back to Backward_cpu() if unavailable.
*/
virtual void Backward_gpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
// LOG(WARNING) << "Using CPU code as backup.";
Backward_cpu(top, propagate_down, bottom);
}
/**
* Called by the parent Layer's SetUp to check that the number of bottom
* and top Blobs provided as input match the expected numbers specified by
* the {ExactNum,Min,Max}{Bottom,Top}Blobs() functions.
*/
// 检查输出输出的blobs的个数是否在给定范围内
virtual void CheckBlobCounts(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
if (ExactNumBottomBlobs() >= 0) {
CHECK_EQ(ExactNumBottomBlobs(), bottom.size())
<< type() << " Layer takes " << ExactNumBottomBlobs()
<< " bottom blob(s) as input.";
}
if (MinBottomBlobs() >= 0) {
CHECK_LE(MinBottomBlobs(), bottom.size())
<< type() << " Layer takes at least " << MinBottomBlobs()
<< " bottom blob(s) as input.";
}
if (MaxBottomBlobs() >= 0) {
CHECK_GE(MaxBottomBlobs(), bottom.size())
<< type() << " Layer takes at most " << MaxBottomBlobs()
<< " bottom blob(s) as input.";
}
if (ExactNumTopBlobs() >= 0) {
CHECK_EQ(ExactNumTopBlobs(), top.size())
<< type() << " Layer produces " << ExactNumTopBlobs()
<< " top blob(s) as output.";
}
if (MinTopBlobs() >= 0) {
CHECK_LE(MinTopBlobs(), top.size())
<< type() << " Layer produces at least " << MinTopBlobs()
<< " top blob(s) as output.";
}
if (MaxTopBlobs() >= 0) {
CHECK_GE(MaxTopBlobs(), top.size())
<< type() << " Layer produces at most " << MaxTopBlobs()
<< " top blob(s) as output.";
}
if (EqualNumBottomTopBlobs()) {
CHECK_EQ(bottom.size(), top.size())
<< type() << " Layer produces one top blob as output for each "
<< "bottom blob input.";
}
}
/**
* Called by SetUp to initialize the weights associated with any top blobs in
* the loss function. Store non-zero loss weights in the diff blob.
*/
inline void SetLossWeights(const vector<Blob<Dtype>*>& top) { //设置blob对每个非零的loss和weight,初始化top的weights,并且存储非零的loss_weights在diff中
const int num_loss_weights = layer_param_.loss_weight_size();
if (num_loss_weights) {
CHECK_EQ(top.size(), num_loss_weights) << "loss_weight must be "
"unspecified or specified once per top blob.";
for (int top_id = 0; top_id < top.size(); ++top_id) {
const Dtype loss_weight = layer_param_.loss_weight(top_id);
if (loss_weight == Dtype(0)) { continue; }
this->set_loss(top_id, loss_weight); //设置top_loss值
const int count = top[top_id]->count();
Dtype* loss_multiplier = top[top_id]->mutable_cpu_diff();
caffe_set(count, loss_weight, loss_multiplier); //对cpu_diff()进行初始化
}
}
}
private:
/** Whether this layer is actually shared by other nets*/
bool is_shared_;
/** The mutex for sequential forward if this layer is shared
* 类型为 boost::mutex 的 mutex 全局互斥对象
*/
// 若该layer被shared,则需要这个mutex序列保持forward过程的正常运行
shared_ptr<boost::mutex> forward_mutex_;
/** Initialize forward_mutex_ */
void InitMutex();
/** Lock forward_mutex_ if this layer is shared */
void Lock();
/** Unlock forward_mutex_ if this layer is shared */
void Unlock();
DISABLE_COPY_AND_ASSIGN(Layer);
}; // class Layer
// Forward and backward wrappers. You should implement the cpu and
// gpu specific implementations instead, and should not change these
// functions.
// 前向传播和反向传播接口。 每个Layer的派生类都应该实现Forward_cpu()
template <typename Dtype>
inline Dtype Layer<Dtype>::Forward(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
// Lock during forward to ensure sequential forward
Lock();
Dtype loss = 0;
Reshape(bottom, top);
switch (Caffe::mode()) {
case Caffe::CPU:
Forward_cpu(bottom, top);
// 计算loss
if (!this->loss(top_id)) { continue; }
const int count = top[top_id]->count();
const Dtype* data = top[top_id]->cpu_data();
const Dtype* loss_weights = top[top_id]->cpu_diff();
loss += caffe_cpu_dot(count, data, loss_weights);
} for (int top_id = 0; top_id < top.size(); ++top_id) {
break;
case Caffe::GPU:
Forward_gpu(bottom, top);
#ifndef CPU_ONLY
for (int top_id = 0; top_id < top.size(); ++top_id) {
if (!this->loss(top_id)) { continue; }
const int count = top[top_id]->count();
const Dtype* data = top[top_id]->gpu_data();
const Dtype* loss_weights = top[top_id]->gpu_diff();
Dtype blob_loss = 0;
caffe_gpu_dot(count, data, loss_weights, &blob_loss);
loss += blob_loss;
}
#endif
break;
default:
LOG(FATAL) << "Unknown caffe mode.";
}
Unlock();
return loss;
}
template <typename Dtype>
inline void Layer<Dtype>::Backward(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
switch (Caffe::mode()) {
case Caffe::CPU:
Backward_cpu(top, propagate_down, bottom);
break;
case Caffe::GPU:
Backward_gpu(top, propagate_down, bottom);
break;
default:
LOG(FATAL) << "Unknown caffe mode.";
}
}
// Serialize LayerParameter to protocol buffer
//Layer的序列化函数,将layer的层说明参数layer_param_,
//层权值和偏置参数blobs_复制到LayerParameter对象,便于写到磁盘
template <typename Dtype>
void Layer<Dtype>::ToProto(LayerParameter* param, bool write_diff) {
param->Clear();
param->CopyFrom(layer_param_);
param->clear_blobs();
// 复制层权值和偏置参数blobs_
for (int i = 0; i < blobs_.size(); ++i) {
blobs_[i]->ToProto(param->add_blobs(), write_diff);
}
}
} // namespace caffe
#endif // CAFFE_LAYER_H_Data_layer 派生类
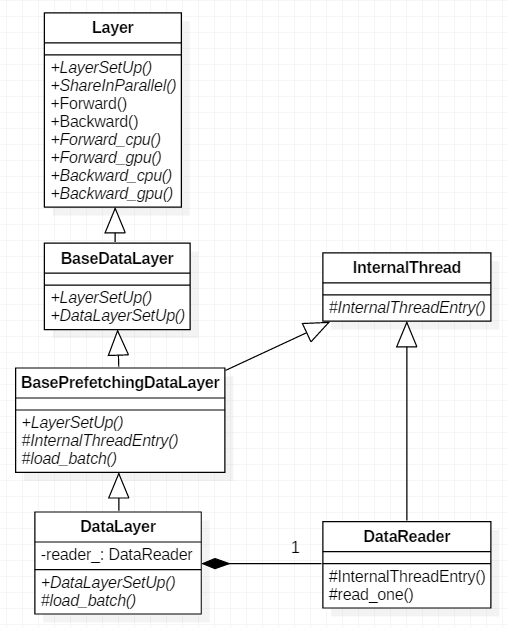
- BaseDataLayer:数据层的基类,继承自通用的类Layer
- Batch:实际上就是一个data_和label_类标
- BasePrefetchingDataLayer:是预取层的基类,继承自BaseDataLayer和InternalThread,包含能够读取一批数据的能力
- DataLayer:继承BasePrefetchingDataLayer基类,使用
DataReader来进行数据共享,从而实现并行化 - DummyDataLayer:该类继承Layer基类,通过Filler产生数据
- HDF5DataLayer:从HDF5中读取,继承自Layer
- ImageDataLayer:从图像文件中读取数据,继承自BaseDataLayer
Data_transformer.hpp
定义了类DataTransformer,这个类执行一些预处理操作,比如缩放crop_size\镜像mirror\减去均值mean_value mean_file\尺度变换scale.里面有5个常用的transform函数,其中所有函数的第二个部分是想用的,都是一个目标blob.而输入根据输入的情况有所选择,可以是blob,耶可以是opencv的mat结构,或者proto中定义的datum结构.
void Transform(const Datum& datum, Blob<Dtype>* transformed_blob);
void Transform(const vector<Datum> & datum_vector, Blob<Dtype>* transformed_blob);
void Transform(const vector<cv::Mat> & mat_vector, Blob<Dtype>* transformed_blob);
void Transform(const cv::Mat& cv_img, Blob<Dtype>* transformed_blob);
void Transform(Blob<Dtype>* input_blob, Blob<Dtype>* transformed_blob);proto文件中,对应该类构造函数需要传入的一些变形参数.
message TransformationParameter {
optional float scale = 1 [default = 1];
optional bool mirror = 2 [default = false];
optional uint32 crop_size = 3 [default = 0];
optional string mean_file = 4;
repeated float mean_value = 5;
optional bool force_color = 6 [default = false];
optional bool force_gray = 7 [default = false];
} void Transform(Blob<Dtype>* input_blob, Blob<Dtype>* transformed_blob);其中一个核心函数,transfrom.
emplate<typename Dtype>
void DataTransformer<Dtype>::Transform(Blob<Dtype>* input_blob,
Blob<Dtype>* transformed_blob) {
const int crop_size = param_.crop_size(); //获得crop_size
const int input_num = input_blob->num(); //获取输入数据的四维信息
const int input_channels = input_blob->channels();
const int input_height = input_blob->height();
const int input_width = input_blob->width();
if (transformed_blob->count() == 0) {
// Initialize transformed_blob with the right shape.使用正确的形状初始化blob
if (crop_size) {
transformed_blob->Reshape(input_num, input_channels,
crop_size, crop_size);
} else {
transformed_blob->Reshape(input_num, input_channels,
input_height, input_width);
}
}
const int num = transformed_blob->num();
const int channels = transformed_blob->channels();
const int height = transformed_blob->height();
const int width = transformed_blob->width();
const int size = transformed_blob->count();
CHECK_LE(input_num, num);
CHECK_EQ(input_channels, channels);
CHECK_GE(input_height, height);
CHECK_GE(input_width, width);
const Dtype scale = param_.scale();
const bool do_mirror = param_.mirror() && Rand(2);
const bool has_mean_file = param_.has_mean_file();
const bool has_mean_values = mean_values_.size() > 0;
int h_off = 0;
int w_off = 0;
if (crop_size) {
CHECK_EQ(crop_size, height);
CHECK_EQ(crop_size, width);
// We only do random crop when we do training.
if (phase_ == TRAIN) {
h_off = Rand(input_height - crop_size + 1);
w_off = Rand(input_width - crop_size + 1);
} else {
h_off = (input_height - crop_size) / 2;
w_off = (input_width - crop_size) / 2;
}
} else {
CHECK_EQ(input_height, height);
CHECK_EQ(input_width, width);
}
// 如果我们输入的图片尺寸大于crop_size,那么图片会被裁剪。当`phase`模式为`TRAIN`时,裁剪是随机进行裁剪,而当为`TEST`模式时,其裁剪方式则只是裁剪图像的中间区域。
Dtype* input_data = input_blob->mutable_cpu_data();
if (has_mean_file) {
CHECK_EQ(input_channels, data_mean_.channels());
CHECK_EQ(input_height, data_mean_.height());
CHECK_EQ(input_width, data_mean_.width());
for (int n = 0; n < input_num; ++n) {
int offset = input_blob->offset(n);
caffe_sub(data_mean_.count(), input_data + offset,
data_mean_.cpu_data(), input_data + offset);
}
}
// 如果定义了mean_file,则在输入数据blob中减去对应的均值
if (has_mean_values) {
CHECK(mean_values_.size() == 1 || mean_values_.size() == input_channels) <<
"Specify either 1 mean_value or as many as channels: " << input_channels;
if (mean_values_.size() == 1) {
caffe_add_scalar(input_blob->count(), -(mean_values_[0]), input_data);
} else {
for (int n = 0; n < input_num; ++n) {
for (int c = 0; c < input_channels; ++c) {
int offset = input_blob->offset(n, c);
caffe_add_scalar(input_height * input_width, -(mean_values_[c]),
input_data + offset);
}
}
}
}
// 如果定义了mean_value,则在输入数据blob中减去对应的均值,对应于三个通道RGB
Dtype* transformed_data = transformed_blob->mutable_cpu_data();
for (int n = 0; n < input_num; ++n) {
int top_index_n = n * channels;
int data_index_n = n * channels;
for (int c = 0; c < channels; ++c) {
int top_index_c = (top_index_n + c) * height;
int data_index_c = (data_index_n + c) * input_height + h_off;
for (int h = 0; h < height; ++h) {
int top_index_h = (top_index_c + h) * width;
int data_index_h = (data_index_c + h) * input_width + w_off;
if (do_mirror) {
int top_index_w = top_index_h + width - 1;
for (int w = 0; w < width; ++w) {
transformed_data[top_index_w-w] = input_data[data_index_h + w];
}
} else {
for (int w = 0; w < width; ++w) {
transformed_data[top_index_h + w] = input_data[data_index_h + w];
}
}
}
}
}
// 判断是否做镜像变换,得到最终的transformed_data.由于存储的地址,因此不需要返回数据.
if (scale != Dtype(1)) {
DLOG(INFO) << "Scale: " << scale;
caffe_scal(size, scale, transformed_data);
}
}
// 判断是否做尺度变换scale,得到最终的transformed_datadata_reader.hpp和data_reader.cpp
仅仅把数据从DB中读取出来,这部分会给每一个读入的数据源创建一个独立的线程,专门负责这个数据源的读入工作.DataReader线程将读入的数据放入full中,而下面的BasePrefetchingDataLayer的线程将full中的内容取走.Caffe使用BlockingQueue作为生产者和消费者之间同步的结构.
每一次DataReader将free中已经被消费过的对象取出,填上新的数据,然后将其塞入full中.每一次BlockingQueue将full中的对象取出并消费,然后将其塞入free中.
data_reader.hpp
class::Body
#ifndef CAFFE_DATA_READER_HPP_
#define CAFFE_DATA_READER_HPP_
#include <map>
#include <string>
#include <vector>
#include "caffe/common.hpp"
#include "caffe/internal_thread.hpp"
#include "caffe/util/blocking_queue.hpp"
#include "caffe/util/db.hpp"
namespace caffe {
/**
* @brief Reads data from a source to queues available to data layers.
* A single reading thread is created per source, even if multiple solvers
* are running in parallel, e.g. for multi-GPU training. This makes sure
* databases are read sequentially, and that each solver accesses a different
* subset of the database. Data is distributed to solvers in a round-robin
* way to keep parallel training deterministic.
* 从共享的资源读取数据然后排队输入到数据层,每个资源创建单个线程,即便是使用多个 GPU
* 在并行任务中求解。这就保证对于频繁读取数据库,并且每个求解的线程使用的子数据是不同。
* 数据成功设计就是这样使在求解时数据保持一种循环地并行训练。
*/
class DataReader {
public:
explicit DataReader(const LayerParameter& param); //构造函数
~DataReader(); //析构函数
inline BlockingQueue<Datum*>& free() const {
return queue_pair_->free_;
}
inline BlockingQueue<Datum*>& full() const {
return queue_pair_->full_;
}
protected:
// Queue pairs are shared between a body and its readers
class QueuePair { //线程处理
public:
explicit QueuePair(int size);
~QueuePair();
BlockingQueue<Datum*> free_; //定义阻塞队列free_
BlockingQueue<Datum*> full_; //定义阻塞队列full_
DISABLE_COPY_AND_ASSIGN(QueuePair);
};
// A single body is created per source
class Body : public InternalThread { //继承InternalThread类
public:
explicit Body(const LayerParameter& param); //构造函数
virtual ~Body(); //析构函数
protected:
void InternalThreadEntry(); //重写了InternalThread 内部的 InternalThreadEntry 函数,此外还添加了 read_one 函数
void read_one(db::Cursor* cursor, QueuePair* qp);
const LayerParameter param_;
BlockingQueue<shared_ptr<QueuePair> > new_queue_pairs_;
friend class DataReader; //DataReader的友元
DISABLE_COPY_AND_ASSIGN(Body);
};
// A source is uniquely identified by its layer name + path, in case
// the same database is read from two different locations in the net.
// 数据的唯一标识:层名称+路径,防止不同位置读取相同的数据库
static inline string source_key(const LayerParameter& param) {
return param.name() + ":" + param.data_param().source(); //data_patam()参数.source()代表源地址
}
const shared_ptr<QueuePair> queue_pair_;
shared_ptr<Body> body_;
static map<const string, boost::weak_ptr<DataReader::Body> > bodies_;
DISABLE_COPY_AND_ASSIGN(DataReader);
};
} // namespace caffe
#endif // CAFFE_DATA_READER_HPP_data_reader.cpp
#include <boost/thread.hpp>
#include <map>
#include <string>
#include <vector>
#include "caffe/common.hpp"
#include "caffe/data_reader.hpp"
#include "caffe/layers/data_layer.hpp"
#include "caffe/proto/caffe.pb.h"
namespace caffe {
using boost::weak_ptr; //类似于智能指针,可以观测资源的使用情况
map<const string, weak_ptr<DataReader::Body> > DataReader::bodies_;
static boost::mutex bodies_mutex_; //互斥器
DataReader::DataReader(const LayerParameter& param)
: queue_pair_(new QueuePair( //构造函数
param.data_param().prefetch() * param.data_param().batch_size())) {
// Get or create a body
boost::mutex::scoped_lock lock(bodies_mutex_); //互斥器上锁
string key = source_key(param); //返回名称+路径地址
weak_ptr<Body>& weak = bodies_[key];
body_ = weak.lock();
if (!body_) {
body_.reset(new Body(param));
bodies_[key] = weak_ptr<Body>(body_);
}
body_->new_queue_pairs_.push(queue_pair_); //存储进body_里面
}
DataReader::~DataReader() { //析构函数
string key = source_key(body_->param_);
body_.reset();
boost::mutex::scoped_lock lock(bodies_mutex_);
if (bodies_[key].expired()) { //weak_ptr::expired():查询被观测资源是否已经不服存在
bodies_.erase(key); //删除函数,删除key
}
}
//
DataReader::QueuePair::QueuePair(int size) { //根据给定的size初始化的若干个Datum的实例到free里面
// Initialize the free queue with requested number of datums
for (int i = 0; i < size; ++i) {
free_.push(new Datum());
}
}
DataReader::QueuePair::~QueuePair() { //析构函数,将full_和free_队列中的Datum对象全部删除
Datum* datum;
while (free_.try_pop(&datum)) {
delete datum;
}
while (full_.try_pop(&datum)) {
delete datum;
}
}
//
DataReader::Body::Body(const LayerParameter& param)
: param_(param),
new_queue_pairs_() { //构造函数,给定网络的参数,然后开始启动内部线程
StartInternalThread(); //调用此函数来初始化运行环境以及新建线程去执行InternalThreadEntry的内容
}
DataReader::Body::~Body() { //停止线程
StopInternalThread();
}
void DataReader::Body::InternalThreadEntry() { //自己需要执行的函数
shared_ptr<db::DB> db(db::GetDB(param_.data_param().backend())); // lmdb类型数据源的DB指针
db->Open(param_.data_param().source(), db::READ); // 从网络参数中的给定DB位置打开
DB
shared_ptr<db::Cursor> cursor(db->NewCursor()); //新建游标指针
vector<shared_ptr<QueuePair> > qps; //新建QueuePair指针容器,里面包含了free_和Full_两个阻塞队列
try {
int solver_count = param_.phase() == TRAIN ? Caffe::solver_count() : 1; // 设置solver_count()
// To ensure deterministic runs, only start running once all solvers
// are ready. But solvers need to peek on one item during initialization,
// so read one item, then wait for the next solver.
for (int i = 0; i < solver_count; ++i) {
shared_ptr<QueuePair> qp(new_queue_pairs_.pop());
read_one(cursor.get(), qp.get());
qps.push_back(qp);
}
// Main loop
while (!must_stop()) {
for (int i = 0; i < solver_count; ++i) {
read_one(cursor.get(), qps[i].get());
}
// Check no additional readers have been created. This can happen if
// more than one net is trained at a time per process, whether single
// or multi solver. It might also happen if two data layers have same
// name and same source.
CHECK_EQ(new_queue_pairs_.size(), 0);
}
} catch (boost::thread_interrupted&) {
// Interrupted exception is expected on shutdown
}
}
void DataReader::Body::read_one(db::Cursor* cursor, QueuePair* qp) { //从数据库中获取一个数据
Datum* datum = qp->free_.pop();
// TODO deserialize in-place instead of copy?
datum->ParseFromString(cursor->value());
qp->full_.push(datum);
// go to the next iter
cursor->Next();
if (!cursor->valid()) {
DLOG(INFO) << "Restarting data prefetching from start.";
cursor->SeekToFirst();
}
}
} // namespace caffebase_data_layer.hpp和base_data_layer.cpp
base_data_layer.hpp
主要包含两个类:BaseDataLayer和BasePrefetchingDataLayer类.BaseDataLayer类继承Layer类;BasePrefetchingDataLayer继承BaseDataLayer类和InternalThread类
#ifndef CAFFE_DATA_LAYERS_HPP_
#define CAFFE_DATA_LAYERS_HPP_
#include <vector>
#include "caffe/blob.hpp"
#include "caffe/data_transformer.hpp"
#include "caffe/internal_thread.hpp"
#include "caffe/layer.hpp"
#include "caffe/proto/caffe.pb.h"
#include "caffe/util/blocking_queue.hpp"
namespace caffe {
/**
* @brief Provides base for data layers that feed blobs to the Net.
*
* TODO(dox): thorough documentation for Forward and proto params.
*/
template <typename Dtype>
class BaseDataLayer : public Layer<Dtype> { // Layer的派生类
public:
explicit BaseDataLayer(const LayerParameter& param); // 构造函数
// LayerSetUp: implements common data layer setup functionality, and calls
// DataLayerSetUp to do special data layer setup for individual layer types.
// This method may not be overridden except by the BasePrefetchingDataLayer.
virtual void LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top); // 实现一般数据层构建,并调用DataLayerSetUp函数,该函数在layer.hpp中定义
// Data layers should be shared by multiple solvers in parallel
virtual inline bool ShareInParallel() const { return true; } //数据层可在并行时共享
virtual void DataLayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {} // 该函数为虚函数,待子类重载
// Data layers have no bottoms, so reshaping is trivial.
virtual void Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {} // 数据层不需要bottom层,因此Reshanpe为空
virtual void Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) {} //反向传播,空函数
virtual void Backward_gpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) {}
protected:
TransformationParameter transform_param_;
shared_ptr<DataTransformer<Dtype> > data_transformer_;
bool output_labels_; //是否包含输出标签
};
template <typename Dtype>
class Batch {
public:
Blob<Dtype> data_, label_;
};
template <typename Dtype>
class BasePrefetchingDataLayer :
public BaseDataLayer<Dtype>, public InternalThread { //BasePrefetchingDataLayer类,不仅继承了BaseDataLayer类和InternalThread类.
public:
explicit BasePrefetchingDataLayer(const LayerParameter& param); //构造函数
// LayerSetUp: implements common data layer setup functionality, and calls
// DataLayerSetUp to do special data layer setup for individual layer types.
// This method may not be overridden.
void LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top); //实现一般数据层构建,并调用DataLayerSetUp函数,该函数在layer.hpp中定义
virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Forward_gpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top); //正向传导函数
// Prefetches batches (asynchronously if to GPU memory)
static const int PREFETCH_COUNT = 3; //预取数据块的大小,batch为3
protected:
virtual void InternalThreadEntry(); //线程函数,虚函数重载
virtual void load_batch(Batch<Dtype>* batch) = 0; //加载batch,纯虚函数,由子类DataLayer实现
Batch<Dtype> prefetch_[PREFETCH_COUNT];
BlockingQueue<Batch<Dtype>*> prefetch_free_;
BlockingQueue<Batch<Dtype>*> prefetch_full_;
Blob<Dtype> transformed_data_;
};
} // namespace caffe
#endif // CAFFE_DATA_LAYERS_HPP_base_data_layer.cpp
#include <boost/thread.hpp>
#include <vector>
#include "caffe/blob.hpp"
#include "caffe/data_transformer.hpp"
#include "caffe/internal_thread.hpp"
#include "caffe/layer.hpp"
#include "caffe/layers/base_data_layer.hpp"
#include "caffe/proto/caffe.pb.h"
#include "caffe/util/blocking_queue.hpp"
namespace caffe {
template <typename Dtype>
BaseDataLayer<Dtype>::BaseDataLayer(const LayerParameter& param)
: Layer<Dtype>(param),
transform_param_(param.transform_param()) {
} //构造函数
template <typename Dtype>
void BaseDataLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
if (top.size() == 1) {
output_labels_ = false;
} else {
output_labels_ = true;
} //如果top层size大于1,则包含输出标签lable
data_transformer_.reset(
new DataTransformer<Dtype>(transform_param_, this->phase_));
data_transformer_->InitRand(); //满足相关条件,则初始化随机数生成器
// The subclasses should setup the size of bottom and top
DataLayerSetUp(bottom, top); // 调用构建虚函数
}
template <typename Dtype>
BasePrefetchingDataLayer<Dtype>::BasePrefetchingDataLayer(
const LayerParameter& param)
: BaseDataLayer<Dtype>(param),
prefetch_free_(), prefetch_full_() { //构造函数
for (int i = 0; i < PREFETCH_COUNT; ++i) {
prefetch_free_.push(&prefetch_[i]);
}
}
template <typename Dtype>
void BasePrefetchingDataLayer<Dtype>::LayerSetUp(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
BaseDataLayer<Dtype>::LayerSetUp(bottom, top); //先调用BaseDataLayer的LayerSetUp函数
// Before starting the prefetch thread, we make cpu_data and gpu_data
// calls so that the prefetch thread does not accidentally make simultaneous
// cudaMalloc calls when the main thread is running. In some GPUs this
// seems to cause failures if we do not so.
// 在开始线程之前,先分配内存&显存,cpu_data和gpu_data,防止在某些gpu上报错
for (int i = 0; i < PREFETCH_COUNT; ++i) {
prefetch_[i].data_.mutable_cpu_data();
if (this->output_labels_) { //output_labels_标志位,表示有无标签
prefetch_[i].label_.mutable_cpu_data();
}
}
#ifndef CPU_ONLY
if (Caffe::mode() == Caffe::GPU) {
for (int i = 0; i < PREFETCH_COUNT; ++i) {
prefetch_[i].data_.mutable_gpu_data();
if (this->output_labels_) {
prefetch_[i].label_.mutable_gpu_data();
}
}
}
#endif
DLOG(INFO) << "Initializing prefetch";
this->data_transformer_->InitRand(); //初始化随机数生成器
StartInternalThread(); //开始线程
DLOG(INFO) << "Prefetch initialized.";
}
template <typename Dtype>
void BasePrefetchingDataLayer<Dtype>::InternalThreadEntry() { //线程函数,由StartInternalThread()调用
#ifndef CPU_ONLY
cudaStream_t stream; //在GPU上启用stream异步加载
if (Caffe::mode() == Caffe::GPU) {
CUDA_CHECK(cudaStreamCreateWithFlags(&stream, cudaStreamNonBlocking));
}
#endif
try {
while (!must_stop()) {
Batch<Dtype>* batch = prefetch_free_.pop();
load_batch(batch); //加载batch,虚函数由子类DataLayer定义
#ifndef CPU_ONLY
if (Caffe::mode() == Caffe::GPU) {
batch->data_.data().get()->async_gpu_push(stream);
CUDA_CHECK(cudaStreamSynchronize(stream));
}
#endif
prefetch_full_.push(batch);
}
} catch (boost::thread_interrupted&) {
// Interrupted exception is expected on shutdown
}
#ifndef CPU_ONLY
if (Caffe::mode() == Caffe::GPU) {
CUDA_CHECK(cudaStreamDestroy(stream));
}
#endif
}
template <typename Dtype>
void BasePrefetchingDataLayer<Dtype>::Forward_cpu( //CPU正向传导
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
Batch<Dtype>* batch = prefetch_full_.pop("Data layer prefetch queue empty");
// Reshape to loaded data.
top[0]->ReshapeLike(batch->data_); //将top[0]Reshape成与batch.data数据相同维度
// Copy the data
caffe_copy(batch->data_.count(), batch->data_.cpu_data(),
top[0]->mutable_cpu_data()); //将batch数据拷贝至top层blob[0]
DLOG(INFO) << "Prefetch copied";
if (this->output_labels_) { //如果包含标签
// Reshape to loaded labels.
top[1]->ReshapeLike(batch->label_); //top[1]Reshape成与batch.labal数据相同维度
// Copy the labels.
caffe_copy(batch->label_.count(), batch->label_.cpu_data(),
top[1]->mutable_cpu_data()); //将batch数据拷贝至top层blob[1]
}
prefetch_free_.push(batch);
}
#ifdef CPU_ONLY
STUB_GPU_FORWARD(BasePrefetchingDataLayer, Forward); //如果CPU_ONLY模式则禁止Forward_gpu和Backward_gpu函数
#endif
INSTANTIATE_CLASS(BaseDataLayer);
INSTANTIATE_CLASS(BasePrefetchingDataLayer);
} // namespace caffedata_layer.hpp和data_layer.cpp
data_layer.hpp
#ifndef CAFFE_DATA_LAYER_HPP_
#define CAFFE_DATA_LAYER_HPP_
#include <vector>
#include "caffe/blob.hpp"
#include "caffe/data_reader.hpp"
#include "caffe/data_transformer.hpp"
#include "caffe/internal_thread.hpp"
#include "caffe/layer.hpp"
#include "caffe/layers/base_data_layer.hpp"
#include "caffe/proto/caffe.pb.h"
#include "caffe/util/db.hpp"
namespace caffe {
/*
原始数据的输入层,处于整个网络的最底层,它可以
从数据库leveldb、 lmdb中读取数据,也可以直接从内存中读取,还
可以从hdf5,甚至是原始的图像读入数据。 作为网络的最底层,主
要实现数据格式的转换
*/
template <typename Dtype>
class DataLayer : public BasePrefetchingDataLayer<Dtype> {
public:
explicit DataLayer(const LayerParameter& param);
virtual ~DataLayer();
virtual void DataLayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
// DataLayer uses DataReader instead for sharing for parallelism
virtual inline bool ShareInParallel() const { return false; }
virtual inline const char* type() const { return "Data"; }
virtual inline int ExactNumBottomBlobs() const { return 0; }
virtual inline int MinTopBlobs() const { return 1; }
virtual inline int MaxTopBlobs() const { return 2; }
protected:
virtual void load_batch(Batch<Dtype>* batch);
DataReader reader_;
};
} // namespace caffe
#endif // CAFFE_DATA_LAYER_HPP_data_layer.cpp
函数DataLayerSetUp设置top[0]和top[1]两个blob的大小,即Reshape
#ifdef USE_OPENCV
#include <opencv2/core/core.hpp>
#endif // USE_OPENCV
#include <stdint.h>
#include <vector>
#include "caffe/data_transformer.hpp"
#include "caffe/layers/data_layer.hpp"
#include "caffe/util/benchmark.hpp"
namespace caffe {
template <typename Dtype>
DataLayer<Dtype>::DataLayer(const LayerParameter& param)
: BasePrefetchingDataLayer<Dtype>(param),
reader_(param) { //构造函数,初始化层参数
}
template <typename Dtype>
DataLayer<Dtype>::~DataLayer() { //析构函数停止内部线程
this->StopInternalThread();
}
template <typename Dtype> //数据层初始化
void DataLayer<Dtype>::DataLayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const int batch_size = this->layer_param_.data_param().batch_size(); // 从层参数中读取batch_size
// Read a data point, and use it to initialize the top blob.
Datum& datum = *(reader_.full().peek()); // 从reader_中获取一个数据
// Use data_transformer to infer the expected blob shape from datum.
vector<int> top_shape = this->data_transformer_->InferBlobShape(datum); // 用数据来推断blob的形状存放到top_shape
this->transformed_data_.Reshape(top_shape); //根据top_shape来Reshape尺寸
// Reshape top[0] and prefetch_data according to the batch_size.
top_shape[0] = batch_size; //(batch_size/channel/height/width)
top[0]->Reshape(top_shape); // 根据形状设置top[0]的形状
for (int i = 0; i < this->PREFETCH_COUNT; ++i) {
this->prefetch_[i].data_.Reshape(top_shape); //设置预取数据的形状
}
LOG(INFO) << "output data size: " << top[0]->num() << ","
<< top[0]->channels() << "," << top[0]->height() << ","
<< top[0]->width();
// label, 如果输出类标的话则把top[1]的形状也弄一下
if (this->output_labels_) {
vector<int> label_shape(1, batch_size);
top[1]->Reshape(label_shape);
for (int i = 0; i < this->PREFETCH_COUNT; ++i) {
this->prefetch_[i].label_.Reshape(label_shape); //设置预取label的形状
}
}
}
// This function is called on prefetch thread 这个函数在自己定义的线程内部执行程序
template<typename Dtype>
void DataLayer<Dtype>::load_batch(Batch<Dtype>* batch) {
CPUTimer batch_timer;
batch_timer.Start();
double read_time = 0;
double trans_time = 0;
CPUTimer timer;
CHECK(batch->data_.count());
CHECK(this->transformed_data_.count());
// Reshape according to the first datum of each batch
// on single input batches allows for inputs of varying dimension.
// 每个batch的数据的维度是可以变换的
const int batch_size = this->layer_param_.data_param().batch_size(); //获取batch_size
Datum& datum = *(reader_.full().peek()); //使用第一个数据推断blob的形状
// Use data_transformer to infer the expected blob shape from datum.
vector<int> top_shape = this->data_transformer_->InferBlobShape(datum);
this->transformed_data_.Reshape(top_shape);
// Reshape batch according to the batch_size.
top_shape[0] = batch_size;
batch->data_.Reshape(top_shape);
Dtype* top_data = batch->data_.mutable_cpu_data(); //top_data存储数据
Dtype* top_label = NULL; // suppress warnings about uninitialized variables
if (this->output_labels_) {
top_label = batch->label_.mutable_cpu_data(); //top_label存储标签
}
for (int item_id = 0; item_id < batch_size; ++item_id) { //对数据进行处理
timer.Start();
// get a datum
Datum& datum = *(reader_.full().pop("Waiting for data")); // 从full_中获得datum,相当于取出数据
read_time += timer.MicroSeconds(); //记录读取数据的时间
timer.Start();
// Apply data transformations (mirror, scale, crop...)
int offset = batch->data_.offset(item_id);
this->transformed_data_.set_cpu_data(top_data + offset);
this->data_transformer_->Transform(datum, &(this->transformed_data_)); // 对数据进行预处理
// Copy label.
if (this->output_labels_) { //复制类标,存每一个batch的label
top_label[item_id] = datum.label();
}
trans_time += timer.MicroSeconds(); //记录数据传输的时间
reader_.free().push(const_cast<Datum*>(&datum)); //将数据指针压到free队列
}
timer.Stop();
batch_timer.Stop();
DLOG(INFO) << "Prefetch batch: " << batch_timer.MilliSeconds() << " ms.";
DLOG(INFO) << " Read time: " << read_time / 1000 << " ms.";
DLOG(INFO) << "Transform time: " << trans_time / 1000 << " ms.";
}
INSTANTIATE_CLASS(DataLayer);
REGISTER_LAYER_CLASS(Data);
} // namespace caffeConv_Layer 派生类

base_conv_layer.hpp和base_conv_layer.cpp
im2col,分析caffe卷积操作的底层实现
在caffe里面,卷积操作做了优化,变成了一个矩阵相乘的操作.
im2col_cpu将c个通道的卷积层输入图像转化为c个通道的矩阵,矩阵的行值为卷积核高 * 卷积核宽,也就是说,矩阵的单列表征了卷积核操作一次处理的小窗口图像信息;而矩阵的列值为卷积层输出单通道图像高 * 卷积层输出单通道图像宽,表示一共要处理多少个小窗口。转化为了矩阵乘法.
im2col_cpu接收13个参数,分别为输入数据指针(data_im),卷积操作处理的一个卷积组的通道数(channels),输入图像的高(height)与宽(width),原始卷积核的高(kernel_h)与宽(kernel_w),输入图像高(pad_h)与宽(pad_w)方向的pad,卷积操作高(stride_h)与宽(stride_w)方向的步长,卷积核高(stride_h)与宽(stride_h)方向的扩展,输出矩阵数据指针(data_col)*/,该函数相当于执行将矩阵变为对应的乘法矩阵.
col2im_cpu实现与上述功能相反的功能.
#include <vector>
#include "caffe/util/im2col.hpp"
#include "caffe/util/math_functions.hpp"
namespace caffe {
inline bool is_a_ge_zero_and_a_lt_b(int a, int b) { // 若a大于等于0且严格小于b,则返回真.该函数的作用是判断矩阵上pad是否为0
return static_cast<unsigned>(a) < static_cast<unsigned>(b);
}
template <typename Dtype>
void im2col_cpu(const Dtype* data_im, const int channels,
const int height, const int width, const int kernel_h, const int kernel_w,
const int pad_h, const int pad_w,
const int stride_h, const int stride_w,
const int dilation_h, const int dilation_w,
Dtype* data_col) {
const int output_h = (height + 2 * pad_h -
(dilation_h * (kernel_h - 1) + 1)) / stride_h + 1; // 计算卷积层输出图像的高
const int output_w = (width + 2 * pad_w -
(dilation_w * (kernel_w - 1) + 1)) / stride_w + 1; // 计算卷积层输出图像的宽
const int channel_size = height * width; //计算卷积层数据单通道图像的数据容量
for (int channel = channels; channel--; data_im += channel_size) { // 第一个for循环表示输出的矩阵通道数和卷积层输入图像通道是一样的,每次处理一个输入通道的信息
for (int kernel_row = 0; kernel_row < kernel_h; kernel_row++) { // 第二个和第三个for循环表示了输出单通道矩阵的某一列,同时体现了输出单通道矩阵的行数
for (int kernel_col = 0; kernel_col < kernel_w; kernel_col++) {
int input_row = -pad_h + kernel_row * dilation_h; // 在这里找到卷积核中的某一行在输入图像中第一个操作区域的行索引
for (int output_rows = output_h; output_rows; output_rows--) { // 第四个和第五个for循环表示了输出单通道矩阵的某一行,同时体现了输出单通道矩阵的列数
if (!is_a_ge_zero_and_a_lt_b(input_row, height)) { // 如果计算得到的输入图像的行索引小于0或者大于输入图像的高,即判断是否需要pad
for (int output_cols = output_w; output_cols; output_cols--) {
*(data_col++) = 0; // 那么将该行在输出的矩阵上的位置置为0
}
} else {
int input_col = -pad_w + kernel_col * dilation_w; // 找到卷积核中的某一列在输入图像中的第一个操作区域的列索引
for (int output_col = output_w; output_col; output_col--) {
if (is_a_ge_zero_and_a_lt_b(input_col, width)) { // 如果计算得到的输入图像的列值索引大于等于于零或者小于输入图像的宽
*(data_col++) = data_im[input_row * width + input_col]; // 将输入特征图上对应的区域放到输出矩阵上
} else { // 否则,为pad时
*(data_col++) = 0; // 将该行该列在输出矩阵上的位置置为0
}
input_col += stride_w; // 按照宽方向步长遍历卷积核上固定列在输入图像上滑动操作的区域
}
}
input_row += stride_h; // 按照高方向步长遍历卷积核上固定行在输入图像上滑动操作的区域
}
}
}
}
}
template <typename Dtype>
void col2im_cpu(const Dtype* data_col, const int channels,
const int height, const int width, const int kernel_h, const int kernel_w,
const int pad_h, const int pad_w,
const int stride_h, const int stride_w,
const int dilation_h, const int dilation_w,
Dtype* data_im) {
caffe_set(height * width * channels, Dtype(0), data_im); // 首先对输出的区域进行初始化,全部填充0
const int output_h = (height + 2 * pad_h -
(dilation_h * (kernel_h - 1) + 1)) / stride_h + 1; // 计算卷积层输出图像的宽
const int output_w = (width + 2 * pad_w -
(dilation_w * (kernel_w - 1) + 1)) / stride_w + 1; // 计算卷积层输出图像的高
const int channel_size = height * width;//col2im输出的单通道图像容量
for (int channel = channels; channel--; data_im += channel_size) { // 按照输出通道数一个一个处理
for (int kernel_row = 0; kernel_row < kernel_h; kernel_row++) {
for (int kernel_col = 0; kernel_col < kernel_w; kernel_col++) {
int input_row = -pad_h + kernel_row * dilation_h; // 在这里找到卷积核中的某一行在输入图像中的第一个操作区域的行索引
for (int output_rows = output_h; output_rows; output_rows--) {
if (!is_a_ge_zero_and_a_lt_b(input_row, height)) { // 如果计算得到的输入图像的行值索引小于零或者大于输入图像的高(该行为pad)
data_col += output_w; // 那么,直接跳过这output_w个数,这些数是输入图像第一行上面或者最后一行下面pad的0
} else {
int input_col = -pad_w + kernel_col * dilation_w; // 在这里找到卷积核中的某一列在输入图像中的第一个操作区域的列索引
for (int output_col = output_w; output_col; output_col--) {
if (is_a_ge_zero_and_a_lt_b(input_col, width)) { // 如果计算得到的输入图像的列值索引大于等于于零或者小于输入图像的宽(该列不是pad)
data_im[input_row * width + input_col] += *data_col; // 将矩阵上对应的元放到将要输出的图像上
} // 这里没有else,因为如果紧挨的if条件不成立的话,input_row * width + input_col这个下标在data_im中不存在,同时遍历到data_col的对应元为0
data_col++; // 遍历下一个data_col中的数
input_col += stride_w; // 按照宽方向步长遍历卷积核上固定列在输入图像上滑动操作的区域
}
}
input_row += stride_h; // 按照高方向步长遍历卷积核上固定行在输入图像上滑动操作的区域
}
}
}
}
}
}base_conv_layer.hpp
继承自Layer,是一个卷积以及反卷积操作的基类
#ifndef CAFFE_BASE_CONVOLUTION_LAYER_HPP_
#define CAFFE_BASE_CONVOLUTION_LAYER_HPP_
#include <vector>
#include "caffe/blob.hpp"
#include "caffe/layer.hpp"
#include "caffe/proto/caffe.pb.h"
#include "caffe/util/im2col.hpp"
namespace caffe {
/**
* @brief Abstract base class that factors out the BLAS code common to
* ConvolutionLayer and DeconvolutionLayer.
*/
template <typename Dtype>
class BaseConvolutionLayer : public Layer<Dtype> {
public:
// 显示构造函数
explicit BaseConvolutionLayer(const LayerParameter& param)
: Layer<Dtype>(param) {}
// 设置基本一些基本的参数
virtual void LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
// 计算输出数据的维度
virtual void Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual inline int MinBottomBlobs() const { return 1; }
virtual inline int MinTopBlobs() const { return 1; }
virtual inline bool EqualNumBottomTopBlobs() const { return true; }
protected:
// Helper functions that abstract away the column buffer and gemm arguments.
// The last argument in forward_cpu_gemm is so that we can skip the im2col if
// we just called weight_cpu_gemm with the same input.
// 矩阵乘法
void forward_cpu_gemm(const Dtype* input, const Dtype* weights,
Dtype* output, bool skip_im2col = false);
void forward_cpu_bias(Dtype* output, const Dtype* bias);
void backward_cpu_gemm(const Dtype* input, const Dtype* weights,
Dtype* output);
void weight_cpu_gemm(const Dtype* input, const Dtype* output, Dtype*
weights);
void backward_cpu_bias(Dtype* bias, const Dtype* input);
#ifndef CPU_ONLY
void forward_gpu_gemm(const Dtype* col_input, const Dtype* weights,
Dtype* output, bool skip_im2col = false);
void forward_gpu_bias(Dtype* output, const Dtype* bias);
void backward_gpu_gemm(const Dtype* input, const Dtype* weights,
Dtype* col_output);
void weight_gpu_gemm(const Dtype* col_input, const Dtype* output, Dtype*
weights);
void backward_gpu_bias(Dtype* bias, const Dtype* input);
#endif
/// @brief The spatial dimensions of the input.
inline int input_shape(int i) { //返回输入的空间维度
return (*bottom_shape_)[channel_axis_ + i];
}
// reverse_dimensions should return true iff we are implementing deconv, so
// that conv helpers know which dimensions are which.
virtual bool reverse_dimensions() = 0; //计算反向传播时,该参数返回true
// Compute height_out_ and width_out_ from other parameters.
virtual void compute_output_shape() = 0;
/// @brief The spatial dimensions of a filter kernel.
// 滤波器形状 = [kernel_h, kernel_w]
Blob<int> kernel_shape_;
/// @brief The spatial dimensions of the stride.
// 步长形状 = [stride_h, stride_w]
Blob<int> stride_;
/// @brief The spatial dimensions of the padding.
/// pad_形状 = [pad_h, pad_w]
Blob<int> pad_;
/// @brief The spatial dimensions of the dilation.
/// Dilated convolution 的主要贡献就是,如何在去掉池化下采样操作的
/// 同时,而不降低网络的感受野;而 dilated convolution 中的卷积核则
/// 是将卷积核对图像隔一定的距离像素进行卷积运算,以一定的间隔
/// http://weibo.com/ttarticle/p/show?id=2309351000014015306501684301
Blob<int> dilation_;
/// @brief The spatial dimensions of the convolution input.
/// 需要经行卷积运算的输入图像维数 = [输入图像通道数, 输入图像h, 输入图像w]
Blob<int> conv_input_shape_;
/// @brief The spatial dimensions of the col_buffer.
/// col_buffer的形状 = [kernel_dim_, conv_out_spatial_dim_ ]
vector<int> col_buffer_shape_;
/// @brief The spatial dimensions of the output.
/// 经行卷积运算后的输出形状,在派生类中初始化
/// 默认为H_out,W_out
vector<int> output_shape_; //输出的形状
const vector<int>* bottom_shape_; //输入的形状
// 是计算二维卷积还是三维卷积,对于(N, C, H, W)的输入结果为2
// 对于(N, C, D, H, W)的输入,结果为3
int num_spatial_axes_; //空间轴个数(2维,3维)
//默认为C_in*H*W
int bottom_dim_; //输入维度 = 输入图像通道数*输入图像的高*输入图像的宽
//默认为C_out*H_out*W_out
int top_dim_; //输出维度 = 输出图像通道数*输出图像的高*输出图像的宽
int channel_axis_; //输入图像的第几个轴是通道,默认为1
// batchsize
int num_;
int channels_; //输入图像的通道数
int group_; //卷积组的大小,默认为1
// H_out*W_out
int out_spatial_dim_; //输出空间维度 = 卷积之后的图像长*卷积之后图像的宽
// 默认为C_out*C_in*H_k*H_w
int weight_offset_;
//C_out
int num_output_; //卷积后图像的通道数
bool bias_term_; // 是否使用偏置
bool is_1x1_; // 是否1*1卷积核
bool force_nd_im2col_; //是否强制使用n维通用卷积
private:
// wrap im2col/col2im so we don't have to remember the (long) argument lists
// 封装im2col/col2im,然后就不必输入参数
inline void conv_im2col_cpu(const Dtype* data, Dtype* col_buff) {
if (!force_nd_im2col_ && num_spatial_axes_ == 2) {
// 如果不是计算n维通用卷积
im2col_cpu(data, conv_in_channels_,
conv_input_shape_.cpu_data()[1], conv_input_shape_.cpu_data()[2],
kernel_shape_.cpu_data()[0], kernel_shape_.cpu_data()[1],
pad_.cpu_data()[0], pad_.cpu_data()[1],
stride_.cpu_data()[0], stride_.cpu_data()[1],
dilation_.cpu_data()[0], dilation_.cpu_data()[1], col_buff);
}
else {
im2col_nd_cpu(data, num_spatial_axes_, conv_input_shape_.cpu_data(),
col_buffer_shape_.data(), kernel_shape_.cpu_data(),
pad_.cpu_data(), stride_.cpu_data(), dilation_.cpu_data(), col_buff);
}
}
inline void conv_col2im_cpu(const Dtype* col_buff, Dtype* data) {
if (!force_nd_im2col_ && num_spatial_axes_ == 2) {
col2im_cpu(col_buff, conv_in_channels_,
conv_input_shape_.cpu_data()[1], conv_input_shape_.cpu_data()[2],
kernel_shape_.cpu_data()[0], kernel_shape_.cpu_data()[1],
pad_.cpu_data()[0], pad_.cpu_data()[1],
stride_.cpu_data()[0], stride_.cpu_data()[1],
dilation_.cpu_data()[0], dilation_.cpu_data()[1], data);
} else {
col2im_nd_cpu(col_buff, num_spatial_axes_, conv_input_shape_.cpu_data(),
col_buffer_shape_.data(), kernel_shape_.cpu_data(),
pad_.cpu_data(), stride_.cpu_data(), dilation_.cpu_data(), data);
}
}
#ifndef CPU_ONLY
inline void conv_im2col_gpu(const Dtype* data, Dtype* col_buff) {
if (!force_nd_im2col_ && num_spatial_axes_ == 2) {
im2col_gpu(data, conv_in_channels_,
conv_input_shape_.cpu_data()[1], conv_input_shape_.cpu_data()[2],
kernel_shape_.cpu_data()[0], kernel_shape_.cpu_data()[1],
pad_.cpu_data()[0], pad_.cpu_data()[1],
stride_.cpu_data()[0], stride_.cpu_data()[1],
dilation_.cpu_data()[0], dilation_.cpu_data()[1], col_buff);
} else {
im2col_nd_gpu(data, num_spatial_axes_, num_kernels_im2col_,
conv_input_shape_.gpu_data(), col_buffer_.gpu_shape(),
kernel_shape_.gpu_data(), pad_.gpu_data(),
stride_.gpu_data(), dilation_.gpu_data(), col_buff);
}
}
inline void conv_col2im_gpu(const Dtype* col_buff, Dtype* data) {
if (!force_nd_im2col_ && num_spatial_axes_ == 2) {
col2im_gpu(col_buff, conv_in_channels_,
conv_input_shape_.cpu_data()[1], conv_input_shape_.cpu_data()[2],
kernel_shape_.cpu_data()[0], kernel_shape_.cpu_data()[1],
pad_.cpu_data()[0], pad_.cpu_data()[1],
stride_.cpu_data()[0], stride_.cpu_data()[1],
dilation_.cpu_data()[0], dilation_.cpu_data()[1], data);
} else {
col2im_nd_gpu(col_buff, num_spatial_axes_, num_kernels_col2im_,
conv_input_shape_.gpu_data(), col_buffer_.gpu_shape(),
kernel_shape_.gpu_data(), pad_.gpu_data(), stride_.gpu_data(),
dilation_.gpu_data(), data);
}
}
#endif
int num_kernels_im2col_;
int num_kernels_col2im_;
//C_out 卷积的输出通道数,在参数配置文件中设置
int conv_out_channels_;
//C_in 卷积的输入通道数,在参数配置文件中设置
int conv_in_channels_;
// 默认为输出H_out*W_out
int conv_out_spatial_dim_;
// C_in*H_k*W_k
int kernel_dim_;
int col_offset_;
int output_offset_;
//im2col使用的存储空间
Blob<Dtype> col_buffer_;
//将偏置扩展成矩阵
Blob<Dtype> bias_multiplier_;
};
} // namespace caffe
#endif // CAFFE_BASE_CONVOLUTION_LAYER_HPP_base_conv_layer.cpp
LayerSetUp()函数中设置kernel size, stride, padding, dilation的维度信息.还对对应的weights和biases进行了存储,反别存储在blobs_[0]和blobs_[1]中.通过im2col_cpu函数和caffe_cpu_gemm函数实现卷积.im2col_cpu实现的是对应矩阵的转换,caffe_cpu_gemm则实现相应的矩阵乘法.`
#include <algorithm>
#include <vector>
#include "caffe/filler.hpp"
#include "caffe/layers/base_conv_layer.hpp"
#include "caffe/util/im2col.hpp"
#include "caffe/util/math_functions.hpp"
namespace caffe {
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
// Configure the kernel size, padding, stride, and inputs.
// 父类的layer_param成员,从网络配置文件得到参数
ConvolutionParameter conv_param = this->layer_param_.convolution_param();
// 判断是否使用n维通用卷积,default = false, bool量
force_nd_im2col_ = conv_param.force_nd_im2col();
// 通道维数,默认为1,具体内容可查看caffe.proto中axis参数的对应解释
channel_axis_ = bottom[0]->CanonicalAxisIndex(conv_param.axis());
// channel_axis_从零开始,即获得最初的通道维数
const int first_spatial_axis = channel_axis_ + 1;
// 输入数据维数
const int num_axes = bottom[0]->num_axes();
// 是计算二维卷积还是三维卷积,对于(N, C, H, W)的输入结果为2
// 对于(N, C, D, H, W)的输入,结果为3, 即空间轴的个数,维度
num_spatial_axes_ = num_axes - first_spatial_axis;
CHECK_GE(num_spatial_axes_, 0);
//
vector<int> bottom_dim_blob_shape(1, num_spatial_axes_ + 1);
//当num_spatial_axes_==2时, spatial_dim_blob_shape这个vector只包含一个元素且值为2;
vector<int> spatial_dim_blob_shape(1, std::max(num_spatial_axes_, 1));
// Setup filter kernel dimensions (kernel_shape_).
// 设置滤波器维数
kernel_shape_.Reshape(spatial_dim_blob_shape);
// kernel_shape_的指针,用来对滤波器核的每一维参数赋值,里面存储相应的维度
int* kernel_shape_data = kernel_shape_.mutable_cpu_data();
if (conv_param.has_kernel_h() || conv_param.has_kernel_w()) {
//判读是否为2维卷积核
CHECK_EQ(num_spatial_axes_, 2)
<< "kernel_h & kernel_w can only be used for 2D convolution.";
CHECK_EQ(0, conv_param.kernel_size_size())
<< "Either kernel_size or kernel_h/w should be specified; not both.";
//设置卷积核长宽
kernel_shape_data[0] = conv_param.kernel_h();
kernel_shape_data[1] = conv_param.kernel_w();
} else {
//或者通过kernel_size参数设置滤波器核的每一维参数大小
const int num_kernel_dims = conv_param.kernel_size_size();
CHECK(num_kernel_dims == 1 || num_kernel_dims == num_spatial_axes_)
<< "kernel_size must be specified once, or once per spatial dimension "
<< "(kernel_size specified " << num_kernel_dims << " times; "
<< num_spatial_axes_ << " spatial dims).";
for (int i = 0; i < num_spatial_axes_; ++i) {
kernel_shape_data[i] =
conv_param.kernel_size((num_kernel_dims == 1) ? 0 : i);
}
}
//判断滤波器核大小是否非0
for (int i = 0; i < num_spatial_axes_; ++i) {
CHECK_GT(kernel_shape_data[i], 0) << "Filter dimensions must be nonzero.";
}
// Setup stride dimensions (stride_).
// 设置步长参数,和上面类似
stride_.Reshape(spatial_dim_blob_shape);
int* stride_data = stride_.mutable_cpu_data();
if (conv_param.has_stride_h() || conv_param.has_stride_w()) {
CHECK_EQ(num_spatial_axes_, 2)
<< "stride_h & stride_w can only be used for 2D convolution.";
CHECK_EQ(0, conv_param.stride_size())
<< "Either stride or stride_h/w should be specified; not both.";
stride_data[0] = conv_param.stride_h();
stride_data[1] = conv_param.stride_w();
} else {
const int num_stride_dims = conv_param.stride_size();
CHECK(num_stride_dims == 0 || num_stride_dims == 1 ||
num_stride_dims == num_spatial_axes_)
<< "stride must be specified once, or once per spatial dimension "
<< "(stride specified " << num_stride_dims << " times; "
<< num_spatial_axes_ << " spatial dims).";
const int kDefaultStride = 1;
for (int i = 0; i < num_spatial_axes_; ++i) {
stride_data[i] = (num_stride_dims == 0) ? kDefaultStride :
conv_param.stride((num_stride_dims == 1) ? 0 : i);
CHECK_GT(stride_data[i], 0) << "Stride dimensions must be nonzero.";
}
}
// Setup pad dimensions (pad_).
// 设置padding参数,和上面类似
pad_.Reshape(spatial_dim_blob_shape);
int* pad_data = pad_.mutable_cpu_data();
if (conv_param.has_pad_h() || conv_param.has_pad_w()) {
CHECK_EQ(num_spatial_axes_, 2)
<< "pad_h & pad_w can only be used for 2D convolution.";
CHECK_EQ(0, conv_param.pad_size())
<< "Either pad or pad_h/w should be specified; not both.";
pad_data[0] = conv_param.pad_h();
pad_data[1] = conv_param.pad_w();
} else {
const int num_pad_dims = conv_param.pad_size();
CHECK(num_pad_dims == 0 || num_pad_dims == 1 ||
num_pad_dims == num_spatial_axes_)
<< "pad must be specified once, or once per spatial dimension "
<< "(pad specified " << num_pad_dims << " times; "
<< num_spatial_axes_ << " spatial dims).";
const int kDefaultPad = 0;
for (int i = 0; i < num_spatial_axes_; ++i) {
pad_data[i] = (num_pad_dims == 0) ? kDefaultPad :
conv_param.pad((num_pad_dims == 1) ? 0 : i);
}
}
// Setup dilation dimensions (dilation_).
// 设置dilation参数
dilation_.Reshape(spatial_dim_blob_shape);
int* dilation_data = dilation_.mutable_cpu_data();
const int num_dilation_dims = conv_param.dilation_size();
CHECK(num_dilation_dims == 0 || num_dilation_dims == 1 ||
num_dilation_dims == num_spatial_axes_)
<< "dilation must be specified once, or once per spatial dimension "
<< "(dilation specified " << num_dilation_dims << " times; "
<< num_spatial_axes_ << " spatial dims).";
const int kDefaultDilation = 1;
for (int i = 0; i < num_spatial_axes_; ++i) {
dilation_data[i] = (num_dilation_dims == 0) ? kDefaultDilation :
conv_param.dilation((num_dilation_dims == 1) ? 0 : i);
}
// Special case: im2col is the identity for 1x1 convolution with stride 1
// and no padding, so flag for skipping the buffer and transformation.
// 判断是否为1x1卷积核
is_1x1_ = true;
for (int i = 0; i < num_spatial_axes_; ++i) {
is_1x1_ &=
kernel_shape_data[i] == 1 && stride_data[i] == 1 && pad_data[i] == 0;
if (!is_1x1_) { break; }
}
// Configure output channels and groups.
// 设置通道数值
channels_ = bottom[0]->shape(channel_axis_);
// 设置滤波器个数,也就是输出数据的通道数
// C_out
num_output_ = this->layer_param_.convolution_param().num_output();
CHECK_GT(num_output_, 0);
//没什么用
group_ = this->layer_param_.convolution_param().group();
CHECK_EQ(channels_ % group_, 0);
CHECK_EQ(num_output_ % group_, 0)
<< "Number of output should be multiples of group.";
//只有在反卷积的时候reverse_dimensions()才为真
//设置卷积层的输入输出通道
if (reverse_dimensions()) {
conv_out_channels_ = channels_;
conv_in_channels_ = num_output_;
} else {
conv_out_channels_ = num_output_; //输出图像的通道数
conv_in_channels_ = channels_; //输入图像的通道数
}
// Handle the parameters: weights and biases.
// - blobs_[0] holds the filter weights
// - blobs_[1] holds the biases (optional)
//设置滤波器权重的形状
vector<int> weight_shape(2);
weight_shape[0] = conv_out_channels_;
weight_shape[1] = conv_in_channels_ / group_;
for (int i = 0; i < num_spatial_axes_; ++i) {
weight_shape.push_back(kernel_shape_data[i]);
}
// 偏置项
bias_term_ = this->layer_param_.convolution_param().bias_term();
//设置偏置形状
vector<int> bias_shape(bias_term_, num_output_);
//如果在基类初始化了blobs_(根据网络的描述文件来看,卷积层一般不会出现这种情况)
if (this->blobs_.size() > 0) {
CHECK_EQ(1 + bias_term_, this->blobs_.size())
<< "Incorrect number of weight blobs.";
if (weight_shape != this->blobs_[0]->shape()) {
Blob<Dtype> weight_shaped_blob(weight_shape);
LOG(FATAL) << "Incorrect weight shape: expected shape "
<< weight_shaped_blob.shape_string() << "; instead, shape was "
<< this->blobs_[0]->shape_string();
}
if (bias_term_ && bias_shape != this->blobs_[1]->shape()) {
Blob<Dtype> bias_shaped_blob(bias_shape);
LOG(FATAL) << "Incorrect bias shape: expected shape "
<< bias_shaped_blob.shape_string() << "; instead, shape was "
<< this->blobs_[1]->shape_string();
}
LOG(INFO) << "Skipping parameter initialization";
}
else {
// 权值初始化
if (bias_term_) {
this->blobs_.resize(2);
} else {
this->blobs_.resize(1);
}
// Initialize and fill the weights:
// output channels x input channels per-group x kernel height x kernel width
// 存入weights和biases.blobs_[0]里面存放的是weights,blobs_[1]里面存放的是biases.
this->blobs_[0].reset(new Blob<Dtype>(weight_shape));
shared_ptr<Filler<Dtype> > weight_filler(GetFiller<Dtype>(
this->layer_param_.convolution_param().weight_filler()));
weight_filler->Fill(this->blobs_[0].get());
// If necessary, initialize and fill the biases.
if (bias_term_) {
this->blobs_[1].reset(new Blob<Dtype>(bias_shape));
shared_ptr<Filler<Dtype> > bias_filler(GetFiller<Dtype>(
this->layer_param_.convolution_param().bias_filler()));
bias_filler->Fill(this->blobs_[1].get());
}
}
// blobs_[0]维数:(C_out,C_in,H_k,W_k)
//C_in*H_k*W_k
kernel_dim_ = this->blobs_[0]->count(1);
// 默认为C_out*C_in*H_k*H_w
weight_offset_ = conv_out_channels_ * kernel_dim_ / group_;
// Propagate gradients to the parameters (as directed by backward pass).
this->param_propagate_down_.resize(this->blobs_.size(), true);
}
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
// 图片开始的坐标轴,默认为2,即(N,C,H,W)中从H开始
const int first_spatial_axis = channel_axis_ + 1;
CHECK_EQ(bottom[0]->num_axes(), first_spatial_axis + num_spatial_axes_)
<< "bottom num_axes may not change.";
//N,每批次的输入数据数量
num_ = bottom[0]->count(0, channel_axis_);
CHECK_EQ(bottom[0]->shape(channel_axis_), channels_)
<< "Input size incompatible with convolution kernel.";
// TODO: generalize to handle inputs of different shapes.
for (int bottom_id = 1; bottom_id < bottom.size(); ++bottom_id) {
CHECK(bottom[0]->shape() == bottom[bottom_id]->shape())
<< "All inputs must have the same shape.";
}
// Shape the tops.
// 设置输出数据维数
bottom_shape_ = &bottom[0]->shape();
compute_output_shape();
// top_shape 输出数据维数
// vector构造函数
vector<int> top_shape(bottom[0]->shape().begin(),
bottom[0]->shape().begin() + channel_axis_);
top_shape.push_back(num_output_);
for (int i = 0; i < num_spatial_axes_; ++i) {
top_shape.push_back(output_shape_[i]);
}
for (int top_id = 0; top_id < top.size(); ++top_id) {
top[top_id]->Reshape(top_shape);
}
if (reverse_dimensions()) {
conv_out_spatial_dim_ = bottom[0]->count(first_spatial_axis);
}
else {
// 默认为输出H_out*W_out
conv_out_spatial_dim_ = top[0]->count(first_spatial_axis);
}
//
col_offset_ = kernel_dim_ * conv_out_spatial_dim_;
output_offset_ = conv_out_channels_ * conv_out_spatial_dim_ / group_;
// Setup input dimensions (conv_input_shape_).
vector<int> bottom_dim_blob_shape(1, num_spatial_axes_ + 1);
conv_input_shape_.Reshape(bottom_dim_blob_shape);
int* conv_input_shape_data = conv_input_shape_.mutable_cpu_data();
for (int i = 0; i < num_spatial_axes_ + 1; ++i) {
if (reverse_dimensions()) {
conv_input_shape_data[i] = top[0]->shape(channel_axis_ + i);
} else {
conv_input_shape_data[i] = bottom[0]->shape(channel_axis_ + i);
}
}
// The im2col result buffer will only hold one image at a time to avoid
// overly large memory usage. In the special case of 1x1 convolution
// it goes lazily unused to save memory.
col_buffer_shape_.clear();
col_buffer_shape_.push_back(kernel_dim_ * group_);
for (int i = 0; i < num_spatial_axes_; ++i) {
if (reverse_dimensions()) {
col_buffer_shape_.push_back(input_shape(i + 1));
} else {
col_buffer_shape_.push_back(output_shape_[i]);
}
}
col_buffer_.Reshape(col_buffer_shape_);
//默认为C_in*H*W
bottom_dim_ = bottom[0]->count(channel_axis_);
//默认为C_out*H_out*W_out
top_dim_ = top[0]->count(channel_axis_);
num_kernels_im2col_ = conv_in_channels_ * conv_out_spatial_dim_;
num_kernels_col2im_ = reverse_dimensions() ? top_dim_ : bottom_dim_;
// Set up the all ones "bias multiplier" for adding biases by BLAS
// H_out*W_out
out_spatial_dim_ = top[0]->count(first_spatial_axis);
if (bias_term_) {
vector<int> bias_multiplier_shape(1, out_spatial_dim_);
bias_multiplier_.Reshape(bias_multiplier_shape);
// 全部初始化为1
caffe_set(bias_multiplier_.count(), Dtype(1),
bias_multiplier_.mutable_cpu_data());
}
}
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::forward_cpu_gemm(const Dtype* input,
const Dtype* weights, Dtype* output, bool skip_im2col) {
// 常量指针,指向的内容不可更改,指针本身内容可更改
const Dtype* col_buff = input;
if (!is_1x1_) {
if (!skip_im2col) {
// 如果没有1x1卷积,也没有skip_im2col
// 则使用conv_im2col_cpu对使用卷积核滑动过程中的每一个kernel大小的图像块
// 变成一个列向量,形成一个height=kernel_dim_的
// width = 卷积后图像heght*卷积后图像width
conv_im2col_cpu(input, col_buffer_.mutable_cpu_data());
}
col_buff = col_buffer_.cpu_data();
}
// 使用caffe的cpu_gemm来进行计算
for (int g = 0; g < group_; ++g) {
// 用group_分组分别进行计算
// conv_out_channels_ / group_是每个卷积组的输出的channel
// conv_out_channels_ :卷积层的输出通道
// conv_out_spatial_dim_: H_out*W_out
// kernel_dim_ = input channels per-group x kernel height x kernel width
// weight: 卷积核参数指针,形状是 [conv_out_channel x kernel_dim_]
// col_offset:图片展成的列向量
// output: 输出
/*
功能: C=alpha*A*B+beta*C
A,B,C 是输入矩阵(一维数组格式)
所以为:output = 1.*weights*col_buff+0*output
其中weights矩阵的维数为[C_out,C_in*H_k*W_k]
col_buff矩阵的维数为[C_in*H_k*W_K, H_out*W_out]
所以得到的结果output的维数为[C_out, H_out*W_out]
*/
/*
* 滤波器权值没有经行相应的转换是因为,权值和数据都是一维数组存储的,但数据是按每行存储的
* 所以需要im2col,而滤波器权值本来就是那样存放的
*/
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, conv_out_channels_ /
group_, conv_out_spatial_dim_, kernel_dim_,
(Dtype)1., weights + weight_offset_ * g, col_buff + col_offset_ * g,
(Dtype)0., output + output_offset_ * g);
}
}
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::forward_cpu_bias(Dtype* output,
const Dtype* bias) {
//output = 1.*bias*bias_multiplier_+1*output
// bias:[C_out , 1]
// bias_multiplier_:[1 , H_out*W_out]
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num_output_,
out_spatial_dim_, 1, (Dtype)1., bias, bias_multiplier_.cpu_data(),
(Dtype)1., output);
}
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::backward_cpu_gemm(const Dtype* output,
const Dtype* weights, Dtype* input) {
Dtype* col_buff = col_buffer_.mutable_cpu_data();
if (is_1x1_) {
col_buff = input;
}
// 前向:output = weights*col_buff
// 反向:col_buff = weights^T*output
// 这是对输入数据求梯度
for (int g = 0; g < group_; ++g) {
caffe_cpu_gemm<Dtype>(CblasTrans, CblasNoTrans, kernel_dim_,
conv_out_spatial_dim_, conv_out_channels_ / group_,
(Dtype)1., weights + weight_offset_ * g, output + output_offset_ * g,
(Dtype)0., col_buff + col_offset_ * g);
}
if (!is_1x1_) {
// Blob中数据是row-major存储的,W是变化最快的维度
conv_col2im_cpu(col_buff, input);
}
}
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::weight_cpu_gemm(const Dtype* input,
const Dtype* output, Dtype* weights) {
const Dtype* col_buff = input;
if (!is_1x1_) {
conv_im2col_cpu(input, col_buffer_.mutable_cpu_data());
col_buff = col_buffer_.cpu_data();
}
// 前向:output = weights*col_buff
// 反向:weights = output*col_buff^T
// 这是对滤波器权值求导
for (int g = 0; g < group_; ++g) {
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasTrans, conv_out_channels_ / group_,
kernel_dim_, conv_out_spatial_dim_,
(Dtype)1., output + output_offset_ * g, col_buff + col_offset_ * g,
(Dtype)1., weights + weight_offset_ * g);
}
}
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::backward_cpu_bias(Dtype* bias,
const Dtype* input) {
// 对权值反向求导
caffe_cpu_gemv<Dtype>(CblasNoTrans, num_output_, out_spatial_dim_, 1.,
input, bias_multiplier_.cpu_data(), 1., bias);
}
#ifndef CPU_ONLY
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::forward_gpu_gemm(const Dtype* input,
const Dtype* weights, Dtype* output, bool skip_im2col) {
const Dtype* col_buff = input;
if (!is_1x1_) {
if (!skip_im2col) {
conv_im2col_gpu(input, col_buffer_.mutable_gpu_data());
}
col_buff = col_buffer_.gpu_data();
}
for (int g = 0; g < group_; ++g) {
caffe_gpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, conv_out_channels_ /
group_, conv_out_spatial_dim_, kernel_dim_,
(Dtype)1., weights + weight_offset_ * g, col_buff + col_offset_ * g,
(Dtype)0., output + output_offset_ * g);
}
}
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::forward_gpu_bias(Dtype* output,
const Dtype* bias) {
caffe_gpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num_output_,
out_spatial_dim_, 1, (Dtype)1., bias, bias_multiplier_.gpu_data(),
(Dtype)1., output);
}
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::backward_gpu_gemm(const Dtype* output,
const Dtype* weights, Dtype* input) {
Dtype* col_buff = col_buffer_.mutable_gpu_data();
if (is_1x1_) {
col_buff = input;
}
for (int g = 0; g < group_; ++g) {
caffe_gpu_gemm<Dtype>(CblasTrans, CblasNoTrans, kernel_dim_,
conv_out_spatial_dim_, conv_out_channels_ / group_,
(Dtype)1., weights + weight_offset_ * g, output + output_offset_ * g,
(Dtype)0., col_buff + col_offset_ * g);
}
if (!is_1x1_) {
conv_col2im_gpu(col_buff, input);
}
}
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::weight_gpu_gemm(const Dtype* input,
const Dtype* output, Dtype* weights) {
const Dtype* col_buff = input;
if (!is_1x1_) {
conv_im2col_gpu(input, col_buffer_.mutable_gpu_data());
col_buff = col_buffer_.gpu_data();
}
for (int g = 0; g < group_; ++g) {
caffe_gpu_gemm<Dtype>(CblasNoTrans, CblasTrans, conv_out_channels_ / group_,
kernel_dim_, conv_out_spatial_dim_,
(Dtype)1., output + output_offset_ * g, col_buff + col_offset_ * g,
(Dtype)1., weights + weight_offset_ * g);
}
}
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::backward_gpu_bias(Dtype* bias,
const Dtype* input) {
caffe_gpu_gemv<Dtype>(CblasNoTrans, num_output_, out_spatial_dim_, 1.,
input, bias_multiplier_.gpu_data(), 1., bias);
}
#endif // !CPU_ONLY
INSTANTIATE_CLASS(BaseConvolutionLayer);
} // namespace caffeconv_layer.hpp和conv_layer.cpp
conv_layer.hpp
#ifndef CAFFE_CONV_LAYER_HPP_
#define CAFFE_CONV_LAYER_HPP_
#include <vector>
#include "caffe/blob.hpp"
#include "caffe/layer.hpp"
#include "caffe/proto/caffe.pb.h"
#include "caffe/layers/base_conv_layer.hpp"
namespace caffe {
template <typename Dtype>
class ConvolutionLayer : public BaseConvolutionLayer<Dtype> {
public:0
explicit ConvolutionLayer(const LayerParameter& param)
: BaseConvolutionLayer<Dtype>(param) {}
virtual inline const char* type() const { return "Convolution"; }
protected:
virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Forward_gpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom);
virtual void Backward_gpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom);
virtual inline bool reverse_dimensions() { return false; }
virtual void compute_output_shape();
};
} // namespace caffe
#endif // CAFFE_CONV_LAYER_HPP_conv_layer.cpp
#include <vector>
#include "caffe/layers/conv_layer.hpp"
namespace caffe {
template <typename Dtype>
void ConvolutionLayer<Dtype>::compute_output_shape() { // 计算输出的尺寸
const int* kernel_shape_data = this->kernel_shape_.cpu_data(); // 加载相关数据
const int* stride_data = this->stride_.cpu_data();
const int* pad_data = this->pad_.cpu_data();
const int* dilation_data = this->dilation_.cpu_data();
//清除数据,但内存并没有释放
this->output_shape_.clear();
for (int i = 0; i < this->num_spatial_axes_; ++i) {
// i + 1 to skip channel axis
const int input_dim = this->input_shape(i + 1);
const int kernel_extent = dilation_data[i] * (kernel_shape_data[i] - 1) + 1;
const int output_dim = (input_dim + 2 * pad_data[i] - kernel_extent)
/ stride_data[i] + 1; // 计算输出尺寸
this->output_shape_.push_back(output_dim);
}
}
template <typename Dtype>
void ConvolutionLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) { // 正向传播
const Dtype* weight = this->blobs_[0]->cpu_data(); //加载权重信息
for (int i = 0; i < bottom.size(); ++i) {
const Dtype* bottom_data = bottom[i]->cpu_data(); //加载输入数据信息
Dtype* top_data = top[i]->mutable_cpu_data(); //加载输出数据信息
//对一个bitchsize的每一张图片进行前向计算
for (int n = 0; n < this->num_; ++n) {
// 基类的forward_cpu_gemm函数
// 计算的是top_data[n * this->top_dim_] =
// weights X bottom_data[n * this->bottom_dim_]
// 输入的是一幅图像的数据,对应的是这幅图像卷积之后的位置
this->forward_cpu_gemm(bottom_data + n * this->bottom_dim_, weight,
top_data + n * this->top_dim_); //计算对应卷积,三个参数,对应输入数据,权重和输出数据
if (this->bias_term_) {
const Dtype* bias = this->blobs_[1]->cpu_data();
this->forward_cpu_bias(top_data + n * this->top_dim_, bias);
}
}
}
}
template <typename Dtype>
void ConvolutionLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) { // 反向传播
const Dtype* weight = this->blobs_[0]->cpu_data(); //权重值
Dtype* weight_diff = this->blobs_[0]->mutable_cpu_diff(); //权重梯度
for (int i = 0; i < top.size(); ++i) {
const Dtype* top_diff = top[i]->cpu_diff(); //顶层的梯度
const Dtype* bottom_data = bottom[i]->cpu_data();
Dtype* bottom_diff = bottom[i]->mutable_cpu_diff(); //反向传播得到底层的梯度
// Bias gradient, if necessary. 如果有bias项,计算bias导数
if (this->bias_term_ && this->param_propagate_down_[1]) {
Dtype* bias_diff = this->blobs_[1]->mutable_cpu_diff();
for (int n = 0; n < this->num_; ++n) {
this->backward_cpu_bias(bias_diff, top_diff + n * this->top_dim_);
}
}
// 计算weights的梯度
if (this->param_propagate_down_[0] || propagate_down[i]) {
for (int n = 0; n < this->num_; ++n) {
// gradient w.r.t. weight. Note that we will accumulate diffs.
// 对权值求导,将会累加梯度
if (this->param_propagate_down_[0]) {
this->weight_cpu_gemm(bottom_data + n * this->bottom_dim_,
top_diff + n * this->top_dim_, weight_diff);
}
// gradient w.r.t. bottom data, if necessary.
// 如果需要的话,向下传播
if (propagate_down[i]) {
this->backward_cpu_gemm(top_diff + n * this->top_dim_, weight,
bottom_diff + n * this->bottom_dim_);
}
}
}
}
}
#ifdef CPU_ONLY
STUB_GPU(ConvolutionLayer);
#endif
INSTANTIATE_CLASS(ConvolutionLayer);
} // namespace cafferelu_layer.hpp和relu_layer.cpp
relu_layer.hpp
#ifndef CAFFE_RELU_LAYER_HPP_ //防止头文件被重复引用定义
#define CAFFE_RELU_LAYER_HPP_
#include <vector>
#include "caffe/blob.hpp"
#include "caffe/layer.hpp"
#include "caffe/proto/caffe.pb.h"
#include "caffe/layers/neuron_layer.hpp"
namespace caffe {
template <typename Dtype>
class ReLULayer : public NeuronLayer<Dtype> { // ReLULayer,派生于NeuronLayer,实现了ReLU激活函数计算
public:
explicit ReLULayer(const LayerParameter& param)
: NeuronLayer<Dtype>(param) {} // 显式构造函数,NeuronLayer的参数显式传递给ReLULayer,LayerParameter:protobuf文件中存储的layer参数
virtual inline const char* type() const { return "ReLU"; } // 虚内联函数,const成员函数,返回类名字符串
protected:
virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top); //前向传播函数
virtual void Forward_gpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top); //GPU版本前馈实现
virtual void Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom); //反向传播函数
virtual void Backward_gpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom);
};
} // namespace caffe
#endif // CAFFE_RELU_LAYER_HPP_relu_layer.cpp
#include <algorithm>
#include <vector>
#include "caffe/layers/relu_layer.hpp"
namespace caffe {
template <typename Dtype> // 定义前向传播函数
void ReLULayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_data = bottom[0]->cpu_data(); // 获取输入blob的data指针
Dtype* top_data = top[0]->mutable_cpu_data(); // 获取输出blob的data指针
const int count = bottom[0]->count(); // 获得输入blob元素个数
Dtype negative_slope = this->layer_param_.relu_param().negative_slope(); // 获取ReLU参数,默认值为0,即普通ReLU
for (int i = 0; i < count; ++i) {
top_data[i] = std::max(bottom_data[i], Dtype(0)) // ReLU f(x)=max(0,x)
+ negative_slope * std::min(bottom_data[i], Dtype(0));
}
}
template <typename Dtype>
void ReLULayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top, // 定义反向传播函数
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
if (propagate_down[0]) {
const Dtype* bottom_data = bottom[0]->cpu_data(); // 获得前一层的data指针,data:钱箱传播所用数据
const Dtype* top_diff = top[0]->cpu_diff(); // 获得后一层的diff指针,diff:反向传播所用数据
Dtype* bottom_diff = bottom[0]->mutable_cpu_diff(); // 获取前一层的diff指针,diff:反向传播所用数据
const int count = bottom[0]->count(); // 获取需要参与计算的元素总和
Dtype negative_slope = this->layer_param_.relu_param().negative_slope(); // 获取ReLU参数,默认值为0,即普通ReLU
for (int i = 0; i < count; ++i) { // ReLU的导函数就是bottom_data[i] > 0,根据求导链式法则,后一层的误差乘以导函数得到前一层的误差
bottom_diff[i] = top_diff[i] * ((bottom_data[i] > 0)
+ negative_slope * (bottom_data[i] <= 0)); //
}
}
}
#ifdef CPU_ONLY
STUB_GPU(ReLULayer);
#endif
INSTANTIATE_CLASS(ReLULayer);
} // namespace caffepooling_layer.hpp和pooling_layer.cpp
Pooling 层一般在网络中是跟在Conv卷积层之后,做采样操作,其实是为了进一步缩小feature map,同时也能增大神经元的视野。
enum PoolMethod { // 枚举类型,Pooling的方法:Max(最大值采样)、AVE(均值采样)、STOCHASTIC(随机采样)
MAX = 0;
AVE = 1;
STOCHASTIC = 2;
} 池化层一共有三种方法:最大值采样,均值采样,随机采样
pooling_layer.hpp
#ifndef CAFFE_POOLING_LAYER_HPP_
#define CAFFE_POOLING_LAYER_HPP_
#include <vector>
#include "caffe/blob.hpp"
#include "caffe/layer.hpp"
#include "caffe/proto/caffe.pb.h"
namespace caffe {
template <typename Dtype>
class PoolingLayer : public Layer<Dtype> { // PoolingLayer类,继承于基类Layer类
public:
explicit PoolingLayer(const LayerParameter& param)
: Layer<Dtype>(param) {} // 显示构造函数
virtual void LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top); // 参数初始化,通过类PoolingParameter获取成员变量值,包括: global_pooling_、kernel_h_、kernel_w_、pad_h_、pad_w_、stride_h_、stride_w_
virtual void Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top); // 调整top blobs的shape
virtual inline const char* type() const { return "Pooling"; } // 获得Pooling layer的类型: Pooling
virtual inline int ExactNumBottomBlobs() const { return 1; } // 获得Pooling layer所需的bottom blobs的个数: 1
virtual inline int MinTopBlobs() const { return 1; } // 获得Pooling layer所需的bottom blobs的最少个数: 1
// MAX POOL layers can output an extra top blob for the mask;
// others can only output the pooled inputs.
virtual inline int MaxTopBlobs() const {
return (this->layer_param_.pooling_param().pool() ==
PoolingParameter_PoolMethod_MAX) ? 2 : 1; // 获得Pooling layer所需的bottom blobs的最多个数: Max为2,其它(Avg, Stochastic)为1
}
protected:
// 重写layer纯虚函数
virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top); // CPU实现Pooling layer的前向传播
virtual void Forward_gpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom);
virtual void Backward_gpu(const vector<Blob<Dtype>*>& top, // CPU实现Pooling layer的反向传播,仅有Max和Ave两种方法实现
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom);
// Caffe中类的成员变量名都带有后缀"_",这样就容易区分临时变量和类成员变量
int kernel_h_, kernel_w_;
int stride_h_, stride_w_;
int pad_h_, pad_w_;
int channels_;
int height_, width_;
// pooling之后的高度、宽度,pooled_height_ = (height_ + 2 * pad_h_ - kernel_h_) / stride_h_)) + 1
int pooled_height_, pooled_width_;
// 是否全区域池化,将整幅图像降采样为1*1
bool global_pooling_;
// 保存rand_pooling的idx_,随机采样索引
Blob<Dtype> rand_idx_;
// 保存max_pooling的idx_,最大值采样索引
Blob<int> max_idx_;
};
} // namespace caffe
#endif // CAFFE_POOLING_LAYER_HPP_pooling_layer.cpp
#include <algorithm>
#include <cfloat>
#include <vector>
#include "caffe/layers/pooling_layer.hpp"
#include "caffe/util/math_functions.hpp"
namespace caffe {
using std::min;
using std::max;
template <typename Dtype>
void PoolingLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
PoolingParameter pool_param = this->layer_param_.pooling_param();
if (pool_param.global_pooling()) { // global 的kernel大小等于feature map的大小,即每个feature map只得到一个值
CHECK(!(pool_param.has_kernel_size() || // 判断是否提供pooling的kernel大小
pool_param.has_kernel_h() || pool_param.has_kernel_w()))
<< "With Global_pooling: true Filter size cannot specified";
} else {
CHECK(!pool_param.has_kernel_size() !=
!(pool_param.has_kernel_h() && pool_param.has_kernel_w()))
<< "Filter size is kernel_size OR kernel_h and kernel_w; not both";
CHECK(pool_param.has_kernel_size() ||
(pool_param.has_kernel_h() && pool_param.has_kernel_w()))
<< "For non-square filters both kernel_h and kernel_w are required.";
}
CHECK((!pool_param.has_pad() && pool_param.has_pad_h() // 判断是否提供pad或stride
&& pool_param.has_pad_w())
|| (!pool_param.has_pad_h() && !pool_param.has_pad_w()))
<< "pad is pad OR pad_h and pad_w are required.";
CHECK((!pool_param.has_stride() && pool_param.has_stride_h()
&& pool_param.has_stride_w())
|| (!pool_param.has_stride_h() && !pool_param.has_stride_w()))
<< "Stride is stride OR stride_h and stride_w are required.";
global_pooling_ = pool_param.global_pooling();
// 设置pooling kernel大小
if (global_pooling_) {
kernel_h_ = bottom[0]->height(); // bottom[0]:feature map
kernel_w_ = bottom[0]->width();
} else {
if (pool_param.has_kernel_size()) {
kernel_h_ = kernel_w_ = pool_param.kernel_size();
} else {
kernel_h_ = pool_param.kernel_h();
kernel_w_ = pool_param.kernel_w();
}
}
CHECK_GT(kernel_h_, 0) << "Filter dimensions cannot be zero.";
CHECK_GT(kernel_w_, 0) << "Filter dimensions cannot be zero.";
// 设置pad大小
if (!pool_param.has_pad_h()) {
pad_h_ = pad_w_ = pool_param.pad();
} else {
pad_h_ = pool_param.pad_h();
pad_w_ = pool_param.pad_w();
}
// 设置stride大小
if (!pool_param.has_stride_h()) {
stride_h_ = stride_w_ = pool_param.stride();
} else {
stride_h_ = pool_param.stride_h();
stride_w_ = pool_param.stride_w();
}
// 如果是global_pooling pad只能=0,stride只能==1
if (global_pooling_) {
CHECK(pad_h_ == 0 && pad_w_ == 0 && stride_h_ == 1 && stride_w_ == 1)
<< "With Global_pooling: true; only pad = 0 and stride = 1";
}
// 当pad不等于0的时候,检查池化类型为AVE或者MAX.
if (pad_h_ != 0 || pad_w_ != 0) {
CHECK(this->layer_param_.pooling_param().pool()
== PoolingParameter_PoolMethod_AVE
|| this->layer_param_.pooling_param().pool()
== PoolingParameter_PoolMethod_MAX)
<< "Padding implemented only for average and max pooling.";
CHECK_LT(pad_h_, kernel_h_);
CHECK_LT(pad_w_, kernel_w_);
}
}
// 设置各种参数的维度,计算输出top的维度
template <typename Dtype>
void PoolingLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
// 判断输入数据的维数
CHECK_EQ(4, bottom[0]->num_axes()) << "Input must have 4 axes, "
<< "corresponding to (num, channels, height, width)";
// 设置通道数、高度、宽度
channels_ = bottom[0]->channels();
height_ = bottom[0]->height();
width_ = bottom[0]->width();
if (global_pooling_) {
kernel_h_ = bottom[0]->height();
kernel_w_ = bottom[0]->width();
}
// 计算pooling之后得到的高度和宽度
// static_cast 显示强制转换 ceil:返回大于或者等于指定表达式的最小整数
pooled_height_ = static_cast<int>(ceil(static_cast<float>(
height_ + 2 * pad_h_ - kernel_h_) / stride_h_)) + 1;
pooled_width_ = static_cast<int>(ceil(static_cast<float>(
width_ + 2 * pad_w_ - kernel_w_) / stride_w_)) + 1;
if (pad_h_ || pad_w_) {
// 存在padding的时候,确保最后一个pooling区域开始的地方是在图像内,否则去掉最后一部分
if ((pooled_height_ - 1) * stride_h_ >= height_ + pad_h_) {
--pooled_height_;
}
if ((pooled_width_ - 1) * stride_w_ >= width_ + pad_w_) {
--pooled_width_;
}
CHECK_LT((pooled_height_ - 1) * stride_h_, height_ + pad_h_);
CHECK_LT((pooled_width_ - 1) * stride_w_, width_ + pad_w_);
}
top[0]->Reshape(bottom[0]->num(), channels_, pooled_height_,
pooled_width_); // reshape输出图像的blob
if (top.size() > 1) { // 如果输出的个数大于1,则top[1]用top[0]来reshape
top[1]->ReshapeLike(*top[0]);
}
if (this->layer_param_.pooling_param().pool() ==
PoolingParameter_PoolMethod_MAX && top.size() == 1) { // 如果是最大值采样,则初始化最大值采样点索引
max_idx_.Reshape(bottom[0]->num(), channels_, pooled_height_,
pooled_width_);
}
if (this->layer_param_.pooling_param().pool() ==
PoolingParameter_PoolMethod_STOCHASTIC) { // 如果是随机采样,则初始化随机采样点索引
rand_idx_.Reshape(bottom[0]->num(), channels_, pooled_height_,
pooled_width_);
}
}
template <typename Dtype>
void PoolingLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) { // CPU正向传播
// 输入数据,只读,指针指向的对象为const,并不是指针本身
const Dtype* bottom_data = bottom[0]->cpu_data();
// 输出数据,读写
Dtype* top_data = top[0]->mutable_cpu_data();
// 输出特征的个数,N*C*H*W
const int top_count = top[0]->count();
// We'll output the mask to top[1] if it's of size >1.
// 如果top的size>1, 用top[1]来存储,额外输出一个mask
const bool use_top_mask = top.size() > 1;
int* mask = NULL; // suppress warnings about uninitalized variables
Dtype* top_mask = NULL;
// Different pooling methods. We explicitly do the switch outside the for
// loop to save time, although this results in more code.
switch (this->layer_param_.pooling_param().pool()) { // 选择不同的池化方法
case PoolingParameter_PoolMethod_MAX:
// 初始化mask
if (use_top_mask) {
top_mask = top[1]->mutable_cpu_data();
//分配空间、初始化,值为(-1)
caffe_set(top_count, Dtype(-1), top_mask);
} else {
mask = max_idx_.mutable_cpu_data();
caffe_set(top_count, -1, mask);
}
// 输出数据初始化,计算出相应的卷积区域,查找最大值
caffe_set(top_count, Dtype(-FLT_MAX), top_data);
// The main loop
for (int n = 0; n < bottom[0]->num(); ++n) {
for (int c = 0; c < channels_; ++c) {
for (int ph = 0; ph < pooled_height_; ++ph) {
for (int pw = 0; pw < pooled_width_; ++pw) {
// 要pooling的窗口start-end
int hstart = ph * stride_h_ - pad_h_;
int wstart = pw * stride_w_ - pad_w_;
int hend = min(hstart + kernel_h_, height_);
int wend = min(wstart + kernel_w_, width_);
hstart = max(hstart, 0);
wstart = max(wstart, 0);
//对每张图片来说
const int pool_index = ph * pooled_width_ + pw;
for (int h = hstart; h < hend; ++h) {
for (int w = wstart; w < wend; ++w) {
const int index = h * width_ + w;
if (bottom_data[index] > top_data[pool_index]) {
// 循环求得最大值
top_data[pool_index] = bottom_data[index];
if (use_top_mask) {
top_mask[pool_index] = static_cast<Dtype>(index);
} else {
mask[pool_index] = index;
}
}
}
}
}
}
// 计算偏移量,进入下一张图的index起始地址
bottom_data += bottom[0]->offset(0, 1);
top_data += top[0]->offset(0, 1);
if (use_top_mask) {
top_mask += top[0]->offset(0, 1);
} else {
mask += top[0]->offset(0, 1);
}
}
}
break;
case PoolingParameter_PoolMethod_AVE:
for (int i = 0; i < top_count; ++i) {
top_data[i] = 0;
}
// The main loop
for (int n = 0; n < bottom[0]->num(); ++n) {
for (int c = 0; c < channels_; ++c) {
for (int ph = 0; ph < pooled_height_; ++ph) {
for (int pw = 0; pw < pooled_width_; ++pw) {
int hstart = ph * stride_h_ - pad_h_;
int wstart = pw * stride_w_ - pad_w_;
int hend = min(hstart + kernel_h_, height_ + pad_h_);
int wend = min(wstart + kernel_w_, width_ + pad_w_);
int pool_size = (hend - hstart) * (wend - wstart);
hstart = max(hstart, 0);
wstart = max(wstart, 0);
hend = min(hend, height_);
wend = min(wend, width_);
for (int h = hstart; h < hend; ++h) {
for (int w = wstart; w < wend; ++w) {
top_data[ph * pooled_width_ + pw] += // 先求和
bottom_data[h * width_ + w];
}
}
top_data[ph * pooled_width_ + pw] /= pool_size; // 再除以个数
}
}
// compute offset
bottom_data += bottom[0]->offset(0, 1);
top_data += top[0]->offset(0, 1);
}
}
break;
case PoolingParameter_PoolMethod_STOCHASTIC:
NOT_IMPLEMENTED;
break;
default:
LOG(FATAL) << "Unknown pooling method.";
}
}
template <typename Dtype>
void PoolingLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) {
if (!propagate_down[0]) { // 判断是否需要反向传播
return;
}
const Dtype* top_diff = top[0]->cpu_diff(); // 传入误差只读
Dtype* bottom_diff = bottom[0]->mutable_cpu_diff(); // 待计算误差
// 初始化
caffe_set(bottom[0]->count(), Dtype(0), bottom_diff);
// We'll output the mask to top[1] if it's of size >1.
const bool use_top_mask = top.size() > 1;
const int* mask = NULL; // suppress warnings about uninitialized variables
const Dtype* top_mask = NULL;
switch (this->layer_param_.pooling_param().pool()) {
case PoolingParameter_PoolMethod_MAX:
// The main loop
// 初始化mask
if (use_top_mask) {
top_mask = top[1]->cpu_data();
} else {
mask = max_idx_.cpu_data();
}
for (int n = 0; n < top[0]->num(); ++n) {
for (int c = 0; c < channels_; ++c) {
for (int ph = 0; ph < pooled_height_; ++ph) {
for (int pw = 0; pw < pooled_width_; ++pw) {
// 根据index得到对应误差
const int index = ph * pooled_width_ + pw;
const int bottom_index =
use_top_mask ? top_mask[index] : mask[index]; // mask存储的是最大值的索引值
bottom_diff[bottom_index] += top_diff[index];
}
}
//计算偏移,进入下一张图片
bottom_diff += bottom[0]->offset(0, 1);
top_diff += top[0]->offset(0, 1);
if (use_top_mask) {
top_mask += top[0]->offset(0, 1);
} else {
mask += top[0]->offset(0, 1);
}
}
}
break;
case PoolingParameter_PoolMethod_AVE:
// The main loop
for (int n = 0; n < top[0]->num(); ++n) {
for (int c = 0; c < channels_; ++c) {
for (int ph = 0; ph < pooled_height_; ++ph) {
for (int pw = 0; pw < pooled_width_; ++pw) {
int hstart = ph * stride_h_ - pad_h_;
int wstart = pw * stride_w_ - pad_w_;
int hend = min(hstart + kernel_h_, height_ + pad_h_);
int wend = min(wstart + kernel_w_, width_ + pad_w_);
int pool_size = (hend - hstart) * (wend - wstart);
hstart = max(hstart, 0);
wstart = max(wstart, 0);
hend = min(hend, height_);
wend = min(wend, width_);
for (int h = hstart; h < hend; ++h) {
for (int w = wstart; w < wend; ++w) {
bottom_diff[h * width_ + w] +=
top_diff[ph * pooled_width_ + pw] / pool_size; // mean_pooling中,bottom的误差值按pooling窗口中的大小计算,从上一层进行填充后,再除窗口大小
}
}
}
}
// offset
bottom_diff += bottom[0]->offset(0, 1);
top_diff += top[0]->offset(0, 1);
}
}
break;
case PoolingParameter_PoolMethod_STOCHASTIC:
NOT_IMPLEMENTED;
break;
default:
LOG(FATAL) << "Unknown pooling method.";
}
}
#ifdef CPU_ONLY
STUB_GPU(PoolingLayer);
#endif
INSTANTIATE_CLASS(PoolingLayer);
} // namespace caffeinner_product_layer.hpp和inner_product_layer.cpp
inner_product_layer.hpp
#ifndef CAFFE_INNER_PRODUCT_LAYER_HPP_
#define CAFFE_INNER_PRODUCT_LAYER_HPP_
#include <vector>
#include "caffe/blob.hpp"
#include "caffe/layer.hpp"
#include "caffe/proto/caffe.pb.h"
namespace caffe {
template <typename Dtype>
class InnerProductLayer : public Layer<Dtype> {
public:
explicit InnerProductLayer(const LayerParameter& param)
: Layer<Dtype>(param) {}
virtual void LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual inline const char* type() const { return "InnerProduct"; }
virtual inline int ExactNumBottomBlobs() const { return 1; }
virtual inline int ExactNumTopBlobs() const { return 1; }
protected:
virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Forward_gpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom);
virtual void Backward_gpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom);
int M_; //batchsize
int K_; //输入神经元数目
int N_; //输出神经元数目
bool bias_term_;
Blob<Dtype> bias_multiplier_; // 偏置矩阵,一般是全为1的向量
bool transpose_; ///< if true, assume transposed weights
};
} // namespace caffe
#endif // CAFFE_INNER_PRODUCT_LAYER_HPP_inner_product_layer.cpp
#include <vector>
#include "caffe/filler.hpp"
#include "caffe/layers/inner_product_layer.hpp"
#include "caffe/util/math_functions.hpp"
namespace caffe {
/* LayerSetUp函数实现的功能是获取输入神经元和输出神经元的大小,然后构造权重和偏置空间,
* 并根据参数对起进行初始化赋值
*/
template <typename Dtype>
void InnerProductLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) { // 网络初始化,网络结构参数的获取
const int num_output = this->layer_param_.inner_product_param().num_output(); // 获取输出神经元个数
bias_term_ = this->layer_param_.inner_product_param().bias_term(); // bool类型,是否存在偏置项
transpose_ = this->layer_param_.inner_product_param().transpose(); // bool类型,是否对权重矩阵转置
N_ = num_output;
const int axis = bottom[0]->CanonicalAxisIndex(
this->layer_param_.inner_product_param().axis());
// Dimensions starting from "axis" are "flattened" into a single
// length K_ vector. For example, if bottom[0]'s shape is (N, C, H, W),
// and axis == 1, N inner products with dimension CHW are performed.
// K_ = C*H*W
K_ = bottom[0]->count(axis); // 轴axis为1时,K_为C*H*W,输入神经元的数目
// Check if we need to set up the weights
if (this->blobs_.size() > 0) {
LOG(INFO) << "Skipping parameter initialization";
} else {
if (bias_term_) {
this->blobs_.resize(2); // 如果有偏置,则申请两块区域
} else {
this->blobs_.resize(1); // 没有偏置,则申请权重的区域
}
// Initialize the weights
// 权值初始化
vector<int> weight_shape(2);
if (transpose_) {
weight_shape[0] = K_;
weight_shape[1] = N_;
}
else {
// 权值维数[N_,k_]
weight_shape[0] = N_;
weight_shape[1] = K_;
}
this->blobs_[0].reset(new Blob<Dtype>(weight_shape)); // 根据权重的大小,开辟内存,k_个输入神经元,N个_输出神经元
// fill the weights
shared_ptr<Filler<Dtype> > weight_filler(GetFiller<Dtype>( // shared_ptr是智能指针,作用是根据配置文件,获取权重初始化函数
this->layer_param_.inner_product_param().weight_filler()));
weight_filler->Fill(this->blobs_[0].get()); // 利用初始化函数进行权重的初始值填充
// If necessary, intiialize and fill the bias term
if (bias_term_) {
vector<int> bias_shape(1, N_);
this->blobs_[1].reset(new Blob<Dtype>(bias_shape));
shared_ptr<Filler<Dtype> > bias_filler(GetFiller<Dtype>(
this->layer_param_.inner_product_param().bias_filler()));
bias_filler->Fill(this->blobs_[1].get());
}
} // parameter initialization
// 设置每个参数是否需要反向传播
this->param_propagate_down_.resize(this->blobs_.size(), true);
}
template <typename Dtype>
void InnerProductLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
// Figure out the dimensions
const int axis = bottom[0]->CanonicalAxisIndex(
this->layer_param_.inner_product_param().axis());
const int new_K = bottom[0]->count(axis);
CHECK_EQ(K_, new_K)
<< "Input size incompatible with inner product parameters.";
// The first "axis" dimensions are independent inner products; the total
// number of these is M_, the product over these dimensions.
M_ = bottom[0]->count(0, axis); // batchsize,即偏置的数量
// The top shape will be the bottom shape with the flattened axes dropped,
// and replaced by a single axis with dimension num_output (N_).
// top_shape:[N,C,H,W]
vector<int> top_shape = bottom[0]->shape();
top_shape.resize(axis + 1); // top_shape:[N,C],二维向量.
top_shape[axis] = N_; // top_shape:[N,N_],将C向量变为N_
top[0]->Reshape(top_shape); // 设置top的形状大小
// Set up the bias multiplier
if (bias_term_) {
vector<int> bias_shape(1, M_); // 获得偏置的形状
bias_multiplier_.Reshape(bias_shape); // 为偏置矩阵开辟空间
caffe_set(M_, Dtype(1), bias_multiplier_.mutable_cpu_data()); // 为偏置矩阵赋初值全为1
}
}
template <typename Dtype>
void InnerProductLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_data = bottom[0]->cpu_data(); // 获得输入数据的指针
Dtype* top_data = top[0]->mutable_cpu_data(); // 获得输出数据的指针
const Dtype* weight = this->blobs_[0]->cpu_data(); // 获得权重数据的指针weight
caffe_cpu_gemm<Dtype>(CblasNoTrans, transpose_ ? CblasNoTrans : CblasTrans,
M_, N_, K_, (Dtype)1.,
bottom_data, weight, (Dtype)0., top_data); // 调用矩阵乘法 计算数据数据
if (bias_term_) {
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, M_, N_, 1, (Dtype)1.,
bias_multiplier_.cpu_data(),
this->blobs_[1]->cpu_data(), (Dtype)1., top_data); //矩阵加法,加上偏置
}
}
template <typename Dtype>
void InnerProductLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
if (this->param_propagate_down_[0]) { // 预训练时有可能某些layer不需要进行反向传播
const Dtype* top_diff = top[0]->cpu_diff(); // 获得输出的残差
const Dtype* bottom_data = bottom[0]->cpu_data(); // 获得输入数据
// Gradient with respect to weight
if (transpose_) {
// 1.先获得权重的增量,这个根据BP的原理,等于输入值和残差的乘积加和
// bottom_data是输入数据,是一个M*K的矩阵
// top_diff是输出的残差,是一个M*N的矩阵
// this->blobs_[0]->mutable_cpu_diff()是权重的增量,是一个K*N的矩阵
caffe_cpu_gemm<Dtype>(CblasTrans, CblasNoTrans,
K_, N_, M_,
(Dtype)1., bottom_data, top_diff,
(Dtype)1., this->blobs_[0]->mutable_cpu_diff());
} else {
caffe_cpu_gemm<Dtype>(CblasTrans, CblasNoTrans,
N_, K_, M_,
(Dtype)1., top_diff, bottom_data,
(Dtype)1., this->blobs_[0]->mutable_cpu_diff());
}
}
if (bias_term_ && this->param_propagate_down_[1]) {
const Dtype* top_diff = top[0]->cpu_diff();
// 2.然后获得偏置bias的增量,这个根据BP的原理,直接等于输出的残差
caffe_cpu_gemv<Dtype>(CblasTrans, M_, N_, (Dtype)1., top_diff,
bias_multiplier_.cpu_data(), (Dtype)1.,
this->blobs_[1]->mutable_cpu_diff());
}
if (propagate_down[0]) {
const Dtype* top_diff = top[0]->cpu_diff();
// Gradient with respect to bottom data
// 3.最后是更新输入的残差,这样才能逐层反向传递
if (transpose_) {
// 根据BP原理,输出(下一层)的残差是权重和输出(上一层)
// 残差的加权和,再乘以激活函数的导数。但是这个激活函数的
// caffe丢给了激活函数层,所以这里就不需要
// top_diff 是输出残差
// this->blobs_[0]->cpu_data()是权重
// bottom[0]->mutable_cpu_diff()便是输入的残差
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasTrans,
M_, K_, N_,
(Dtype)1., top_diff, this->blobs_[0]->cpu_data(),
(Dtype)0., bottom[0]->mutable_cpu_diff());
} else {
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans,
M_, K_, N_,
(Dtype)1., top_diff, this->blobs_[0]->cpu_data(),
(Dtype)0., bottom[0]->mutable_cpu_diff());
}
}
}
#ifdef CPU_ONLY
STUB_GPU(InnerProductLayer);
#endif
INSTANTIATE_CLASS(InnerProductLayer);
REGISTER_LAYER_CLASS(InnerProduct);
} // namespace caffeBatchNorm 和 Scale 类
batch_norm_layer.hpp 和 batch_norm_layer.cpp
batch_norm_layer.hpp
#ifndef CAFFE_BATCHNORM_LAYER_HPP_
#define CAFFE_BATCHNORM_LAYER_HPP_
#include <vector>
#include "caffe/blob.hpp"
#include "caffe/layer.hpp"
#include "caffe/proto/caffe.pb.h"
namespace caffe {
/**
* @brief Normalizes the input to have 0-mean and/or unit (1) variance across
* the batch.
*
* This layer computes Batch Normalization as described in [1]. For each channel
* in the data (i.e. axis 1), it subtracts the mean and divides by the variance,
* where both statistics are computed across both spatial dimensions and across
* the different examples in the batch.
*
* By default, during training time, the network is computing global
* mean/variance statistics via a running average, which is then used at test
* time to allow deterministic outputs for each input. You can manually toggle
* whether the network is accumulating or using the statistics via the
* use_global_stats option. For reference, these statistics are kept in the
* layer's three blobs: (0) mean, (1) variance, and (2) moving average factor.
*
* Note that the original paper also included a per-channel learned bias and
* scaling factor. To implement this in Caffe, define a `ScaleLayer` configured
* with `bias_term: true` after each `BatchNormLayer` to handle both the bias
* and scaling factor.
*
* [1] S. Ioffe and C. Szegedy, "Batch Normalization: Accelerating Deep Network
* Training by Reducing Internal Covariate Shift." arXiv preprint
* arXiv:1502.03167 (2015).
*
* TODO(dox): thorough documentation for Forward, Backward, and proto params.
*/
template <typename Dtype>
class BatchNormLayer : public Layer<Dtype> {
public:
explicit BatchNormLayer(const LayerParameter& param)
: Layer<Dtype>(param) {}
virtual void LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual inline const char* type() const { return "BatchNorm"; }
virtual inline int ExactNumBottomBlobs() const { return 1; }
virtual inline int ExactNumTopBlobs() const { return 1; }
protected:
virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Forward_gpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom);
virtual void Backward_gpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom);
Blob<Dtype> mean_, variance_, temp_, x_norm_;
bool use_global_stats_;
Dtype moving_average_fraction_;
int channels_;
Dtype eps_;
// extra temporarary variables is used to carry out sums/broadcasting
// using BLAS
Blob<Dtype> batch_sum_multiplier_;
Blob<Dtype> num_by_chans_;
Blob<Dtype> spatial_sum_multiplier_;
};
} // namespace caffe
#endif // CAFFE_BATCHNORM_LAYER_HPP_batch_norm_layer.cpp
#include <algorithm>
#include <vector>
#include "caffe/layers/batch_norm_layer.hpp"
#include "caffe/util/math_functions.hpp"
namespace caffe {
template <typename Dtype>
void BatchNormLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
BatchNormParameter param = this->layer_param_.batch_norm_param();
moving_average_fraction_ = param.moving_average_fraction();
use_global_stats_ = this->phase_ == TEST;
if (param.has_use_global_stats())
use_global_stats_ = param.use_global_stats();
if (bottom[0]->num_axes() == 1)
channels_ = 1;
else
channels_ = bottom[0]->shape(1);
eps_ = param.eps();
if (this->blobs_.size() > 0) {
LOG(INFO) << "Skipping parameter initialization";
} else {
this->blobs_.resize(3);
vector<int> sz;
sz.push_back(channels_);
this->blobs_[0].reset(new Blob<Dtype>(sz));
this->blobs_[1].reset(new Blob<Dtype>(sz));
sz[0] = 1;
this->blobs_[2].reset(new Blob<Dtype>(sz));
for (int i = 0; i < 3; ++i) {
caffe_set(this->blobs_[i]->count(), Dtype(0),
this->blobs_[i]->mutable_cpu_data());
}
}
// Mask statistics from optimization by setting local learning rates
// for mean, variance, and the bias correction to zero.
for (int i = 0; i < this->blobs_.size(); ++i) {
if (this->layer_param_.param_size() == i) {
ParamSpec* fixed_param_spec = this->layer_param_.add_param();
fixed_param_spec->set_lr_mult(0.f);
} else {
CHECK_EQ(this->layer_param_.param(i).lr_mult(), 0.f)
<< "Cannot configure batch normalization statistics as layer "
<< "parameters.";
}
}
}
template <typename Dtype>
void BatchNormLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
// 判断输入数据的维数
if (bottom[0]->num_axes() >= 1)
CHECK_EQ(bottom[0]->shape(1), channels_);
top[0]->ReshapeLike(*bottom[0]); // Reshape输出的大小
vector<int> sz;
sz.push_back(channels_);
mean_.Reshape(sz); //通道数,即channel值大小,储存的是均值
variance_.Reshape(sz); //通道数,即channel值大小,储存的是方差
temp_.ReshapeLike(*bottom[0]); // 存储的是减去mean_后的每一个数。
x_norm_.ReshapeLike(*bottom[0]); // 存储的是除以variance_后的每一个数。
sz[0] = bottom[0]->shape(0);
batch_sum_multiplier_.Reshape(sz); // batch_size 大小
int spatial_dim = bottom[0]->count()/(channels_*bottom[0]->shape(0)); // 图像height*width
/*
*spatial_sum_multiplier_是一副图像大小的空间(height*width),并初始化值为 1 ,
*作用是在计算mean_时辅助通过乘的方式将一副图像的值相加,结果是一个数值
*/
if (spatial_sum_multiplier_.num_axes() == 0 ||
spatial_sum_multiplier_.shape(0) != spatial_dim) {
sz[0] = spatial_dim;
spatial_sum_multiplier_.Reshape(sz);
Dtype* multiplier_data = spatial_sum_multiplier_.mutable_cpu_data(); // 分配一副图像空间
caffe_set(spatial_sum_multiplier_.count(), Dtype(1), multiplier_data); //初始化值为1
}
int numbychans = channels_*bottom[0]->shape(0); // batch_size*channel
if (num_by_chans_.num_axes() == 0 ||
num_by_chans_.shape(0) != numbychans) {
sz[0] = numbychans;
num_by_chans_.Reshape(sz);
// batch_sum_multiplier_ batch_size大小的空间,也是辅助在计算mean_时,将所要图像的相应的通道值相加。
caffe_set(batch_sum_multiplier_.count(), Dtype(1),
batch_sum_multiplier_.mutable_cpu_data()); //分配空间,初始化为 1,
}
}
template <typename Dtype>
void BatchNormLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = top[0]->mutable_cpu_data();
int num = bottom[0]->shape(0); // batch_size
int spatial_dim = bottom[0]->count()/(bottom[0]->shape(0)*channels_); //spatial_dim是 图像height*width
if (bottom[0] != top[0]) { //如果底层的blob与顶层的blob不是同一个blob
caffe_copy(bottom[0]->count(), bottom_data, top_data);
}
if (use_global_stats_) {
// use the stored mean/variance estimates.
const Dtype scale_factor = this->blobs_[2]->cpu_data()[0] == 0 ?
0 : 1 / this->blobs_[2]->cpu_data()[0];
caffe_cpu_scale(variance_.count(), scale_factor,
this->blobs_[0]->cpu_data(), mean_.mutable_cpu_data());
caffe_cpu_scale(variance_.count(), scale_factor,
this->blobs_[1]->cpu_data(), variance_.mutable_cpu_data());
} else {
// compute mean 计算均值
// 将每一副图像值相加为一个值,共有channels_ * num个值,然后再乘以 1/num * spatial_dim,结果存储到blob num_by_chans_中
caffe_cpu_gemv<Dtype>(CblasNoTrans, channels_ * num, spatial_dim,
1. / (num * spatial_dim), bottom_data,
spatial_sum_multiplier_.cpu_data(), 0.,
num_by_chans_.mutable_cpu_data()); // channel * num 行;spatial_dim 列,大小是height * width
// 上面计算得到的值大小是num * channel,将图像的每个通道的值相加,最后获得channel个数值,结果存储到mean_中
caffe_cpu_gemv<Dtype>(CblasTrans, num, channels_, 1.,
num_by_chans_.cpu_data(), batch_sum_multiplier_.cpu_data(), 0.,
mean_.mutable_cpu_data());
}
// subtract mean
// 将channels_个值的均值mean_矩阵扩展到num_*channels_*height*width,并用top_data数据减去均值
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num, channels_, 1, 1,
batch_sum_multiplier_.cpu_data(), mean_.cpu_data(), 0.,
num_by_chans_.mutable_cpu_data());
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, channels_ * num,
spatial_dim, 1, -1, num_by_chans_.cpu_data(),
spatial_sum_multiplier_.cpu_data(), 1., top_data);
if (!use_global_stats_) {
// compute variance using var(X) = E((X-EX)^2) 计算方差
caffe_powx(top[0]->count(), top_data, Dtype(2),
temp_.mutable_cpu_data()); // (X-EX)^2,对向量的每一个值求方差,结果存储到blob temp_中
caffe_cpu_gemv<Dtype>(CblasNoTrans, channels_ * num, spatial_dim,
1. / (num * spatial_dim), temp_.cpu_data(),
spatial_sum_multiplier_.cpu_data(), 0.,
num_by_chans_.mutable_cpu_data());
caffe_cpu_gemv<Dtype>(CblasTrans, num, channels_, 1.,
num_by_chans_.cpu_data(), batch_sum_multiplier_.cpu_data(), 0.,
variance_.mutable_cpu_data()); // E((X_EX)^2),两部运算为求均值的方法
// compute and save moving average
this->blobs_[2]->mutable_cpu_data()[0] *= moving_average_fraction_;
this->blobs_[2]->mutable_cpu_data()[0] += 1;
caffe_cpu_axpby(mean_.count(), Dtype(1), mean_.cpu_data(),
moving_average_fraction_, this->blobs_[0]->mutable_cpu_data());
int m = bottom[0]->count()/channels_;
Dtype bias_correction_factor = m > 1 ? Dtype(m)/(m-1) : 1;
caffe_cpu_axpby(variance_.count(), bias_correction_factor,
variance_.cpu_data(), moving_average_fraction_,
this->blobs_[1]->mutable_cpu_data());
}
// normalize variance
caffe_add_scalar(variance_.count(), eps_, variance_.mutable_cpu_data()); // 将 variance 每个值加一个很小的值 eps_,防止除 0的情况。
caffe_powx(variance_.count(), variance_.cpu_data(), Dtype(0.5),
variance_.mutable_cpu_data()); // 对 variance的每个值 求开方。
// replicate variance to input size
// 将channels_个值的方差variance_矩阵扩展到num_*channels_*height*width
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num, channels_, 1, 1,
batch_sum_multiplier_.cpu_data(), variance_.cpu_data(), 0.,
num_by_chans_.mutable_cpu_data());
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, channels_ * num,
spatial_dim, 1, 1., num_by_chans_.cpu_data(),
spatial_sum_multiplier_.cpu_data(), 0., temp_.mutable_cpu_data());
caffe_div(temp_.count(), top_data, temp_.cpu_data(), top_data);
// TODO(cdoersch): The caching is only needed because later in-place layers
// might clobber the data. Can we skip this if they won't?
caffe_copy(x_norm_.count(), top_data,
x_norm_.mutable_cpu_data()); // 将最后的结果 top_data 数据复制到 x_norm_中。
}
template <typename Dtype>
void BatchNormLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
const Dtype* top_diff;
if (bottom[0] != top[0]) {
top_diff = top[0]->cpu_diff();
} else {
caffe_copy(x_norm_.count(), top[0]->cpu_diff(), x_norm_.mutable_cpu_diff());
top_diff = x_norm_.cpu_diff();
}
Dtype* bottom_diff = bottom[0]->mutable_cpu_diff();
if (use_global_stats_) {
caffe_div(temp_.count(), top_diff, temp_.cpu_data(), bottom_diff);
return;
}
const Dtype* top_data = x_norm_.cpu_data();
int num = bottom[0]->shape()[0];
int spatial_dim = bottom[0]->count()/(bottom[0]->shape(0)*channels_);
// if Y = (X-mean(X))/(sqrt(var(X)+eps)), then
//
// dE(Y)/dX =
// (dE/dY - mean(dE/dY) - mean(dE/dY \cdot Y) \cdot Y)
// ./ sqrt(var(X) + eps)
//
// where \cdot and ./ are hadamard product and elementwise division,
// respectively, dE/dY is the top diff, and mean/var/sum are all computed
// along all dimensions except the channels dimension. In the above
// equation, the operations allow for expansion (i.e. broadcast) along all
// dimensions except the channels dimension where required.
// sum(dE/dY \cdot Y)
caffe_mul(temp_.count(), top_data, top_diff, bottom_diff);
caffe_cpu_gemv<Dtype>(CblasNoTrans, channels_ * num, spatial_dim, 1.,
bottom_diff, spatial_sum_multiplier_.cpu_data(), 0.,
num_by_chans_.mutable_cpu_data());
caffe_cpu_gemv<Dtype>(CblasTrans, num, channels_, 1.,
num_by_chans_.cpu_data(), batch_sum_multiplier_.cpu_data(), 0.,
mean_.mutable_cpu_data());
// reshape (broadcast) the above
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num, channels_, 1, 1,
batch_sum_multiplier_.cpu_data(), mean_.cpu_data(), 0.,
num_by_chans_.mutable_cpu_data());
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, channels_ * num,
spatial_dim, 1, 1., num_by_chans_.cpu_data(),
spatial_sum_multiplier_.cpu_data(), 0., bottom_diff);
// sum(dE/dY \cdot Y) \cdot Y
caffe_mul(temp_.count(), top_data, bottom_diff, bottom_diff);
// sum(dE/dY)-sum(dE/dY \cdot Y) \cdot Y
caffe_cpu_gemv<Dtype>(CblasNoTrans, channels_ * num, spatial_dim, 1.,
top_diff, spatial_sum_multiplier_.cpu_data(), 0.,
num_by_chans_.mutable_cpu_data());
caffe_cpu_gemv<Dtype>(CblasTrans, num, channels_, 1.,
num_by_chans_.cpu_data(), batch_sum_multiplier_.cpu_data(), 0.,
mean_.mutable_cpu_data());
// reshape (broadcast) the above to make
// sum(dE/dY)-sum(dE/dY \cdot Y) \cdot Y
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num, channels_, 1, 1,
batch_sum_multiplier_.cpu_data(), mean_.cpu_data(), 0.,
num_by_chans_.mutable_cpu_data());
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num * channels_,
spatial_dim, 1, 1., num_by_chans_.cpu_data(),
spatial_sum_multiplier_.cpu_data(), 1., bottom_diff);
// dE/dY - mean(dE/dY)-mean(dE/dY \cdot Y) \cdot Y
caffe_cpu_axpby(temp_.count(), Dtype(1), top_diff,
Dtype(-1. / (num * spatial_dim)), bottom_diff);
// note: temp_ still contains sqrt(var(X)+eps), computed during the forward
// pass.
caffe_div(temp_.count(), bottom_diff, temp_.cpu_data(), bottom_diff);
}
#ifdef CPU_ONLY
STUB_GPU(BatchNormLayer);
#endif
INSTANTIATE_CLASS(BatchNormLayer);
REGISTER_LAYER_CLASS(BatchNorm);
} // namespace caffescale_layer.hpp 和 scale_layer.cpp
scale_layer.hpp
#ifndef CAFFE_SCALE_LAYER_HPP_
#define CAFFE_SCALE_LAYER_HPP_
#include <vector>
#include "caffe/blob.hpp"
#include "caffe/layer.hpp"
#include "caffe/proto/caffe.pb.h"
#include "caffe/layers/bias_layer.hpp"
namespace caffe {
/**
* @brief Computes the elementwise product of two input Blobs, with the shape of
* the latter Blob "broadcast" to match the shape of the former.
* Equivalent to tiling the latter Blob, then computing the elementwise
* product. Note: for efficiency and convenience, this layer can
* additionally perform a "broadcast" sum too when `bias_term: true`
* is set.
*
* The latter, scale input may be omitted, in which case it's learned as
* parameter of the layer (as is the bias, if it is included).
*/
template <typename Dtype>
class ScaleLayer: public Layer<Dtype> {
public:
explicit ScaleLayer(const LayerParameter& param)
: Layer<Dtype>(param) {}
virtual void LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual inline const char* type() const { return "Scale"; }
// Scale
virtual inline int MinBottomBlobs() const { return 1; }
virtual inline int MaxBottomBlobs() const { return 2; }
virtual inline int ExactNumTopBlobs() const { return 1; }
protected:
/**
* In the below shape specifications, @f$ i @f$ denotes the value of the
* `axis` field given by `this->layer_param_.scale_param().axis()`, after
* canonicalization (i.e., conversion from negative to positive index,
* if applicable).
*
* @param bottom input Blob vector (length 2)
* -# @f$ (d_0 \times ... \times
* d_i \times ... \times d_j \times ... \times d_n) @f$
* the first factor @f$ x @f$
* -# @f$ (d_i \times ... \times d_j) @f$
* the second factor @f$ y @f$
* @param top output Blob vector (length 1)
* -# @f$ (d_0 \times ... \times
* d_i \times ... \times d_j \times ... \times d_n) @f$
* the product @f$ z = x y @f$ computed after "broadcasting" y.
* Equivalent to tiling @f$ y @f$ to have the same shape as @f$ x @f$,
* then computing the elementwise product.
*/
virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Forward_gpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom);
virtual void Backward_gpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom);
shared_ptr<Layer<Dtype> > bias_layer_;
vector<Blob<Dtype>*> bias_bottom_vec_;
vector<bool> bias_propagate_down_;
int bias_param_id_;
Blob<Dtype> sum_multiplier_;
Blob<Dtype> sum_result_;
Blob<Dtype> temp_;
int axis_;
int outer_dim_, scale_dim_, inner_dim_;
};
} // namespace caffe
#endif // CAFFE_SCALE_LAYER_HPP_scale_layer.cpp
#include <algorithm>
#include <vector>
#include "caffe/filler.hpp"
#include "caffe/layer_factory.hpp"
#include "caffe/layers/scale_layer.hpp"
#include "caffe/util/math_functions.hpp"
namespace caffe {
template <typename Dtype>
void ScaleLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const ScaleParameter& param = this->layer_param_.scale_param();
if (bottom.size() == 1 && this->blobs_.size() > 0) {
LOG(INFO) << "Skipping parameter initialization";
} else if (bottom.size() == 1) {
// scale is a learned parameter; initialize it
axis_ = bottom[0]->CanonicalAxisIndex(param.axis());
const int num_axes = param.num_axes();
CHECK_GE(num_axes, -1) << "num_axes must be non-negative, "
<< "or -1 to extend to the end of bottom[0]";
if (num_axes >= 0) {
CHECK_GE(bottom[0]->num_axes(), axis_ + num_axes)
<< "scale blob's shape extends past bottom[0]'s shape when applied "
<< "starting with bottom[0] axis = " << axis_;
}
this->blobs_.resize(1);
const vector<int>::const_iterator& shape_start =
bottom[0]->shape().begin() + axis_;
const vector<int>::const_iterator& shape_end =
(num_axes == -1) ? bottom[0]->shape().end() : (shape_start + num_axes);
vector<int> scale_shape(shape_start, shape_end);
this->blobs_[0].reset(new Blob<Dtype>(scale_shape));
FillerParameter filler_param(param.filler());
if (!param.has_filler()) {
// Default to unit (1) filler for identity operation.
filler_param.set_type("constant");
filler_param.set_value(1);
}
shared_ptr<Filler<Dtype> > filler(GetFiller<Dtype>(filler_param));
filler->Fill(this->blobs_[0].get());
}
if (param.bias_term()) {
LayerParameter layer_param(this->layer_param_);
layer_param.set_type("Bias");
BiasParameter* bias_param = layer_param.mutable_bias_param();
bias_param->set_axis(param.axis());
if (bottom.size() > 1) {
bias_param->set_num_axes(bottom[1]->num_axes());
} else {
bias_param->set_num_axes(param.num_axes());
}
bias_param->mutable_filler()->CopyFrom(param.bias_filler());
bias_layer_ = LayerRegistry<Dtype>::CreateLayer(layer_param);
bias_bottom_vec_.resize(1);
bias_bottom_vec_[0] = bottom[0];
bias_layer_->SetUp(bias_bottom_vec_, top);
if (this->blobs_.size() + bottom.size() < 3) {
// case: blobs.size == 1 && bottom.size == 1
// or blobs.size == 0 && bottom.size == 2
bias_param_id_ = this->blobs_.size();
this->blobs_.resize(bias_param_id_ + 1);
this->blobs_[bias_param_id_] = bias_layer_->blobs()[0];
} else {
// bias param already initialized
bias_param_id_ = this->blobs_.size() - 1;
bias_layer_->blobs()[0] = this->blobs_[bias_param_id_];
}
bias_propagate_down_.resize(1, false);
}
this->param_propagate_down_.resize(this->blobs_.size(), true);
}
template <typename Dtype>
void ScaleLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const ScaleParameter& param = this->layer_param_.scale_param();
Blob<Dtype>* scale = (bottom.size() > 1) ? bottom[1] : this->blobs_[0].get();
// Always set axis_ == 0 in special case where scale is a scalar
// (num_axes == 0). Mathematically equivalent for any choice of axis_, so the
// actual setting can be safely ignored; and computation is most efficient
// with axis_ == 0 and (therefore) outer_dim_ == 1. (Setting axis_ to
// bottom[0]->num_axes() - 1, giving inner_dim_ == 1, would be equally
// performant.)
axis_ = (scale->num_axes() == 0) ?
0 : bottom[0]->CanonicalAxisIndex(param.axis());
CHECK_GE(bottom[0]->num_axes(), axis_ + scale->num_axes())
<< "scale blob's shape extends past bottom[0]'s shape when applied "
<< "starting with bottom[0] axis = " << axis_;
for (int i = 0; i < scale->num_axes(); ++i) {
CHECK_EQ(bottom[0]->shape(axis_ + i), scale->shape(i))
<< "dimension mismatch between bottom[0]->shape(" << axis_ + i
<< ") and scale->shape(" << i << ")";
}
outer_dim_ = bottom[0]->count(0, axis_);
scale_dim_ = scale->count();
inner_dim_ = bottom[0]->count(axis_ + scale->num_axes());
if (bottom[0] == top[0]) { // in-place computation
temp_.ReshapeLike(*bottom[0]);
} else {
top[0]->ReshapeLike(*bottom[0]);
}
sum_result_.Reshape(vector<int>(1, outer_dim_ * scale_dim_));
const int sum_mult_size = std::max(outer_dim_, inner_dim_);
sum_multiplier_.Reshape(vector<int>(1, sum_mult_size));
if (sum_multiplier_.cpu_data()[sum_mult_size - 1] != Dtype(1)) {
caffe_set(sum_mult_size, Dtype(1), sum_multiplier_.mutable_cpu_data());
}
if (bias_layer_) {
bias_bottom_vec_[0] = top[0];
bias_layer_->Reshape(bias_bottom_vec_, top);
}
}
template <typename Dtype>
void ScaleLayer<Dtype>::Forward_cpu(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
if (bottom[0] == top[0]) {
// In-place computation; need to store bottom data before overwriting it.
// Note that this is only necessary for Backward; we could skip this if not
// doing Backward, but Caffe currently provides no way of knowing whether
// we'll need to do Backward at the time of the Forward call.
caffe_copy(bottom[0]->count(), bottom[0]->cpu_data(),
temp_.mutable_cpu_data());
}
const Dtype* scale_data =
((bottom.size() > 1) ? bottom[1] : this->blobs_[0].get())->cpu_data();
Dtype* top_data = top[0]->mutable_cpu_data();
for (int n = 0; n < outer_dim_; ++n) {
for (int d = 0; d < scale_dim_; ++d) {
const Dtype factor = scale_data[d];
caffe_cpu_scale(inner_dim_, factor, bottom_data, top_data);
bottom_data += inner_dim_;
top_data += inner_dim_;
}
}
if (bias_layer_) {
bias_layer_->Forward(bias_bottom_vec_, top);
}
}
template <typename Dtype>
void ScaleLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) {
if (bias_layer_ &&
this->param_propagate_down_[this->param_propagate_down_.size() - 1]) {
bias_layer_->Backward(top, bias_propagate_down_, bias_bottom_vec_);
}
const bool scale_param = (bottom.size() == 1);
Blob<Dtype>* scale = scale_param ? this->blobs_[0].get() : bottom[1];
if ((!scale_param && propagate_down[1]) ||
(scale_param && this->param_propagate_down_[0])) {
const Dtype* top_diff = top[0]->cpu_diff();
const bool in_place = (bottom[0] == top[0]);
const Dtype* bottom_data = (in_place ? &temp_ : bottom[0])->cpu_data();
// Hack: store big eltwise product in bottom[0] diff, except in the special
// case where this layer itself does the eltwise product, in which case we
// can store it directly in the scale diff, and we're done.
// If we're computing in-place (and not doing eltwise computation), this
// hack doesn't work and we store the product in temp_.
const bool is_eltwise = (bottom[0]->count() == scale->count());
Dtype* product = (is_eltwise ? scale->mutable_cpu_diff() :
(in_place ? temp_.mutable_cpu_data() : bottom[0]->mutable_cpu_diff()));
caffe_mul(top[0]->count(), top_diff, bottom_data, product);
if (!is_eltwise) {
Dtype* sum_result = NULL;
if (inner_dim_ == 1) {
sum_result = product;
} else if (sum_result_.count() == 1) {
const Dtype* sum_mult = sum_multiplier_.cpu_data();
Dtype* scale_diff = scale->mutable_cpu_diff();
if (scale_param) {
Dtype result = caffe_cpu_dot(inner_dim_, product, sum_mult);
*scale_diff += result;
} else {
*scale_diff = caffe_cpu_dot(inner_dim_, product, sum_mult);
}
} else {
const Dtype* sum_mult = sum_multiplier_.cpu_data();
sum_result = (outer_dim_ == 1) ?
scale->mutable_cpu_diff() : sum_result_.mutable_cpu_data();
caffe_cpu_gemv(CblasNoTrans, sum_result_.count(), inner_dim_,
Dtype(1), product, sum_mult, Dtype(0), sum_result);
}
if (outer_dim_ != 1) {
const Dtype* sum_mult = sum_multiplier_.cpu_data();
Dtype* scale_diff = scale->mutable_cpu_diff();
if (scale_dim_ == 1) {
if (scale_param) {
Dtype result = caffe_cpu_dot(outer_dim_, sum_mult, sum_result);
*scale_diff += result;
} else {
*scale_diff = caffe_cpu_dot(outer_dim_, sum_mult, sum_result);
}
} else {
caffe_cpu_gemv(CblasTrans, outer_dim_, scale_dim_,
Dtype(1), sum_result, sum_mult, Dtype(scale_param),
scale_diff);
}
}
}
}
if (propagate_down[0]) {
const Dtype* top_diff = top[0]->cpu_diff();
const Dtype* scale_data = scale->cpu_data();
Dtype* bottom_diff = bottom[0]->mutable_cpu_diff();
for (int n = 0; n < outer_dim_; ++n) {
for (int d = 0; d < scale_dim_; ++d) {
const Dtype factor = scale_data[d];
caffe_cpu_scale(inner_dim_, factor, top_diff, bottom_diff);
bottom_diff += inner_dim_;
top_diff += inner_dim_;
}
}
}
}
#ifdef CPU_ONLY
STUB_GPU(ScaleLayer);
#endif
INSTANTIATE_CLASS(ScaleLayer);
REGISTER_LAYER_CLASS(Scale);
} // namespace caffenet.hpp和net.cpp
Net是网络的搭建部分,是Layer所产生出类组合合成网络.Net用容器的形式将多个Layer有序地放在一起. 实现功能:对逐层Layer进行初始化,以及提供Updata()借口用于更新网络参数.
Net也有它自己的Forward()和Backward(),他们是对整个网络的前向和反向传导,调用可以计算出网络的loss。Net由一系列的Layer组成(无回路有向图DAG),Layer之间的连接由一个文本文件描述。模型初始化Net::Init()会产生blob和layer并调用Layer::SetUp。 在此过程中Net会报告初始化进程。
Init() 初始化函数,用于创建blobs和layers,用于调用layers的setup函数来初始化layers,并检查每一层是否需要backward
ForwardPrefilled() 用于前馈预先填满,即预先进行一次前馈。
Forward() 把网络输入层的blob读到net_input_blobs_,然后进行前馈,计 算出loss。Forward的重载,只是输入层的blob以string的格式传入。
Backward() 对整个网络进行反向传播。
Reshape() 用于改变每层的尺寸。 Update()更新params_中blob的值。
ShareTrainedLayersWith(Net* other) 从Other网络复制某些层。
CopyTrainedLayersFrom() 调用FromProto函数把源层的blob赋给目标 层的blob。
ToProto() 把网络的参数存入prototxt中。
bottom_vecs_ 存每一层的输入blob指针
bottom_id_vecs_ 存每一层输入(bottom)的id
top_vecs_ 存每一层输出(top)的blob
params_lr()和params_weight_decay() 学习速率和权重衰减;
blob_by_name() 判断是否存在名字为blob_name的blob;
FilterNet() 给定当前phase/level/stage,移除指定层。
StateMeetsRule() 中net的state是否满足NetStaterule。
AppendTop() 在网络中附加新的输入或top的blob。
AppendBottom() 在网络中附加新的输入或bottom的blob。
AppendParam() 在网络中附加新的参数blob。
GetLearningRateAndWeightDecay() 收集学习速率和权重衰减,即更新params_、params_lr_和params_weight_decay_ ;
net.hpp
#ifndef CAFFE_NET_HPP_
#define CAFFE_NET_HPP_
#include <map>
#include <set>
#include <string>
#include <utility>
#include <vector>
#include "caffe/blob.hpp"
#include "caffe/common.hpp"
#include "caffe/layer.hpp"
#include "caffe/proto/caffe.pb.h"
namespace caffe {
template <typename Dtype>
class Net {
public:
explicit Net(const NetParameter& param, const Net* root_net = NULL); // 构造函数声明成explicit就可以防止隐式转换
explicit Net(const string& param_file, Phase phase,
const Net* root_net = NULL);
// 虚析构函数是为了解决这样的一个问题:基类的指针指向派生类对象,并用基类的指针删除派生类对象。
virtual ~Net() {}
void Init(const NetParameter& param); // 从NetParameter初始化网络结构
const vector<Blob<Dtype>*>& Forward(Dtype* loss = NULL); // 前向传播并返回结果loss
const vector<Blob<Dtype>*>& ForwardPrefilled(Dtype* loss = NULL) {
LOG_EVERY_N(WARNING, 1000) << "DEPRECATED: ForwardPrefilled() "
<< "will be removed in a future version. Use Forward().";
return Forward(loss);
}
Dtype ForwardFromTo(int start, int end);
Dtype ForwardFrom(int start);
Dtype ForwardTo(int end);
const vector<Blob<Dtype>*>& Forward(const vector<Blob<Dtype>* > & bottom,
Dtype* loss = NULL);
void ClearParamDiffs(); // 对网络的diff是清零,在backward之前调用,即清空梯度
void Backward(); // 反向传播,不需要输入和输出,因为数据在前向传播的时候已经提供
void BackwardFromTo(int start, int end);
void BackwardFrom(int start);
void BackwardTo(int end);
void Reshape(); // 计算输出的尺寸
Dtype ForwardBackward() { // 进行一次正向传播,一次反向传播
Dtype loss;
Forward(&loss);
Backward();
return loss;
}
void Update(); // 更新所有可学习参数
void ShareWeights();
void ShareTrainedLayersWith(const Net* other); // 隐式的从其他网络复制pre-trained layers
void CopyTrainedLayersFrom(const NetParameter& param); // 对于一个已经初始化的网络,CopyTrainedLayersFrom()方法从另一个网络参数实例复制已经训练好的层
void CopyTrainedLayersFrom(const string trained_filename);
void CopyTrainedLayersFromBinaryProto(const string trained_filename);
void CopyTrainedLayersFromHDF5(const string trained_filename);
/// @brief Writes the net to a proto.
void ToProto(NetParameter* param, bool write_diff = false) const;
/// @brief Writes the net to an HDF5 file.
void ToHDF5(const string& filename, bool write_diff = false) const;
/// @brief returns the network name.
/// 返回网络的名字
inline const string& name() const { return name_; }
/// @brief returns the layer names
/// 返回每层的姓名
inline const vector<string>& layer_names() const { return layer_names_; }
/// @brief returns the blob names
/// 返回blob的姓名
inline const vector<string>& blob_names() const { return blob_names_; }
/// @brief returns the blobs
inline const vector<shared_ptr<Blob<Dtype> > >& blobs() const {
return blobs_;
}
/// @brief returns the layers
inline const vector<shared_ptr<Layer<Dtype> > >& layers() const {
return layers_;
}
/// @brief returns the phase: TRAIN or TEST
inline Phase phase() const { return phase_; }
/**
* @brief returns the bottom vecs for each layer -- usually you won't
* need this unless you do per-layer checks such as gradients.
*/
inline const vector<vector<Blob<Dtype>*> >& bottom_vecs() const {
return bottom_vecs_;
}
/**
* @brief returns the top vecs for each layer -- usually you won't
* need this unless you do per-layer checks such as gradients.
*/
inline const vector<vector<Blob<Dtype>*> >& top_vecs() const {
return top_vecs_;
}
/// @brief returns the ids of the top blobs of layer i
/// 返回指定层的top blobs
inline const vector<int> & top_ids(int i) const {
CHECK_GE(i, 0) << "Invalid layer id";
CHECK_LT(i, top_id_vecs_.size()) << "Invalid layer id";
return top_id_vecs_[i];
}
/// @brief returns the ids of the bottom blobs of layer i
/// 返回指定层的底层blobs
inline const vector<int> & bottom_ids(int i) const {
CHECK_GE(i, 0) << "Invalid layer id";
CHECK_LT(i, bottom_id_vecs_.size()) << "Invalid layer id";
return bottom_id_vecs_[i];
}
inline const vector<vector<bool> >& bottom_need_backward() const {
return bottom_need_backward_;
}
inline const vector<Dtype>& blob_loss_weights() const {
return blob_loss_weights_;
}
inline const vector<bool>& layer_need_backward() const {
return layer_need_backward_;
}
/// @brief returns the parameters
inline const vector<shared_ptr<Blob<Dtype> > >& params() const {
return params_;
}
inline const vector<Blob<Dtype>*>& learnable_params() const {
return learnable_params_;
}
/// @brief returns the learnable parameter learning rate multipliers
inline const vector<float>& params_lr() const { return params_lr_; }
inline const vector<bool>& has_params_lr() const { return has_params_lr_; }
/// @brief returns the learnable parameter decay multipliers
inline const vector<float>& params_weight_decay() const {
return params_weight_decay_;
}
inline const vector<bool>& has_params_decay() const {
return has_params_decay_;
}
const map<string, int>& param_names_index() const {
return param_names_index_;
}
inline const vector<int>& param_owners() const { return param_owners_; }
inline const vector<string>& param_display_names() const {
return param_display_names_;
}
/// @brief Input and output blob numbers
/// 返回输入输出blobs的个数
inline int num_inputs() const { return net_input_blobs_.size(); }
inline int num_outputs() const { return net_output_blobs_.size(); }
/// 返回输入输出的blobs
inline const vector<Blob<Dtype>*>& input_blobs() const {
return net_input_blobs_;
}
inline const vector<Blob<Dtype>*>& output_blobs() const {
return net_output_blobs_;
}
inline const vector<int>& input_blob_indices() const {
return net_input_blob_indices_;
}
inline const vector<int>& output_blob_indices() const {
return net_output_blob_indices_;
}
/// 判断是否存在某个blob
bool has_blob(const string& blob_name) const;
/// 根据blob名称返回blob值
const shared_ptr<Blob<Dtype> > blob_by_name(const string& blob_name) const;
/// 判断是否存在某层
bool has_layer(const string& layer_name) const;
const shared_ptr<Layer<Dtype> > layer_by_name(const string& layer_name) const;
void set_debug_info(const bool value) { debug_info_ = value; }
static void FilterNet(const NetParameter& param,
NetParameter* param_filtered); // 根据当前状态,去掉某些不需要的层,比如测试时的dropout
/*
使用NetStateRule的好处就是可以灵活的搭建网络,可以只写一个网络定义文件,用不同的NetState产生所需要的网络,比如常用的那个train和test的网络就可以写在一起。 加上level和stage,用法就更灵活,这里可以发挥想象力了,举个例子,如下定义的网络经过初始化以后'innerprod'层就被踢出去了
state: { level: 2 }
name: 'example'
layer {
name: 'data'
type: 'Data'
top: 'data'
top: 'label'
}
layer {
name: 'innerprod'
type: 'InnerProduct'
bottom: 'data'
top: 'innerprod'
include: { min_level: 3 }
}
layer {
name: 'loss'
type: 'SoftmaxWithLoss'
bottom: 'innerprod'
bottom: 'label'
}
*/
static bool StateMeetsRule(const NetState& state, const NetStateRule& rule,
const string& layer_name);
protected:
// Helpers for Init.
/// @brief Append a new top blob to the net.
void AppendTop(const NetParameter& param, const int layer_id,
const int top_id, set<string>* available_blobs,
map<string, int>* blob_name_to_idx);
/// @brief Append a new bottom blob to the net.
int AppendBottom(const NetParameter& param, const int layer_id,
const int bottom_id, set<string>* available_blobs,
map<string, int>* blob_name_to_idx);
/// @brief Append a new parameter blob to the net.
void AppendParam(const NetParameter& param, const int layer_id,
const int param_id);
/// @brief Helper for displaying debug info in Forward.
void ForwardDebugInfo(const int layer_id);
/// @brief Helper for displaying debug info in Backward.
void BackwardDebugInfo(const int layer_id);
/// @brief Helper for displaying debug info in Update.
void UpdateDebugInfo(const int param_id);
string name_; // 网络名称
Phase phase_; // 测试还是训练
vector<shared_ptr<Layer<Dtype> > > layers_; // Layer容器
vector<string> layer_names_; // 每层layer的名称
map<string, int> layer_names_index_; // 关联容器,layer名称所对应的索引
vector<bool> layer_need_backward_; // 每层layer是否需要计算反向传导
// blobs_存储的是中间结果,是针对整个网络中所有非参数blob而设计的一个变量。
vector<shared_ptr<Blob<Dtype> > > blobs_;
vector<string> blob_names_; // 整个网络中,所有非参数blob的name
map<string, int> blob_names_index_; // blob 名称索引键值对
vector<bool> blob_need_backward_; // 整个网络中,所有非参数blob,是否需要backward。注意,这里所说的所有非参数blob其实指的是AppendTop函数中遍历的所有top blob,并不是每一层的top+bottom,因为这一层的top就是下一层的bottom,网络是一层一层堆起来的
vector<vector<Blob<Dtype>*>> bottom_vecs_; // 存储整个网络所有网络层的bottom blob指针,实际上存储的是前一层的top,因为网络是一层一层堆起来的
vector<vector<int> > bottom_id_vecs_; // 存储整个网络所有网络层的bottom_blob的ID
vector<vector<bool> > bottom_need_backward_; // 整个网络所有网络层的bottom_blob是否需要backward
vector<vector<Blob<Dtype>*> > top_vecs_; // 存储整个网络所有网络层的top blob指针
vector<vector<int> > top_id_vecs_; // 存储整个网络所有网络层的top_blob的ID.top_id_vecs_中存储的最基本元素是blob_id:每一个新的blob都会赋予其一个blob_id,top_vecs_则与之对应,但是这个blob_id可能是会有重复的(因为in-place)
vector<Dtype> blob_loss_weights_; // 每次遍历一个layer的时候,都会resize blob_loss_weights_, 然后调用模板类layer的loss函数返回loss_weight
vector<vector<int> > param_id_vecs_; // 存储每层的可学习参数id
vector<int> param_owners_; // 表示参数所属的layer在layers_中的位置
vector<string> param_display_names_;
vector<pair<int, int> > param_layer_indices_; // 其元素为当layer_id 与当前param_id 组成的pair.vector<pair<int, int> > param_layer_indices_
是整个网络的参数non-empty name与index的映射。注意,这个name是ParamSpec 类型中的name。
map<string, int> param_names_index_;
vector<int> net_input_blob_indices_; // 整个网络的输入输出blob以及ID
vector<int> net_output_blob_indices_;
vector<Blob<Dtype>*> net_input_blobs_; // 网络输入输出的所有blob
vector<Blob<Dtype>*> net_output_blobs_;
/// The parameters in the network.
// 网络中的所有参数
// 整个网络的参数blob。 !!!不管这个参数有没有non-emty name,是否参与share!!!
vector<shared_ptr<Blob<Dtype> > > params_;
vector<Blob<Dtype>*> learnable_params_;
vector<int> learnable_param_ids_;
vector<float> params_lr_; // 学习率
vector<bool> has_params_lr_; // 是否存在学习率
vector<float> params_weight_decay_; // 权重衰减
vector<bool> has_params_decay_;
size_t memory_used_; // 存储网络所用的字节数
bool debug_info_;
const Net* const root_net_;
DISABLE_COPY_AND_ASSIGN(Net);
};
} // namespace caffe
#endif // CAFFE_NET_HPP_net.cpp
#include <algorithm>
#include <map>
#include <set>
#include <string>
#include <utility>
#include <vector>
#include "hdf5.h"
#include "caffe/common.hpp"
#include "caffe/layer.hpp"
#include "caffe/net.hpp"
#include "caffe/parallel.hpp"
#include "caffe/proto/caffe.pb.h"
#include "caffe/util/hdf5.hpp"
#include "caffe/util/insert_splits.hpp"
#include "caffe/util/math_functions.hpp"
#include "caffe/util/upgrade_proto.hpp"
#include "caffe/test/test_caffe_main.hpp"
namespace caffe {
template <typename Dtype>
Net<Dtype>::Net(const NetParameter& param, const Net* root_net)
: root_net_(root_net) { // Net的构造函数,调用Init函数初始化网络
Init(param);
}
template <typename Dtype>
Net<Dtype>::Net(const string& param_file, Phase phase, const Net* root_net)
: root_net_(root_net) { // Net的构造函数,调用Init函数初始化网络
NetParameter param;
ReadNetParamsFromTextFileOrDie(param_file, ¶m);
param.mutable_state()->set_phase(phase);
Init(param);
}
// 网络结构初始化,通过Net的构造函数调用
template <typename Dtype>
void Net<Dtype>::Init(const NetParameter& in_param) {
CHECK(Caffe::root_solver() || root_net_)
<< "root_net_ needs to be set for all non-root solvers";
phase_ = in_param.state().phase(); // 得到是训练网络还是测试网络
NetParameter filtered_param;
FilterNet(in_param, &filtered_param); // 传入网络结构参数,然后可以根据LayerParameter中的include和exclude来确定该层是否应该包含在网络中,返回过滤过后的网络参数
LOG_IF(INFO, Caffe::root_solver())
<< "Initializing net from parameters: " << std::endl
<< filtered_param.DebugString();
NetParameter param;
InsertSplits(filtered_param, ¶m); // InsertSplits函数,若某层的top(即输出)被两个或两个以上的层作为输入或输入的一部分,则对该层增加空间位置与其成并列关系的一个或若干个SplitLayer。
name_ = param.name();
map<string, int> blob_name_to_idx;
LOG(INFO) << " -> " <<" "<<(blob_name_to_idx).size()<<"heheda";
set<string> available_blobs;
memory_used_ = 0;
// For each layer, set up its input and output
// resize是改变容器的大小,并且使用默认构造函数创建对象,初始化对象,param.layers_size()表示网络的总层数
bottom_vecs_.resize(param.layer_size());
top_vecs_.resize(param.layer_size());
bottom_id_vecs_.resize(param.layer_size());
param_id_vecs_.resize(param.layer_size());
top_id_vecs_.resize(param.layer_size());
bottom_need_backward_.resize(param.layer_size());
// 循环每一层
for (int layer_id = 0; layer_id < param.layer_size(); ++layer_id) {
bool share_from_root = !Caffe::root_solver()
&& root_net_->layers_[layer_id]->ShareInParallel();
if (!param.layer(layer_id).has_phase()) { // 如果每一层没有设置phase,则从网络参数中继承
param.mutable_layer(layer_id)->set_phase(phase_);
}
// Setup layer.
const LayerParameter& layer_param = param.layer(layer_id); // 每一层的结构参数常量,返回每一层的参数
// 是否设置了对输入求导,参考caffe.proto里LayerParameter的propagate_down参数
if (layer_param.propagate_down_size() > 0) {
CHECK_EQ(layer_param.propagate_down_size(),
layer_param.bottom_size())
<< "propagate_down param must be specified "
<< "either 0 or bottom_size times ";
}
if (share_from_root) {
LOG(INFO) << "Sharing layer " << layer_param.name() << " from root net";
layers_.push_back(root_net_->layers_[layer_id]);
layers_[layer_id]->SetShared(true);
}
else {
// 把每一特定层的指针存放在容器中
layers_.push_back(LayerRegistry<Dtype>::CreateLayer(layer_param));
}
// 存放网络中每一层的名称
layer_names_.push_back(layer_param.name());
LOG_IF(INFO, Caffe::root_solver())
<< "Creating Layer " << layer_param.name();
// 判断每层是否需要反向传播
bool need_backward = false;
// Figure out this layer's input and output
// 计算这一层的输入和输出,注意第一层没有输出bottom,所以在第一层的时候并不会进入循环
for (int bottom_id = 0; bottom_id < layer_param.bottom_size();
++bottom_id) {
const int blob_id = AppendBottom(param, layer_id, bottom_id,
&available_blobs, &blob_name_to_idx);
need_backward |= blob_need_backward_[blob_id];
}
// 每一层输出数据的个数
int num_top = layer_param.top_size();
// 对每层的每个输出数据
for (int top_id = 0; top_id < num_top; ++top_id) {
AppendTop(param, layer_id, top_id, &available_blobs, &blob_name_to_idx);
if (layer_param.type() == "Input") {
const int blob_id = blobs_.size() - 1;
net_input_blob_indices_.push_back(blob_id);
net_input_blobs_.push_back(blobs_[blob_id].get());
}
}
// If the layer specifies that AutoTopBlobs() -> true and the LayerParameter
// specified fewer than the required number (as specified by
// ExactNumTopBlobs() or MinTopBlobs()), allocate them here.
Layer<Dtype>* layer = layers_[layer_id].get();
if (layer->AutoTopBlobs()) {
const int needed_num_top =
std::max(layer->MinTopBlobs(), layer->ExactNumTopBlobs());
for (; num_top < needed_num_top; ++num_top) {
// Add "anonymous" top blobs -- do not modify available_blobs or
// blob_name_to_idx as we don't want these blobs to be usable as input
// to other layers.
AppendTop(param, layer_id, num_top, NULL, NULL);
}
}
// After this layer is connected, set it up.
if (share_from_root) {
// Set up size of top blobs using root_net_
const vector<Blob<Dtype>*>& base_top = root_net_->top_vecs_[layer_id];
const vector<Blob<Dtype>*>& this_top = this->top_vecs_[layer_id];
for (int top_id = 0; top_id < base_top.size(); ++top_id) {
this_top[top_id]->ReshapeLike(*base_top[top_id]);
LOG(INFO) << "Created top blob " << top_id << " (shape: "
<< this_top[top_id]->shape_string() << ") for shared layer "
<< layer_param.name();
}
}
else {
// 设置layers实例
// 调用layer类的Setup函数进行初始化,输入参数:每个layer的输入blobs以及输出blobs
// 为每个blob设置大小
// 设置每一层的可学习参数,保存在layer的成员blobs_中
layers_[layer_id]->SetUp(bottom_vecs_[layer_id], top_vecs_[layer_id]);
}
LOG_IF(INFO, Caffe::root_solver())
<< "Setting up " << layer_names_[layer_id];
// 对每一层的输出blobs循环
for (int top_id = 0; top_id < top_vecs_[layer_id].size(); ++top_id) {
if (blob_loss_weights_.size() <= top_id_vecs_[layer_id][top_id]) {
blob_loss_weights_.resize(top_id_vecs_[layer_id][top_id] + 1, Dtype(0));
}
blob_loss_weights_[top_id_vecs_[layer_id][top_id]] = layer->loss(top_id);
LOG_IF(INFO, Caffe::root_solver())
<< "Top shape: " << top_vecs_[layer_id][top_id]->shape_string();
if (layer->loss(top_id)) {
LOG_IF(INFO, Caffe::root_solver())
<< " with loss weight " << layer->loss(top_id);
}
// 计算网络所使用的字节数
memory_used_ += top_vecs_[layer_id][top_id]->count();
}
// 打印目前所需的存储
LOG_IF(INFO, Caffe::root_solver())
<< "Memory required for data: " << memory_used_ * sizeof(Dtype);
// param通常用来设置学习率之类的参数,每层的param有多少个则说明至少有这么多个
// 可学习参数
const int param_size = layer_param.param_size();
//可学习参数个数
const int num_param_blobs = layers_[layer_id]->blobs().size();
CHECK_LE(param_size, num_param_blobs)
<< "Too many params specified for layer " << layer_param.name();
ParamSpec default_param_spec;
// 对每一个可学习的参数循环
for (int param_id = 0; param_id < num_param_blobs; ++param_id) {
// 如果prototxt文件没有设置param,则使用默认param
const ParamSpec* param_spec = (param_id < param_size) ?
&layer_param.param(param_id) : &default_param_spec;
// 学习率不等于0,表示需要对这个可学习的参数反向求导
const bool param_need_backward = param_spec->lr_mult() != 0;
need_backward |= param_need_backward;
layers_[layer_id]->set_param_propagate_down(param_id,
param_need_backward);
}
// 接下来的工作是将每层的parameter的指针塞进params_,尤其是learnable_params_。
// 对每一层的每个可学习参数循环
for (int param_id = 0; param_id < num_param_blobs; ++param_id) {
// param:整个网络参数,layer_id:层数id,param_id:可学习参数id
// 设置每一层权值的一些参数,学习率,正则率,参数id等
AppendParam(param, layer_id, param_id);
}
// Finally, set the backward flag
// 最后设置反向传播标志
layer_need_backward_.push_back(need_backward);
if (need_backward) {
for (int top_id = 0; top_id < top_id_vecs_[layer_id].size(); ++top_id) {
blob_need_backward_[top_id_vecs_[layer_id][top_id]] = true;
}
}
}
// 每一层的循环在这里结束
// 寻找反向传播过程中哪些blobs对最终的loss有影响,如果某个blob对最终的loss没有贡献,
// 则不需要对这个blob求梯度,还要检查是否所有的bottom blobs都不需要求梯度
set<string> blobs_under_loss;
set<string> blobs_skip_backp;
// 对每一层从后向前循环
for (int layer_id = layers_.size() - 1; layer_id >= 0; --layer_id) {
bool layer_contributes_loss = false;
bool layer_skip_propagate_down = true;
// 对每一层的每个top blob循环
for (int top_id = 0; top_id < top_vecs_[layer_id].size(); ++top_id) {
const string& blob_name = blob_names_[top_id_vecs_[layer_id][top_id]];
if (layers_[layer_id]->loss(top_id) ||
(blobs_under_loss.find(blob_name) != blobs_under_loss.end())) {
layer_contributes_loss = true;
}
if (blobs_skip_backp.find(blob_name) == blobs_skip_backp.end()) {
layer_skip_propagate_down = false;
}
// 只要这一层有一个blob对loss有贡献,就说明这层对loss有贡献
if (layer_contributes_loss && !layer_skip_propagate_down)
break;
}
// 如果这一层跳过梯度计算,那么这一层所有的输入blobs都不需要计算梯度
if (layer_need_backward_[layer_id] && layer_skip_propagate_down) {
layer_need_backward_[layer_id] = false;
for (int bottom_id = 0; bottom_id < bottom_vecs_[layer_id].size();
++bottom_id) {
bottom_need_backward_[layer_id][bottom_id] = false;
}
}
if (!layer_contributes_loss) { layer_need_backward_[layer_id] = false; }
if (Caffe::root_solver()) {
if (layer_need_backward_[layer_id]) {
LOG(INFO) << layer_names_[layer_id] << " needs backward computation.";
}
else {
LOG(INFO) << layer_names_[layer_id]
<< " does not need backward computation.";
}
}
for (int bottom_id = 0; bottom_id < bottom_vecs_[layer_id].size();
++bottom_id) {
if (layer_contributes_loss) {
const string& blob_name =
blob_names_[bottom_id_vecs_[layer_id][bottom_id]];
blobs_under_loss.insert(blob_name);
}
else {
bottom_need_backward_[layer_id][bottom_id] = false;
}
if (!bottom_need_backward_[layer_id][bottom_id]) {
const string& blob_name =
blob_names_[bottom_id_vecs_[layer_id][bottom_id]];
blobs_skip_backp.insert(blob_name);
}
}
}
// 从后向前循环结束
// Handle force_backward if needed.
// 如果设置强制计算梯度
if (param.force_backward()) {
for (int layer_id = 0; layer_id < layers_.size(); ++layer_id) {
layer_need_backward_[layer_id] = true;
for (int bottom_id = 0;
bottom_id < bottom_need_backward_[layer_id].size(); ++bottom_id) {
bottom_need_backward_[layer_id][bottom_id] =
bottom_need_backward_[layer_id][bottom_id] ||
layers_[layer_id]->AllowForceBackward(bottom_id);
blob_need_backward_[bottom_id_vecs_[layer_id][bottom_id]] =
blob_need_backward_[bottom_id_vecs_[layer_id][bottom_id]] ||
bottom_need_backward_[layer_id][bottom_id];
}
for (int param_id = 0; param_id < layers_[layer_id]->blobs().size();
++param_id) {
layers_[layer_id]->set_param_propagate_down(param_id, true);
}
}
}
// 最后,输入输出blob中除了输入blob剩下的都作为网络的输出,比如loss blob
for (set<string>::iterator it = available_blobs.begin();
it != available_blobs.end(); ++it) {
LOG_IF(INFO, Caffe::root_solver())
<< "This network produces output " << *it;
net_output_blobs_.push_back(blobs_[blob_name_to_idx[*it]].get());
net_output_blob_indices_.push_back(blob_name_to_idx[*it]);
}
for (size_t blob_id = 0; blob_id < blob_names_.size(); ++blob_id) {
blob_names_index_[blob_names_[blob_id]] = blob_id;
}
for (size_t layer_id = 0; layer_id < layer_names_.size(); ++layer_id) {
layer_names_index_[layer_names_[layer_id]] = layer_id;
}
ShareWeights();
debug_info_ = param.debug_info();
LOG_IF(INFO, Caffe::root_solver()) << "Network initialization done.";
}
// Helper for Net::Init: add a new top blob to the net.
template <typename Dtype>
void Net<Dtype>::AppendTop(const NetParameter& param, const int layer_id,
const int top_id, set<string>* available_blobs,
map<string, int>* blob_name_to_idx) {
shared_ptr<LayerParameter> layer_param(
new LayerParameter(param.layer(layer_id))); // 加载新的层参数
const string& blob_name = (layer_param->top_size() > top_id) ?
layer_param->top(top_id) : "(automatic)"; // 每个输出blob的名称
// Check if we are doing in-place computation
// 检查是否为同址计算(in-place computation,返回值覆盖原值而不占用新的内存)。
// (比如Dropout运算,激活函数ReLu,Sigmoid等),其中输入bolb的名称和输出相同
if (blob_name_to_idx && layer_param->bottom_size() > top_id &&
blob_name == layer_param->bottom(top_id)) {
// In-place computation
LOG_IF(INFO, Caffe::root_solver())
<< layer_param->name() << " -> " << blob_name << " (in-place)";
// get获取拥有的资源的地址。
top_vecs_[layer_id].push_back(blobs_[(*blob_name_to_idx)[blob_name]].get());
top_id_vecs_[layer_id].push_back((*blob_name_to_idx)[blob_name]);
}
else if (blob_name_to_idx &&
blob_name_to_idx->find(blob_name) != blob_name_to_idx->end()) {
// If we are not doing in-place computation but have duplicated blobs,
// raise an error.
LOG(FATAL) << "Top blob '" << blob_name
<< "' produced by multiple sources.";
}
else {
// Normal output.
if (Caffe::root_solver()) {
LOG(INFO) << layer_param->name() << " -> " << blob_name;
}
// 数据指针
shared_ptr<Blob<Dtype> > blob_pointer(new Blob<Dtype>());
// blobs只是存储中间结果;每次遍历到一个top blob都会更新blob_id
const int blob_id = blobs_.size();
blobs_.push_back(blob_pointer);
blob_names_.push_back(blob_name);
blob_need_backward_.push_back(false);
// blob_name_to_idx是一个局部变量,其实它是在当前layer的top blob 和下一层的bottom blob间起着一个桥梁作用。
// blob_name_to_idx中元素的pair是从网络最开始一层一层搭建的过程中压入map的,其中的name和id都是不重复的。name是关键字——不重复是map数据结构的必然要求,id也是不重复的——0,1,2...
// blob_name_to_idx和blobs_一样,在"Normal output"的情形下,每次遍历到一个top blob的时候都会更新
// 添加新元素-->map可以通过下标访问符为(关联)容器添加新元素
if (blob_name_to_idx) {
(*blob_name_to_idx)[blob_name] = blob_id; }
top_id_vecs_[layer_id].push_back(blob_id);
top_vecs_[layer_id].push_back(blob_pointer.get());
}
if (available_blobs) { available_blobs->insert(blob_name); }
}
// Helper for Net::Init: add a new bottom blob to the net.
//
template <typename Dtype>
int Net<Dtype>::AppendBottom(const NetParameter& param, const int layer_id,
const int bottom_id, set<string>* available_blobs,
map<string, int>* blob_name_to_idx) {
//得到这一层的参数
const LayerParameter& layer_param = param.layer(layer_id);
//得到输入bottom的名称
const string& blob_name = layer_param.bottom(bottom_id);
if (available_blobs->find(blob_name) == available_blobs->end()) {
LOG(FATAL) << "Unknown bottom blob '" << blob_name << "' (layer '"
<< layer_param.name() << "', bottom index " << bottom_id << ")";
}
// blob_name_to_idx是一个map,其关键字是不重复的。blob_name_to_idx
LOG(INFO) << " -> " << blob_name<<" "<<(*blob_name_to_idx).size()<<"heheda";
const int blob_id = (*blob_name_to_idx)[blob_name];
LOG(INFO) << " -> " << blob_name<<" "<<blob_id<<(*blob_name_to_idx).size()<<"heheda";
//
LOG_IF(INFO, Caffe::root_solver())
<< layer_names_[layer_id] << " <- " << blob_name;
bottom_vecs_[layer_id].push_back(blobs_[blob_id].get());
bottom_id_vecs_[layer_id].push_back(blob_id);
available_blobs->erase(blob_name);
bool need_backward = blob_need_backward_[blob_id];
// Check if the backpropagation on bottom_id should be skipped
if (layer_param.propagate_down_size() > 0) {
need_backward = layer_param.propagate_down(bottom_id);
}
bottom_need_backward_[layer_id].push_back(need_backward);
return blob_id;
}
template <typename Dtype>
void Net<Dtype>::AppendParam(const NetParameter& param, const int layer_id,
const int param_id) {
const LayerParameter& layer_param = layers_[layer_id]->layer_param();
const int param_size = layer_param.param_size();
string param_name =
(param_size > param_id) ? layer_param.param(param_id).name() : "";
if (param_name.size()) {
param_display_names_.push_back(param_name);
} else {
ostringstream param_display_name;
param_display_name << param_id;
param_display_names_.push_back(param_display_name.str());
}
const int net_param_id = params_.size();
// 存放每个可学习参数
params_.push_back(layers_[layer_id]->blobs()[param_id]);
param_id_vecs_[layer_id].push_back(net_param_id);
// pair实质上是一个结构体,其主要的两个成员变量是first和second,这两个变量可以直接使用。
// 初始化一个pair可以使用构造函数,也可以使用std::make_pair函数,
param_layer_indices_.push_back(make_pair(layer_id, param_id));
ParamSpec default_param_spec;
const ParamSpec* param_spec = (layer_param.param_size() > param_id) ?
&layer_param.param(param_id) : &default_param_spec;
if (!param_size || !param_name.size() || (param_name.size() &&
param_names_index_.find(param_name) == param_names_index_.end())) {
// This layer "owns" this parameter blob -- it is either anonymous
// (i.e., not given a param_name) or explicitly given a name that we
// haven't already seen.
//
param_owners_.push_back(-1);
if (param_name.size()) {
param_names_index_[param_name] = net_param_id;
}
const int learnable_param_id = learnable_params_.size();
// 智能指针转换为普通指针,Why?
learnable_params_.push_back(params_[net_param_id].get());
learnable_param_ids_.push_back(learnable_param_id);
has_params_lr_.push_back(param_spec->has_lr_mult());
has_params_decay_.push_back(param_spec->has_decay_mult());
params_lr_.push_back(param_spec->lr_mult());
params_weight_decay_.push_back(param_spec->decay_mult());
}
// else直到结束,一般不会执行这一部分,共享网络如siamese model会执行
else
{
// Named param blob with name we've seen before: share params
const int owner_net_param_id = param_names_index_[param_name];
param_owners_.push_back(owner_net_param_id);
const pair<int, int>& owner_index =
param_layer_indices_[owner_net_param_id];
const int owner_layer_id = owner_index.first;
const int owner_param_id = owner_index.second;
LOG_IF(INFO, Caffe::root_solver()) << "Sharing parameters '" << param_name
<< "' owned by "
<< "layer '" << layer_names_[owner_layer_id] << "', param "
<< "index " << owner_param_id;
Blob<Dtype>* this_blob = layers_[layer_id]->blobs()[param_id].get();
Blob<Dtype>* owner_blob =
layers_[owner_layer_id]->blobs()[owner_param_id].get();
const int param_size = layer_param.param_size();
if (param_size > param_id && (layer_param.param(param_id).share_mode() ==
ParamSpec_DimCheckMode_PERMISSIVE)) {
// Permissive dimension checking -- only check counts are the same.
CHECK_EQ(this_blob->count(), owner_blob->count())
<< "Cannot share param '" << param_name << "' owned by layer '"
<< layer_names_[owner_layer_id] << "' with layer '"
<< layer_names_[layer_id] << "'; count mismatch. Owner layer param "
<< "shape is " << owner_blob->shape_string() << "; sharing layer "
<< "shape is " << this_blob->shape_string();
} else {
// Strict dimension checking -- all dims must be the same.
CHECK(this_blob->shape() == owner_blob->shape())
<< "Cannot share param '" << param_name << "' owned by layer '"
<< layer_names_[owner_layer_id] << "' with layer '"
<< layer_names_[layer_id] << "'; shape mismatch. Owner layer param "
<< "shape is " << owner_blob->shape_string() << "; sharing layer "
<< "expects shape " << this_blob->shape_string();
}
const int learnable_param_id = learnable_param_ids_[owner_net_param_id];
learnable_param_ids_.push_back(learnable_param_id);
if (param_spec->has_lr_mult()) {
if (has_params_lr_[learnable_param_id]) {
CHECK_EQ(param_spec->lr_mult(), params_lr_[learnable_param_id])
<< "Shared param '" << param_name << "' has mismatched lr_mult.";
} else {
has_params_lr_[learnable_param_id] = true;
params_lr_[learnable_param_id] = param_spec->lr_mult();
}
}
if (param_spec->has_decay_mult()) {
if (has_params_decay_[learnable_param_id]) {
CHECK_EQ(param_spec->decay_mult(),
params_weight_decay_[learnable_param_id])
<< "Shared param '" << param_name << "' has mismatched decay_mult.";
} else {
has_params_decay_[learnable_param_id] = true;
params_weight_decay_[learnable_param_id] = param_spec->decay_mult();
}
}
}
}
// 与前向传播相关的函数有Forward(const vector<Blob<Dtype>*> & bottom, Dtype* loss),
// Forward(Dtype* loss),ForwardTo(int end),ForwardFrom(int start)和
// ForwardFromTo(int start, int end),前面的四个函数都是对第五个函数封装
template <typename Dtype>
Dtype Net<Dtype>::ForwardFromTo(int start, int end) {
CHECK_GE(start, 0);
CHECK_LT(end, layers_.size());
Dtype loss = 0;
for (int i = start; i <= end; ++i) {
// LOG(ERROR) << "Forwarding " << layer_names_[i];
// 对每一层进行前向计算,返回每层的loss,其实只有最后一层loss不为0
Dtype layer_loss = layers_[i]->Forward(bottom_vecs_[i], top_vecs_[i]);
loss += layer_loss;
if (debug_info_) { ForwardDebugInfo(i); }
}
return loss;
}
template <typename Dtype>
Dtype Net<Dtype>::ForwardFrom(int start) {
return ForwardFromTo(start, layers_.size() - 1);
}
template <typename Dtype>
Dtype Net<Dtype>::ForwardTo(int end) {
return ForwardFromTo(0, end);
}
// 前向传播
template <typename Dtype>
const vector<Blob<Dtype>*>& Net<Dtype>::Forward(Dtype* loss) {
// 应该是训练过程的前向传播
if (loss != NULL) {
*loss = ForwardFromTo(0, layers_.size() - 1);
}
else {
ForwardFromTo(0, layers_.size() - 1);
}
return net_output_blobs_;
}
template <typename Dtype>
const vector<Blob<Dtype>*>& Net<Dtype>::Forward(
const vector<Blob<Dtype>*> & bottom, Dtype* loss) {
LOG_EVERY_N(WARNING, 1000) << "DEPRECATED: Forward(bottom, loss) "
<< "will be removed in a future version. Use Forward(loss).";
// Copy bottom to net bottoms
for (int i = 0; i < bottom.size(); ++i) {
net_input_blobs_[i]->CopyFrom(*bottom[i]);
}
return Forward(loss);
}
// 与前向传播一样,反向传播也有很多相关函数,但都是对BackwardFromTo(int start, int end)的封装
template <typename Dtype>
void Net<Dtype>::BackwardFromTo(int start, int end) {
CHECK_GE(end, 0);
CHECK_LT(start, layers_.size());
for (int i = start; i >= end; --i) {
if (layer_need_backward_[i]) {
// 对每一层经行反向传播计算
layers_[i]->Backward(
top_vecs_[i], bottom_need_backward_[i], bottom_vecs_[i]);
if (debug_info_) { BackwardDebugInfo(i); }
}
}
}
// 在训练的过程中layer的权值要根据反向传播并累积的梯度进行更新,更新的过程由Update()完成。
// 这个函数的功能十分明确,对每个存储learnable_parms的blob调用blob的Update()函数,来更新权值。
template <typename Dtype>
void Net<Dtype>::Update() {
// 对每一个可学习参数更新权值
for (int i = 0; i < learnable_params_.size(); ++i) {
learnable_params_[i]->Update();
}
}
INSTANTIATE_CLASS(Net);
} // namespace caffesolver.hpp和solver.cpp
Solver类中包含一个Net指针,主要实现了训练模型参数所采用的优化算法,它所派生的类完成对整个网络进行训练.不同的模型训练方法通过重载函数ComputeUpdateValue()实现计算updata参数的核心功能.由Solver进行优化、更新参数,由Net计算出loss和gradient。
Solver构造函数,初始化net和test_net两个net类,并调用init函数初始化网络;Solver()训练网络有如下步骤:
1.设置Caffe的mode(GPU还是CPU),如果是GPU且有GPU芯片的ID.则设置GPU
2.设置当前阶段,TRAIN还是TEST
3.调用PreSolve函数:PreSolve()
4.调用Restore函数:Restore(resume_file):从一个文件中读入网络状态
5.调用一遍Test(),判断内存是否够
6.对于每一次训练时的迭代(遍历整个网络):计算loss;调用ComputeUpdateValue函数;输出loss;达到test_interval时调用Test();达到snapshot时调用snapshot()
每一次迭代过程中:调用Net的前向过程计算出输出和loss;调用Net的反向过程计算出梯度(loss对每层的权重w和偏置b求导);根据下面所讲的Solver方法,利用梯度更新参数;根据学习率(learning rate),历史数据和求解方法更新solver的状态,使权重从初始化状态逐步更新到最终的学习到的状态。
solver.hpp
#ifndef CAFFE_SOLVER_HPP_
#define CAFFE_SOLVER_HPP_
#include <boost/function.hpp>
#include <string>
#include <vector>
#include "caffe/net.hpp"
#include "caffe/solver_factory.hpp"
namespace caffe {
template <typename Dtype>
class Solver { // Solver模板类
public:
explicit Solver(const SolverParameter& param,
const Solver* root_solver = NULL); // 显示构造函数, 内部会调用Init函数
explicit Solver(const string& param_file, const Solver* root_solver = NULL);
void Init(const SolverParameter& param); // 成员变量赋值,包括param_、iter_、current_step_,并调用InitTrainNet和InitTestNets函数
void InitTrainNet(); // 为成员变量net_赋值
void InitTestNets(); // 为成员变量test_nets_赋值
virtual void Solve(const char* resume_file = NULL); // 依次调用函数Restore、Step、Snapshot,然后执行net_的前向传播函数ForwardPrefilled,最后调用TestAll函数
inline void Solve(const string resume_file) { Solve(resume_file.c_str()); }
void Step(int iters); // 反复执行net前向传播反向传播计算,期间会调用函数TestAll、ApplyUpdate、Snapshot及类Callback两个成员函数
void Restore(const char* resume_file); // 这个函数是存储来自SolverState缓冲的状态
void Snapshot(); // Solver::Snapshot主要是基本的快照功能,存储学习的网络
virtual ~Solver() {} // 虚析构
inline const SolverParameter& param() const { return param_; } // 返回solver参数
inline shared_ptr<Net<Dtype> > net() { return net_; } // 返回网络
inline const vector<shared_ptr<Net<Dtype> > >& test_nets() {
return test_nets_; // 返回测试网络
}
int iter() { return iter_; } // 获得当前迭代数
protected:
virtual void ApplyUpdate() = 0; // 纯虚函数,需要派生类实现,生成和应用当前迭代的更新的值
string SnapshotFilename(const string extension);
string SnapshotToBinaryProto(); // 写proto到.caffemodel
string SnapshotToHDF5(); // 写proto到HDF5文件
void TestAll(); // 内部会循环调用Test函数
void Test(const int test_net_id = 0); // 执行测试网络,net前向传播
virtual void SnapshotSolverState(const string& model_filename) = 0; // 存储snapshot solver stat
virtual void RestoreSolverStateFromHDF5(const string& state_file) = 0; // 读HDF5文件到solver state
virtual void RestoreSolverStateFromBinaryProto(const string& state_file) = 0; // 读二进制文件.solverstate到solver state
void DisplayOutputBlobs(const int net_id);
void UpdateSmoothedLoss(Dtype loss, int start_iter, int average_loss);
SolverParameter param_; // Solver参数
int iter_; // 当前的迭代数
int current_step_;
shared_ptr<Net<Dtype> > net_; // train net
vector<shared_ptr<Net<Dtype> > > test_nets_; // test Net,可以有多个
vector<Callback*> callbacks_;
vector<Dtype> losses_;
Dtype smoothed_loss_;
// 在数据并行中,继续根solver层保持根nets(包含共享的层)
const Solver* const root_solver_;
// 通过函数是选择确认按钮来选择保存还是退出快照。
ActionCallback action_request_function_;
// True iff a request to stop early was received.
bool requested_early_exit_;
DISABLE_COPY_AND_ASSIGN(Solver); // 禁止使用Solver类的拷贝和赋值操作
};
} // namespace caffe
#endif // CAFFE_SOLVER_HPP_solver.cpp
#include <cstdio>
#include <string>
#include <vector>
#include "caffe/solver.hpp"
#include "caffe/util/format.hpp"
#include "caffe/util/hdf5.hpp"
#include "caffe/util/io.hpp"
#include "caffe/util/upgrade_proto.hpp"
namespace caffe {
template <typename Dtype>
Solver<Dtype>::Solver(const SolverParameter& param, const Solver* root_solver)
: net_(), callbacks_(), root_solver_(root_solver),requested_early_exit_(false)
{ // 构造函数,初始化两个Net类,net_和test_net,并调用Init()函数
Init(param);
}
template <typename Dtype>
Solver<Dtype>::Solver(const string& param_file, const Solver* root_solver)
: net_(), callbacks_(), root_solver_(root_solver),requested_early_exit_(false)
{ // 构造函数,初始化两个Net类,net_和test_net,并调用Init()函数
SolverParameter param;
ReadSolverParamsFromTextFileOrDie(param_file, ¶m);
Init(param);
}
/*
功能:初始化网络
步骤:
1. 设置随机数种子
2. 申请一块Net空间以下面的构造函数进行初始化
param_file=train_net_,net_指向这块空间
3. 如果有test_net,则申请一块Net空间,test_net_指向这块空间
输入:SolverParameter类型的param
输出:无
*/
template <typename Dtype>
void Solver<Dtype>::Init(const SolverParameter& param) {
// 检查当前是否是root_solver(多GPU模式下,只有root_solver才运行这一部分的代码)
CHECK(Caffe::root_solver() || root_solver_)
<< "root_solver_ needs to be set for all non-root solvers";
LOG_IF(INFO, Caffe::root_solver()) << "Initializing solver from parameters: "
<< std::endl << param.DebugString();
//为solver类的数据成员param_赋值
param_ = param;
// 默认为1
CHECK_GE(param_.average_loss(), 1) << "average_loss should be non-negative.";
//检测快照的的写入权限
CheckSnapshotWritePermissions();
// 设置随机数种子
if (Caffe::root_solver() && param_.random_seed() >= 0) {
//调用Caffe命名空间里的set_random_seed函数,而不是caffe类的set_random_seed函数;
//param_.random_seed()实际上调用的是::google::protobuf::int64 random_seed()
Caffe::set_random_seed(param_.random_seed());
}
// Scaffolding code
// 搭建网络结构
InitTrainNet();
if (Caffe::root_solver()) {
LOG(INFO) << "You big SB.";
InitTestNets();
LOG(INFO) << "Solver scaffolding done.";
}
// iter_初始化为0
iter_ = 0;
current_step_ = 0;
}
// 初始化训练网络
template <typename Dtype>
void Solver<Dtype>::InitTrainNet() {
const int num_train_nets = param_.has_net() + param_.has_net_param() +
param_.has_train_net() + param_.has_train_net_param();
const string& field_names = "net, net_param, train_net, train_net_param";
// 有且只能有一个train net,训练网络
CHECK_GE(num_train_nets, 1) << "SolverParameter must specify a train net "
<< "using one of these fields: " << field_names;
CHECK_LE(num_train_nets, 1) << "SolverParameter must not contain more than "
<< "one of these fields specifying a train_net: " << field_names;
// 读取训练网络结构参数,四种方式加载,solver对应的参数
NetParameter net_param;
if (param_.has_train_net_param()) {
LOG_IF(INFO, Caffe::root_solver())
<< "Creating training net specified in train_net_param.";
net_param.CopyFrom(param_.train_net_param());
}
else if (param_.has_train_net()) {
LOG_IF(INFO, Caffe::root_solver())
<< "Creating training net from train_net file: " << param_.train_net();
ReadNetParamsFromTextFileOrDie(param_.train_net(), &net_param);
}
if (param_.has_net_param()) {
LOG_IF(INFO, Caffe::root_solver())
<< "Creating training net specified in net_param.";
net_param.CopyFrom(param_.net_param());
}
if (param_.has_net()) {
LOG_IF(INFO, Caffe::root_solver())
<< "Creating training net from net file: " << param_.net();
ReadNetParamsFromTextFileOrDie(param_.net(), &net_param);
}
//设置正确的网络状态,训练从默认开始,然后融入通过网络层规定在任何状态,
//最后融入训练状态(最优解)
NetState net_state;
net_state.set_phase(TRAIN);
LOG(INFO) << net_state.phase()<<"You big SB.";
net_state.MergeFrom(net_param.state());
LOG(INFO) << net_state.phase()<<"You big SB.";
//从低到高获取state,最终从最高优先级SolverParameter类型中的train_state,
//显然这会覆盖掉之前获取的state。
net_state.MergeFrom(param_.train_state());
LOG(INFO) << net_state.phase()<<"You big SB.";
//这里获取的state可以为Netparameter中的state赋值,然后可以根据LayerParameter中的
//include和exclude来确定该层是否应该包含在网络中。
net_param.mutable_state()->CopyFrom(net_state);
//这是Initialize train net 的一部分工作。InitTestNets也是如此
if (Caffe::root_solver()) {
//调用模板类的构造函数,进行net的初始化
net_.reset(new Net<Dtype>(net_param));
}
else {
net_.reset(new Net<Dtype>(net_param, root_solver_->net_.get()));
}
}
//初始化测试网络,需要注意的是TestNet可以有多个,而TrainNet只能有一个
template <typename Dtype>
void Solver<Dtype>::InitTestNets() {
CHECK(Caffe::root_solver());
const bool has_net_param = param_.has_net_param();
const bool has_net_file = param_.has_net();
const int num_generic_nets = has_net_param + has_net_file;
CHECK_LE(num_generic_nets, 1)
<< "Both net_param and net_file may not be specified.";
const int num_test_net_params = param_.test_net_param_size();
const int num_test_net_files = param_.test_net_size();
const int num_test_nets = num_test_net_params + num_test_net_files;
if (num_generic_nets) {
CHECK_GE(param_.test_iter_size(), num_test_nets)
<< "test_iter must be specified for each test network.";
} else {
CHECK_EQ(param_.test_iter_size(), num_test_nets)
<< "test_iter must be specified for each test network.";
}
//可以有多个test net
const int num_generic_net_instances = param_.test_iter_size() - num_test_nets;
const int num_test_net_instances = num_test_nets + num_generic_net_instances;
if (param_.test_state_size()) {
CHECK_EQ(param_.test_state_size(), num_test_net_instances)
<< "test_state must be unspecified or specified once per test net.";
}
if (num_test_net_instances) {
CHECK_GT(param_.test_interval(), 0);
}
int test_net_id = 0;
vector<string> sources(num_test_net_instances);
//得到测试网络参数,因为test网络可以有多个,因此通过循环赋值
vector<NetParameter> net_params(num_test_net_instances);
for (int i = 0; i < num_test_net_params; ++i, ++test_net_id) {
sources[test_net_id] = "test_net_param";
net_params[test_net_id].CopyFrom(param_.test_net_param(i));
}
for (int i = 0; i < num_test_net_files; ++i, ++test_net_id) {
sources[test_net_id] = "test_net file: " + param_.test_net(i);
ReadNetParamsFromTextFileOrDie(param_.test_net(i),
&net_params[test_net_id]);
}
const int remaining_test_nets = param_.test_iter_size() - test_net_id;
if (has_net_param) {
for (int i = 0; i < remaining_test_nets; ++i, ++test_net_id) {
sources[test_net_id] = "net_param";
net_params[test_net_id].CopyFrom(param_.net_param());
}
}
if (has_net_file) {
for (int i = 0; i < remaining_test_nets; ++i, ++test_net_id) {
sources[test_net_id] = "net file: " + param_.net();
ReadNetParamsFromTextFileOrDie(param_.net(), &net_params[test_net_id]);
}
}
test_nets_.resize(num_test_net_instances);
for (int i = 0; i < num_test_net_instances; ++i) {
// 设置正确的网络状态,训练从默认开始,然后融入通过网络层规定在任何状态,
// 最后融入测试状态(最优解)
NetState net_state;
net_state.set_phase(TEST);
net_state.MergeFrom(net_params[i].state());
if (param_.test_state_size()) {
net_state.MergeFrom(param_.test_state(i));
}
net_params[i].mutable_state()->CopyFrom(net_state);
LOG(INFO)
<< "Creating test net (#" << i << ") specified by " << sources[i];
if (Caffe::root_solver()) {
test_nets_[i].reset(new Net<Dtype>(net_params[i]));
} else {
test_nets_[i].reset(new Net<Dtype>(net_params[i],
root_solver_->test_nets_[i].get()));
}
test_nets_[i]->set_debug_info(param_.debug_info());
}
}
template <typename Dtype>
void Solver<Dtype>::Step(int iters) {
// 设置开始的迭代次数(如果是从之前的snapshot恢复的,那iter_等于snapshot时的迭代次数)和结束的迭代次数
const int start_iter = iter_;
// iters = param_.max_iter() - iter_
const int stop_iter = iter_ + iters;
// 输出的loss为前average_loss次loss的平均值,在solver.prototxt里设置,默认为1,
// losses存储之前的average_loss个loss,smoothed_loss为最后要输出的均值
int average_loss = this->param_.average_loss();
losses_.clear();
smoothed_loss_ = 0;
//迭代
while (iter_ < stop_iter) {
// zero-init the params
// 清空上一次所有参数的梯度
net_->ClearParamDiffs();
// test_initialization默认为true
// 判断是否需要测试,可以在proto中设置
if (param_.test_interval() && iter_ % param_.test_interval() == 0
&& (iter_ > 0 || param_.test_initialization())
&& Caffe::root_solver()) {
TestAll();
// 判断是否需要提前介绍迭代
if (requested_early_exit_) {
// Break out of the while loop because stop was requested while testing.
break;
}
}
for (int i = 0; i < callbacks_.size(); ++i) {
callbacks_[i]->on_start();
}
// 判断当前迭代次数是否需要显示loss等信息
const bool display = param_.display() && iter_ % param_.display() == 0;
net_->set_debug_info(display && param_.debug_info());
// accumulate the loss and gradient
Dtype loss = 0;
// iter_size也是在solver.prototxt里设置,实际上的batch_size=iter_size*网络定义里的batch_size,
// 因此每一次迭代的loss是iter_size次迭代的和,再除以iter_size,这个loss是通过调用`Net::ForwardBackward`函数得到的
// 这个设置我的理解是在GPU的显存不够的时候使用,比如我本来想把batch_size设置为128,但是会out_of_memory,
// 借助这个方法,可以设置batch_size=32,iter_size=4,那实际上每次迭代还是处理了128个数据
// accumulate gradients over `iter_size` x `batch_size` instances
for (int i = 0; i < param_.iter_size(); ++i) {
/*
* 调用了Net中的代码,主要完成了前向后向的计算,
* 前向用于计算模型的最终输出和Loss,后向用于
* 计算每一层网络和参数的梯度。
*/
loss += net_->ForwardBackward();
}
//accumulate(累积) gradients over `iter_size` x `batch_size` instances。
//默认情况下,iter_size=1,即默认情况下,一个iteratio一个batch
loss /= param_.iter_size();
// 计算要输出的smoothed_loss,如果losses里还没有存够average_loss个loss
//则将当前的loss插入,如果已经存够了,则将之前的替换掉
// average the loss across iterations for smoothed reporting
/*
* 这个函数主要做Loss的平滑。由于Caffe的训练方式是SGD,我们无法把所有的数据同时
* 放入模型进行训练,那么部分数据产生的Loss就可能会和全样本的平均Loss不同,在必要
* 时候将Loss和历史过程中更新的Loss求平均就可以减少Loss的震荡问题。
*/
UpdateSmoothedLoss(loss, start_iter, average_loss);
//输出当前迭代信息
if (display) {
LOG_IF(INFO, Caffe::root_solver()) << "Iteration " << iter_
<< ", loss = " << smoothed_loss_;
const vector<Blob<Dtype>*>& result = net_->output_blobs();
int score_index = 0;
for (int j = 0; j < result.size(); ++j) {
const Dtype* result_vec = result[j]->cpu_data();
const string& output_name =
net_->blob_names()[net_->output_blob_indices()[j]];
const Dtype loss_weight =
net_->blob_loss_weights()[net_->output_blob_indices()[j]];
for (int k = 0; k < result[j]->count(); ++k) {
ostringstream loss_msg_stream;
if (loss_weight) {
loss_msg_stream << " (* " << loss_weight
<< " = " << loss_weight * result_vec[k] << " loss)";
}
LOG_IF(INFO, Caffe::root_solver()) << " Train net output #"
<< score_index++ << ": " << output_name << " = "
<< result_vec[k] << loss_msg_stream.str();
}
}
}
for (int i = 0; i < callbacks_.size(); ++i) {
callbacks_[i]->on_gradients_ready();
}
// 执行梯度的更新,这个函数在基类`Solver`中没有实现,会调用每个子类自己的实现
//,后面具体分析`SGDSolver`的实现
ApplyUpdate();
// Increment the internal iter_ counter -- its value should always indicate
// the number of times the weights have been updated.
// 迭代次数加1
++iter_;
// 调用GetRequestedAction,实际是通过action_request_function_函数指针调用之前设置好(通过`SetRequestedAction`)的
// signal_handler的`CheckForSignals`函数,这个函数的作用是
// 会根据之前是否遇到系统信号以及信号的类型和我们设置(或者默认)的方式返回处理的方式
SolverAction::Enum request = GetRequestedAction();
// Save a snapshot if needed.
// 判断当前迭代是否需要snapshot,如果request等于`SNAPSHOT`则也需要
if ((param_.snapshot()
&& iter_ % param_.snapshot() == 0
&& Caffe::root_solver()) ||
(request == SolverAction::SNAPSHOT)) {
Snapshot();
}
// 如果request为`STOP`则修改`requested_early_exit_`为true,之后就会提前结束迭代
if (SolverAction::STOP == request) {
requested_early_exit_ = true;
// Break out of training loop.
break;
}
}
}
/*
对整个网络进行训练(也就是你运行Caffe训练某个模型)的时候,实际上是在运行caffe.cpp中的
train()函数,而这个函数实际上是实例化一个Solver对象,初始化后调用了Solver中的Solve()方法
调用此方法训练网络,其中会调用Step()方法来迭代,迭代 param_.max_iter() - iter_ 次
*/
template <typename Dtype>
void Solver<Dtype>::Solve(const char* resume_file) {
// 检查当前是否是root_solver(多GPU模式下,只有root_solver才运行这一部分的代码)
CHECK(Caffe::root_solver());
LOG(INFO) << "Solving " << net_->name();
LOG(INFO) << "Learning Rate Policy: " << param_.lr_policy();
// Initialize to false every time we start solving.
// requested_early_exit_`一开始被赋值为false,也就是现在没有要求在优化结束前退出
requested_early_exit_ = false;
// 判断`resume_file`这个指针是否NULL,
//如果不是则需要从resume_file存储的路径里读取之前训练的状态
if (resume_file) {
LOG(INFO) << "Restoring previous solver status from " << resume_file;
Restore(resume_file);
}
// For a network that is trained by the solver, no bottom or top vecs
// should be given, and we will just provide dummy vecs.
int start_iter = iter_;
//对于一个正在训练的网络,没有bottom或top向量被给,而且仅仅提供dummy vecs
// 然后调用了'Step'函数,这个函数执行了实际的逐步的迭代过程
// 最大迭代次数(正向传播,反向传播,计算显示loss,更新数据)
Step(param_.max_iter() - iter_);
// If we haven't already, save a snapshot after optimization, unless
// overridden by setting snapshot_after_train := false
// 迭代结束或者遇到系统信号提前结束后,判断是否需要在训练结束之后snapshot
// 这个可以在solver.prototxt里设置
if (param_.snapshot_after_train()
&& (!param_.snapshot() || iter_ % param_.snapshot() != 0)) {
Snapshot();
}
// 如果在`Step`函数的迭代过程中遇到了系统信号,且我们的处理方式设置为`STOP`,
// 那么`requested_early_exit_`会被修改为true,迭代提前结束,输出相关信息
if (requested_early_exit_) {
LOG(INFO) << "Optimization stopped early.";
return;
}
// After the optimization is done, run an additional train and test pass to
// display the train and test loss/outputs if appropriate (based on the
// display and test_interval settings, respectively). Unlike in the rest of
// training, for the train net we only run a forward pass as we've already
// updated the parameters "max_iter" times -- this final pass is only done to
// display the loss, which is computed in the forward pass.
// 优化完后,运行一个额外的训练和测试过程展示训练测试的loss或者输出。
// 判断是否需要输出最后的loss
if (param_.display() && iter_ % param_.display() == 0) {
int average_loss = this->param_.average_loss();
Dtype loss;
net_->Forward(&loss);
UpdateSmoothedLoss(loss, start_iter, average_loss);
LOG(INFO) << "Iteration " << iter_ << ", loss = " << smoothed_loss_;
}
// 判断是否需要最后Test
if (param_.test_interval() && iter_ % param_.test_interval() == 0) {
TestAll();
}
LOG(INFO) << "Optimization Done.";
}
template <typename Dtype>
void Solver<Dtype>::TestAll() { // 可能还有多个Test,因此循环测试
for (int test_net_id = 0;
test_net_id < test_nets_.size() && !requested_early_exit_;
++test_net_id) {
Test(test_net_id);
}
}
template <typename Dtype>
void Solver<Dtype>::Test(const int test_net_id) {
CHECK(Caffe::root_solver());
LOG(INFO) << "Iteration " << iter_
<< ", Testing net (#" << test_net_id << ")";
// 检查是否有layer共享于多个网络
CHECK_NOTNULL(test_nets_[test_net_id].get())->
ShareTrainedLayersWith(net_.get());
vector<Dtype> test_score;
vector<int> test_score_output_id;
const shared_ptr<Net<Dtype> >& test_net = test_nets_[test_net_id];
Dtype loss = 0;
for (int i = 0; i < param_.test_iter(test_net_id); ++i) {
SolverAction::Enum request = GetRequestedAction();
// Check to see if stoppage of testing/training has been requested.
//如果在训练或测试中断请求发出后,随时执行保存快照
while (request != SolverAction::NONE) {
if (SolverAction::SNAPSHOT == request) {
Snapshot();
} else if (SolverAction::STOP == request) {
requested_early_exit_ = true;
}
request = GetRequestedAction();
}
if (requested_early_exit_) {
// break out of test loop.
break;
}
Dtype iter_loss;
const vector<Blob<Dtype>*>& result =
test_net->Forward(&iter_loss); // result是所有的输出层blob,把每一个blob的数据存入vector.test_score中
if (param_.test_compute_loss()) {
loss += iter_loss;
}
if (i == 0) { // 第一个测试时,取每一个输出称的blob
for (int j = 0; j < result.size(); ++j) {
const Dtype* result_vec = result[j]->cpu_data();
for (int k = 0; k < result[j]->count(); ++k) {
test_score.push_back(result_vec[k]);
test_score_output_id.push_back(j);
}
}
} else { // 不是第一个测试时,把输出层对应位置的blob位置累加
int idx = 0;
for (int j = 0; j < result.size(); ++j) {
const Dtype* result_vec = result[j]->cpu_data();
for (int k = 0; k < result[j]->count(); ++k) {
test_score[idx++] += result_vec[k];
}
}
}
}
if (requested_early_exit_) {
LOG(INFO) << "Test interrupted.";
return;
}
if (param_.test_compute_loss()) {
loss /= param_.test_iter(test_net_id);
LOG(INFO) << "Test loss: " << loss;
}
for (int i = 0; i < test_score.size(); ++i) {
const int output_blob_index =
test_net->output_blob_indices()[test_score_output_id[i]];
const string& output_name = test_net->blob_names()[output_blob_index];
const Dtype loss_weight = test_net->blob_loss_weights()[output_blob_index];
ostringstream loss_msg_stream;
//求多次迭代Loss的平均值,也就是求多个batch的平局值,
//一次迭代用的是一个test batch-size 的图片
const Dtype mean_score = test_score[i] / param_.test_iter(test_net_id);
if (loss_weight) {
loss_msg_stream << " (* " << loss_weight
<< " = " << loss_weight * mean_score << " loss)";
}
LOG(INFO) << " Test net output #" << i << ": " << output_name << " = "
<< mean_score << loss_msg_stream.str();
}
}
//更新平滑后的Loss
template <typename Dtype>
void Solver<Dtype>::UpdateSmoothedLoss(Dtype loss, int start_iter,
int average_loss) {
if (losses_.size() < average_loss) {
losses_.push_back(loss);
int size = losses_.size();
smoothed_loss_ = (smoothed_loss_ * (size - 1) + loss) / size;
}
else {
int idx = (iter_ - start_iter) % average_loss;
smoothed_loss_ += (loss - losses_[idx]) / average_loss;
losses_[idx] = loss;
}
}
///模板显示实例化
INSTANTIATE_CLASS(Solver);
} // namespace caffe













 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









