







 本文介绍FCNN,一种用于语义分割的全卷积网络。该网络通过取消全连接层,采用反卷积层进行上采样,并融合不同深度层结果实现端到端的图像语义分割。
本文介绍FCNN,一种用于语义分割的全卷积网络。该网络通过取消全连接层,采用反卷积层进行上采样,并融合不同深度层结果实现端到端的图像语义分割。
论文阅读笔记:FCNN:Fully Convolutional Networks for semantic Segmentation
论文下载地址:Fully Convolutional Networks for semantic Segmentation
CVPR 2015 best paper
本文主要包含如下内容:
核心思想
论文首次提出了一种end-to-end(端到端)用于语义分割的“全卷积”网络,全卷积网络在 PASCAL VOC(在 2012 年相对以前有 20% 的提升,达到了62.2% 的平均 IU),NYUDv2 和 SIFT Flow 上实现了最优的分割结果。
- 不含全连接层(fc)的全卷积(fully conv)网络,即将全连接层改为全卷积层。可适应任意尺寸输入。
- 在 decode 上采样步骤中使用增大数据尺寸的反卷积(deconv)层(初始化参数为双线性插值滤波器)。能够输出精细的结果。
- 结合不同深度层结果的跳级(skip)结构,同时确保鲁棒性和精确性。但同时引入了更大的参数量。将深的、粗糙的网络层语义信息和浅的、精细的网络层的表层信息结合起来,来生成精确的分割。(FCN 最重要的点)
网络结构

网络中后面的全链接层(fc6,fc7)被转化为卷积层,这就是“全卷积”网络,最后得到了一个较为粗糙的输出。
举个例子说明全卷积层:如果 227 × 227 输入图像经过一系列卷积池化,得到图像对应的特征图,对其进行分类,将得到图像的类别信息。对于一个 500×500 大小的图像,我们可以用 10 × 10 个 227 × 227 的子图像块进行覆盖,这样就得到了 10 × 10 个特征图,分别对这些特征图进行分类,得到一个 10 × 10 的分割结果。
FCN 在最后做了一个叫pixelwise prediction的预测,可以看到,输出图像和输入图像具有相同的尺寸,然而前面的网路使用了降采样。这里没有使用简单的双线性插值进行上采样,运用反卷积层(初始化参数为双线性插值滤波器)。这些卷积运算的参数可以在训练过程中学习得到。
举个例子说明反卷积层:对 10 × 10 的分割结果,我们使用一个deconvolution layer反卷积层进行上采样到输入图像尺寸得到 FCN-32s 分割结果,即直接放大32倍。

在传统的分类 CNNs 中,池化操作用来增加视野,同时减少特征图的分辨率。这对于分类任务来说非常有用,因为分类的最终目标是找到某个特定类的存在,而对象的空间位置无关紧要。因此,在每个卷积块之后引入池化操作,以使后续块能够从已池化的特征中提取更多抽象、突出类的特征。
另一方面,池化和带步长的卷积对语义分割是不利的,因为这些操作造成了空间信息的丢失。因此,论文中 FCN-8s 融合了不同粗糙度(conv3、conv4和fc7)的特征,利用编码器不同阶段不同分辨率的空间信息来细化分割结果。

FCN-32s 再经过步长为32的上采样后,获得的预测结果比较粗糙,所以考虑加入了更多前层的细节信息。于是采用了skip layer的方法,将粗的高层信息和低层信息结合concatenation。在浅层处减小upsampling的步长,得到多个label map prediction,然后做融合(fushion)。但这个步骤引入了更大的参数量。
FCN-16s结合了pool5层和pool4层的预测,upsampling的步长为16,让网络预测出更精细的细节,同时保留了高层语义信息。FCN-8s则结合了pool3层的预测,upsampling的步长为8,精度进一步提高。
实际我们是这么干的:对pool4的输出使用一个 1 × 1 卷积层进行分类(这里使用 1*1 卷积核进行降维处理,是为了保持与后面特征图具有相同的通道数),得到一个分割结果图B(经过 crop 裁剪),然后再对conv7的分割结果A进行 2 × upsampling layer 得到一个放大2倍的分割结果图A2, 将这两个分类置信度图求和相加得到了一个分割结果图C(求和 sum,通道数不变),最后使用一个 deconvolution layer 进行双线性上采样到输入图像尺寸得到 FCN-16s 分割结果,直接放大16倍。(注意:是对特征图进行相加求解)
实验结果
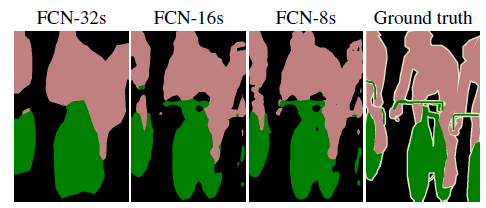
实验结果表明,FCN-16s将平均IU(region inntersection over union)有效提高到62.4,提高了一定的精度。FCN-8s则在平均IU上获得了一个较小的提出,到达了62.7,在平滑度和输出细节上有轻微的提高。

数据集(PASCAL VOC):这个表格给出了FCN-8s在图像识别与物件分类的挑战赛PASCAl VOC2011和2012测试集上的表现,将它和SDS和R-CNN算法进行比较。FCN-8s有较好的效果。

数据集(NVUDv2):NVUDv2是一种通过利用Microsoft Kinect收集到的RGB-D数据集,含有语义分割任务的pixelwise标签。

数据集(SIFT-FLOW):图像语义分割与几何语义分割数据集

图像识别与物体分类挑战赛PASCAL的部分结果图,FCN-8s分割的效果很好。可以直观地看出,本文方法和Groud truth相比,容易丢失较小的目标和局部的细节信息,比如第一幅图片中的汽车,和第二幅图片中的观众人群

网络结构图
layer {
name: "score_pool4"
type: "Convolution"
bottom: "pool4"
top: "score_pool4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 21
pad: 0
kernel_size: 1
}
}
layer {
name: "score_pool4c"
type: "Crop"
bottom: "score_pool4"
bottom: "upscore2"
top: "score_pool4c"
crop_param {
axis: 2
offset: 5
}
}
layer {
name: "fuse_pool4"
type: "Eltwise"
bottom: "upscore2"
bottom: "score_pool4c"
top: "fuse_pool4"
eltwise_param {
operation: SUM
}
}
layer {
name: "upscore_pool4"
type: "Deconvolution"
bottom: "fuse_pool4"
top: "upscore_pool4"
param {
lr_mult: 0
}
convolution_param {
num_output: 21
bias_term: false
kernel_size: 4
stride: 2
}
}
layer {
name: "score_pool3"
type: "Convolution"
bottom: "pool3"
top: "score_pool3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 21
pad: 0
kernel_size: 1
}
}
layer {
name: "score_pool3c"
type: "Crop"
bottom: "score_pool3"
bottom: "upscore_pool4"
top: "score_pool3c"
crop_param {
axis: 2
offset: 9
}
}
layer {
name: "fuse_pool3"
type: "Eltwise"
bottom: "upscore_pool4"
bottom: "score_pool3c"
top: "fuse_pool3"
eltwise_param {
operation: SUM
}
}
layer {
name: "upscore8"
type: "Deconvolution"
bottom: "fuse_pool3"
top: "upscore8"
param {
lr_mult: 0
}
convolution_param {
num_output: 21
bias_term: false
kernel_size: 16
stride: 8
}
}
layer {
name: "score"
type: "Crop"
bottom: "upscore8"
bottom: "data"
top: "score"
crop_param {
axis: 2
offset: 31
}
}
可以看到,这里一共做了三个步骤,1*1 卷积核降维,crop 裁剪特征图,Eltwise 两个特征图求和操作,Deconvolution 反卷积上采样操作。

















 723
723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









