






0、说明
虽然在《统计学习方法》中logistic方法在第五章,但是上一节主要是总结了感知机算法,为了更好的衔接,我打算先把logistic提前总结,因为两种方法都属于线性模型。同样,下一次笔记,我们将介绍SVM算法。
1、逻辑斯蒂回归模型
逻辑斯蒂回归不是回归,是分类!
1.1 逻辑斯蒂分布
设X是连续随机变量,X服从逻辑斯蒂分布是指X具有下列分布函数和密度函数:
式中,为位置参数,决定了密度函数对称轴的位置;
为形状参数,决定了密度函数的聚合程度。
逻辑斯蒂分布的密度函数f(x)和分布函数F(x)的图形如下图所示。

分数不函数F(x)属于逻辑斯蒂函数,其图形是一条S形曲线(sigmoid curve)。该曲线以点为中心对称,既满足:
( 解释:若f(x)关于点(a,b)中心对称,则有f(x+a)+f(a-x)=2b)
通过图像可以观察到,曲线在中心附近增长速度较快(对应到密度函数f(x)就是对称轴两侧附近),在两端增长速度较慢,形状参数的制越小,曲线在中心附近增长的越快,因为当
值比较小的时候,f(x)图像越陡。
1.2 二项逻辑斯蒂回归模型
二项逻辑斯蒂回归模型(binomial logistic regression model)是一种分类模型,由条件概率分布P(Y|X)表示(已知X的前提下,是Y类的概率),形式为参数化的逻辑死地分布。这里,随机变量X取值为实数,随机变量Y取值为0或1,我们通过监督学习的方法来估计模型参数。
定义(逻辑斯蒂回归模型)二项逻辑斯蒂回归模型是如下的条件概率分布:
这里,是输入,
是输出,
是参数,w称为取值向量,b称为偏置,w.x为w和x的内积。
分类过程为:
对于非定的输入实例x,按照(6.3)和(6.4)式,可以分别求得X属于1类和X属于0类的概率,逻辑斯蒂回归比较两个条件概率值大小,将实例x分到概率值比较大的那一类。
在此,我们将权值向量和输入向量加以扩充,仍记作w,x。此时,集,将偏置加入到权重向量里面去,是的x向量中偏置所对应的分量为1,写到一起是为了方便书写和运算。这时,逻辑斯蒂回归模型可以简化如下:
一个时间的几率(odds)是指该事件发生的概率与该事件不发生的概率的比值。如果事件发生的概率是p,那么该事件的几率是p/(1-p),该事件的对数几率(log odds)或者logit 函数是
对于逻辑斯蒂回归而言,由(6.5)与(6.6)式可以得到,
这就是说,在逻辑斯蒂回归模型中,输出Y=1的对数几率是输入x的线性函数,或者说,输出Y=1的对数几率是由输入x的线性函数表示的模型,即逻辑斯蒂回归模型。
换一个角度看,考虑对输入x进行分类的线性函数,其值域为实数域。注意,这里
,通过逻辑斯蒂回归模型定义式(6.5)可以将线性函数
转换为概率:
这个时候,线性函数的值越接近正无穷,概率值越接近于1;线性函数的值域越接近于负无穷,概率值越接近于0。当<0的时候,P(Y=1|x)<0.5,此时x应该属于0类;当
>0的时候,P(Y=1|x)>0.5,此时x应该属于1类;忽略
=0的情况。这样的模型为逻辑斯蒂回归模型。
拓展
以下是拓展内容,加强对逻辑斯蒂的理解。
逻辑回归(Logistic Regression,LR)模型其实仅在线性回归的基础上,套用了一个逻辑函数,但也就是由于这个逻辑函数,使得逻辑回归模型成为了机器学习领域一棵耀眼的明星,更是计算广告学的核心。
回归是一种极易理解的模型,就相当于y=f(x),表明自变量x与因变量y的关系。最常见问题有如医生治病时的望、闻、问、切,之后判定病人是否生病或生了什么病,其中的望闻问切就是获取自变量x,即特征数据,判断是否生病就相当于获取因变量y,即预测分类。
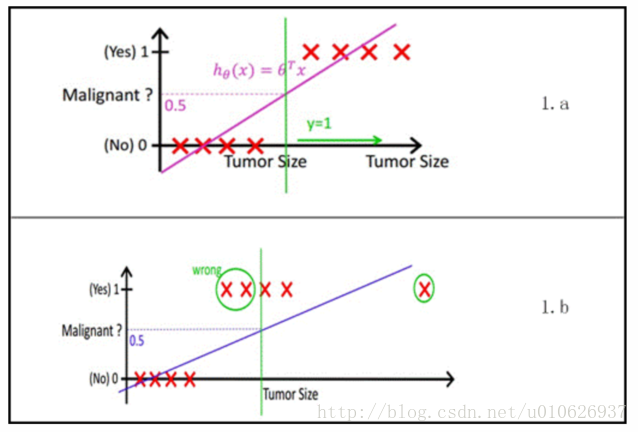
然而线性回归的鲁棒性很差,例如在图1.b的数据集上建立回归,因最右边噪点的存在,使回归模型在训练集上表现都很差。这主要是由于线性回归在整个实数域内敏感度一致,而分类范围,需要在[0,1]。逻辑回归就是一种减小预测范围,将预测值限定为[0,1]间的一种回归模型,其回归方程与回归曲线如图2所示。逻辑曲线在z=0时,十分敏感,在z>>0或z<<0处,都不敏感,将预测值限定为(0,1)。
 (图2逻辑方程与逻辑曲线)
(图2逻辑方程与逻辑曲线)
1.3 模型参数估计
逻辑斯蒂回归模型学习时,对于给定的训练数据集,其中,
,可以应用极大似然估计法估计模型参数,从而得到逻辑斯蒂回归模型。
设:
对于训练数据集T的似然函数为:
(因为训练集T中有N个实例点,似然函数可以理解为在已知P(Y=1|x)概率的前提下,N个实例点(观察到的数据,即已知的数据)同时发生概率,所以在此是连乘的形式。)
对数似然函数为,即上式取对数:
对L(w)求极大值,得到w的估计值。
(极大(最大)似然估计就是在已知观测的数据的数据的前提下,找到使得似然函数概率最大的参数值。)
这样问题就变成了以对数函数为目标函数的最优化问题,逻辑斯蒂回归学习中通常采用的方法是梯度下降法及拟牛顿法。
假设w的极大似然估计值为,那么学习到的逻辑斯蒂回归模型为:
补充
1.4 多项逻辑斯蒂回归
上面介绍的逻辑斯蒂回归模型是二项分类模型,用于二分类,可以将其推广为多项式逻辑斯蒂回归模型(multi-nominal logistic regression model)用于多分类,假设离散型随机变量Y的取值集合是{1,2,…,K}那么多项逻辑斯蒂模型是
注意:累加和部分是从1到k-1,而不是到k
2 最大熵模型
最大熵原理
最大熵原理是概率模型学习的一个准则,最大熵原理认为,学习概率模型时,在所有可能的概率模型(分布)中,熵最大的模型是最好的模型。通常用约束条件来确定概率模型的集合,所以,最大熵原理也可以表述为在满足约束条件的模型集合中,选择熵最大的模型。
假设离散随机变量X的概率分布是P(X),则其熵是
熵满足下列不等式:
式中,|X|是X的取值个数,当且仅当X的分布是均匀分布的时候,右边的等号成立,这就是说,当X服从均匀分布的时候,熵最大。
(解释:当X服从均匀分布的时候,P(X)=1/|X|,此时,H(P)=log|X|)
直观地,最大熵模原理认为要选择的概率模型首选必须满足已有的事实,即约束条件。在没有更多信息情况下,那些不确定的部分都是“等可能性的”。最大熵原理通过熵的最大化来表示等可能性。“等可能”不容易操作,而熵则是一个可优化的数值指标。
下面通过一个例子介绍最大熵原理。


最大熵模型的定义
给定一个训练数据集,学习的目标是用最大熵原理选择最好的分类模型。
首选考虑模型应该满足的条件,给定训练数据集,可以确定联合分布P(X,Y)的经验分布和边缘分布P(Y)的经验分布,分别以表示。这里,
其中,表示训练数据中样本(x,y)出现的频数,
表示训练数据中输入x的出现频数,N表示训练样本的容量。
用特征函数(feature function)f(x,y)描述输入x和输出y之间的某一个实时,其定义是
它是一个二值函数,当x和y满足这个事实时取值为1,否则取值为0。
特征函数f(x,y)关于经验分布的期望值,用
表示。
特征函数f(x,y)关于模型P(Y|X)与经验分布的期望值,用
表示。
如果模型能够获取训练数据中的信息,那么就可以假设这两个期望值相等(
或者
我们将(6.10)或者(6.11)作为模型学习的约束条件。加入有n个特征函数,那么就有n个约束条件。
定义(最大熵模型)假设满足所有约束条件的模型集合为
定义在条件概率分布P(Y|X)上的条件熵为
则模型集合C中条件熵H(P)最大的模型称为最大熵模型。式中的对数为自然对数。
《未完待续…》
人生如棋,落子无悔!
-----------By Ada















 1240
1240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











