







优化My School数据库设计
2015-8-10 星期一
1. 数据库的设计
1. 设计数据库的几个阶段:
需求分析、概要设计、详细设计
2. 设计数据库的几个步骤:
收集信息(需要完成那些任务,具有哪些功能);
标识实体(标识出主要的实体对象,如:客房、客人等具体实体对象);
标识每个实体需要存储的详细信息(需要对主要实体进行细分,如:客房实体下需要有客房号、客房容量等等);
标识实体间的关系(主从关系)
3. E-R图(实体-关系图)
实体表示数据表中的一行数据。
| 客人姓名 | 客人年龄 | …… |
| 张三 | 25 | …… |
| …… | …… | …… |
映射基数:
一对一(1:1):一个X对应一个Y;
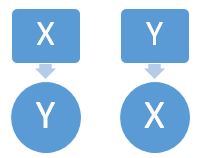
一对多(1:N):一个X可对应多个Y;Y最多可对应一个X;
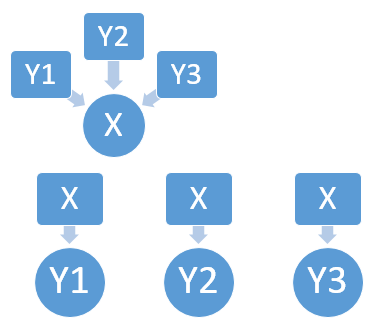
多对一(N:1):多个X可对应一个Y;一个Y最多可对应一个X;

多对多(M:N):多个X与多个Y对应。
4. E-R图存在的意义:
确认系统中的数据处理需求是否正确和完整(相当于“打草稿”,“工程图纸”)。
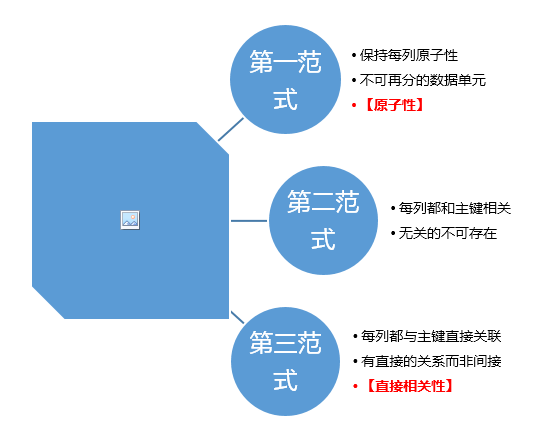
5. 数据规范化
三大范式:
2. 数据库的实现
1. SQLServer数据库的文件组成:
主数据文件:.mdf
次数据文件:.ndf
数据日志文件:.ldf
l 数据文件和日志文件可以有多个。
2. IFEXISTS([用于执行查询的语句])可以用来判断查询的结果是否存在
3. SQL数据类型对照表:
| 数据类型 | 存储特点 | 存储大小 |
| char(n) | 定长 | N |
| varchar(n) | 变长 | 实际长度 + 2 |
| nchar(n) | 定长 | N * 2字节 |
| nvarchar(n) | 变长 | 实际长度 * 2 + 2 |
| nvarchar(max) | 变长 | 实际长度 * 2 + 2 |
4. 查询数据库中的所有数据库使用:
select * from sysdatabases
查询某个数据库中所有的数据表使用:
select * from sysobjects
5. 数据完整性:
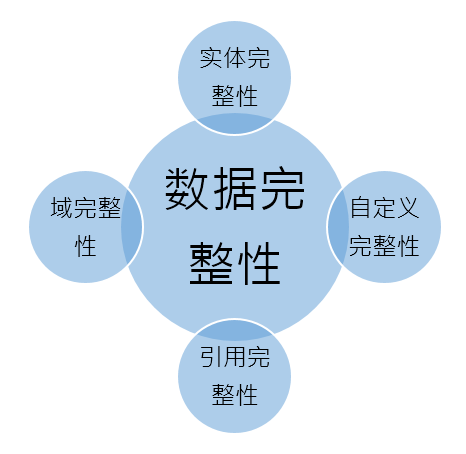
实体完整性 定义:唯一确定每一行实体数据不重复;
域完整性 定义:数据约束;
引用完整性 定义:主外键约束;
自定义完整性 定义:除以上之外的特定业务规则。
6. 约束类型对照表:
| 约束类型名 | 约束类型定义 | 约束语法示例 |
| 主键约束 | 主键唯一且不为空 | ALTER TABLE [表名] ADD CONSTRAINT PK_[约束名] PRIMARY KEY [要建立约束的列名] |
| 非空约束 | 不能输入空值 | 在使用SQL语句创建列时即可约定 |
| 唯一约束 | 值唯一且只能出现一个空值 | ALTER TABLE [表名] ADD CONSTRAINT UQ_[约束名] UNIQUE [要建立约束的列名] |
| 检查约束 | 对取值范围进行限制 | ALTER TABLE [表名] ADD CONSTRAINT CK_[约束名] CHECK ([设置条件的语句段]) |
| 默认约束 | 设置默认值 | ALTER TABLE [表名] ADD CONSTRAINT DF_[约束名] DEFAULT ([默认值]) FOR [列名] |
| 外键约束 | 引用主表的哪一列,两表关联 | ALTER TABLE [从表名] ADD CONSTRAINT FK_[约束名] FOREIGN KEY([从表列名])REFERENCES [主表名] ([主表列/关联列]) |
3. SQL编程
1. 声明变量的方式:
DECLARE@[变量名] [变量的数据类型]
2. 为已声明的变量赋值的两种方式:
SET@[变量名] = [变量值]
SELECT@[变量名] = [变量值]
3. SET与SELECT的区别:
|
| SET | SELECT |
| 多变量赋值 | 不支持 | 支持 |
| 表达式返回多值时 | 发生异常 | 结果为返回的最后一个值 |
| 表达式未返回值时 | NULL | 原值 |
4. CAST()与CONVERT()函数的区别:
|
| CAST | CONVERT |
| 语法格式 | CAST([表达式] AS [数据类型]) | CONVERT([数据类型],[表达式]) |
| 第三参数格式化日期 | 不支持 | 支持 |
CAST()函数和CONVERT()函数的具体使用:

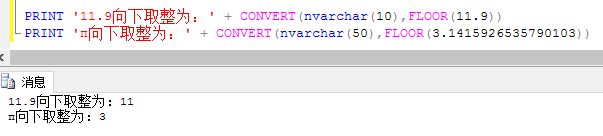
5. FLOOR()向下取整函数
例:
6. 逻辑控制语句
注意项:
n 在一个小结构中若有多条语句,则使用BEGIN……END语句块嵌套表示语句块的开始和结束,且语句块间可以包含和被包含。
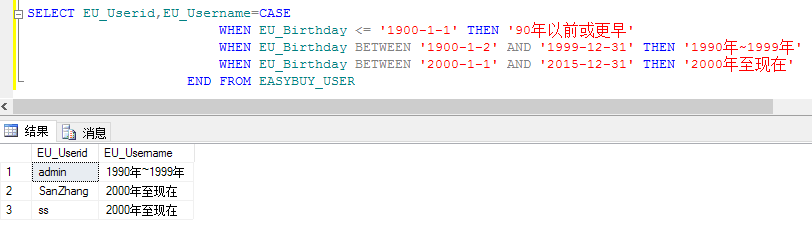
n CASE……WHEN多分支语句:
例:
n GO指令用于将多条SQL语句编译为一个可执行单元,称为“执行计划”。可以提高执行效率。每个批处理相互独立,互不影响。
n SQL中的换行符使用 char(13)。
7. 经典习题:
如下创建表并插入数据后,查询表则返回的结果为:
CREATE TABLE numbers
{
N1 INT, //不会四舍五入,会截断
N2 NUMBERIC(5,0), //会四舍五入
N3 NUMBERIC(4,2) //会四舍五入,且保留2位,若位数不够则补0
}
INSERT INTO numbersVALUES(1.5,1.5,1.5)
SELECT * FROMnumbers
答案:1、2、1.50
4. 高级查询
1. 子查询
n SELECT* FROM [表名] 的执行效率低于SELECT [列名1],[列名2]…… FROM [表名] 。
n 括号中(内部子查询)先执行,然后再一步一步向外执行,达到顶级父查询处停止并返回查询结果。
n 表连接都可被子查询替换;
子查询不一定能全部被表连接替换。
子查询功能更加强大和灵活。
n 子查询可以嵌套于SQL语句中的任何位置。
n 两种嵌套查询结构:
SELECT嵌套SELECT:
SELECT (子查询SELECT……) FROM [表名] //无需为子查询指定列的别名。这里和下面的情况有所区别,这种查询在最外边的父查询还有完整的SQL语法结构
SELECT嵌套FROM:
SELECT * FROM (子查询SELECT……) AS [表的别名] //此时在FROM中嵌套,必须指定别名。如果不写就等于父查询没有表名,这是不符合SQL语法规范的
2. IN和NOT IN子查询
适用于子查询需要返回不止一条结果的查询。
3. EXISTS和NOT EXISTS查询
IF EXISTS([查询语句])
若查询语句返回了结果(结果非空),则整个语句返回true;否则返回false。
4. 部分常用通配符:
| 通配符符号表示 | 通配符含义 |
| % | 匹配任意字符 |
| _ | 匹配单个字符 |
| [^] | 除括号内的字符外的其他所有字符 |
| [^0-9] | 除0~9外的其他所有字符 |
5. 事务、视图和索引
1. 事务
指“单个数据单元”。
特性:保持数据一致性与完整性。事务成功,则在该事务中所有对数据的更改都会提交;否则将清除所有对数据的更改。
事务的具体特性:
| 事务特性名称 | 特性阐释 |
| 原子性 | 事务是一个完整的操作,其不可分割 |
| 一致性 | 执行事务前后,数据保持一致 |
| 隔离性 | 事务相互独立,不互相牵制 |
| 持久性 | 事务对数据的修改是持久性的,永久保存于数据库中 |
2. 执行事务
| 事务操作语句 | 事务操作说明 |
| BEGINTRANSACTION | 开始事务 |
| COMMITTRANSACTION | 提交事务并释放连接资源 |
| ROLLBACKTRANSACTION | 回滚事务并释放控制的资源 |
3. 判断事务中是否出错
使用系统内置变量 @@ERROR 配合一个声明了的累加变量进行判断。
在事务执行过程中发生任何显示或隐式错误,都会以错误码的形式保存于 @@ERROR 变量中。
4. 视图
是保存在数据库中的一种SELECT查询。
使用视图的优点:
ü 提高安全性。不必查看数据库结构;
ü 更易理解数据。
以视图的形式展示数据的方式称为“数据链路”;
视图也是一种数据表,视图记录存于系统的sysobjects表中。
5. 创建视图
CREATE VIEW view_[视图名称] AS [SELECT语句,用于建立指定的视图]
6. 视图使用注意事项
ü 不能在创建视图的SQL语句中出现ORDER BY字句(除非语句中有TOP字句)、INTO关键字和引用临时表和引用变量
ü 视图中可涉及多个表
ü 视图可嵌套引用,但最好不多于3层
7. 索引
通过索引提高检索速度,改善数据库性能。
索引存在于系统的sysindexes表记录中。
分类:
| 索引名称 | 含义 | 备注 |
| 唯一索引 | 不允许两行具有相同索引值。若在某列上创建此索引后,则此列中数据无一重复 | 创建唯一约束时默认创建唯一索引 |
| 主键索引 | 每一个值非空且唯一 | 允许快速访问数据 |
| 聚集索引 | 按照物理顺序(例如页码)和索引顺序(例如a~z)排序 | 一个表最多只有一个聚集索引 |
| 非聚集索引 | 不按物理顺序(例如页码)和索引顺序(例如a~z)排序 | 一个表中可有多个非聚集索引 |
| 复合索引 | 将表中的多列组合为一个索引 |
|
| 全文索引 | 基于标记的功能性索引,比使用LIKE关键字搜索中文字符串快很多 |
|
创建索引:
CREATE [索引类型] INDEXindex_[索引名]
ON [表名]([列名])
WITH FILLFACTOR= [x]
FILLFACTOR表示“填充因子”,保留某些空间以便日后为添加的索引开辟空间
何时使用索引:
ü 频繁搜索的列
ü 经常用作查询的列
ü 经常排序、分组的列
ü 经常用作主外键连接的列
8. 唯一约束和主键约束的区别:
设置了唯一约束的列,列中可以有null值,但只要数据中的某一行有了null值后,其他数据行就不能再有null值了。
设置了主键约束的列,不仅列中不能出现null值,而且数据也不允许重复。
6. 存储过程
1. 概念:是SQL语句和控制语句的预编译集合。保存在数据库中,可随时被调用执行,且含有参数。
2. 优点:
ü 模块化
ü 执行速度快、效率高
ü 减少网络流量
ü 安全性高
3. 分类:

系统存储过程
ü 系统存储过程以“sp_”开头。
ü 系统扩展存储过程可执行CMD命令
例如:
EXEC xp_cmdshell ‘mkdirD:\Program Files’,NO_OUTPUT
mkdir 为 创建目录的命令
xp_cmdshell 调用它可使用cmd命令
用户自定义存储过程
ü 以“usp_”开头。
ü 语法:
CREATEPPROCEDURE[存储过程名]
[参数1名称] [参数1的数据类型] [OUTPUT],
[参数2名称] [参数2的数据类型] [OUTPUT],
……
[参数n名称] [参数n的数据类型] [OUTPUT]
AS
[SQL语句]
OUTPUT参数指定此参数是否要进行输出而用。
若不写OUTPUT则默认为传入的参数而用。
4. 调用存储过程的两种方法:
EXECUTE[存储过程名] [参数(可选)]
EXEC[存储过程名] [参数(可选)]















 555
555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









