







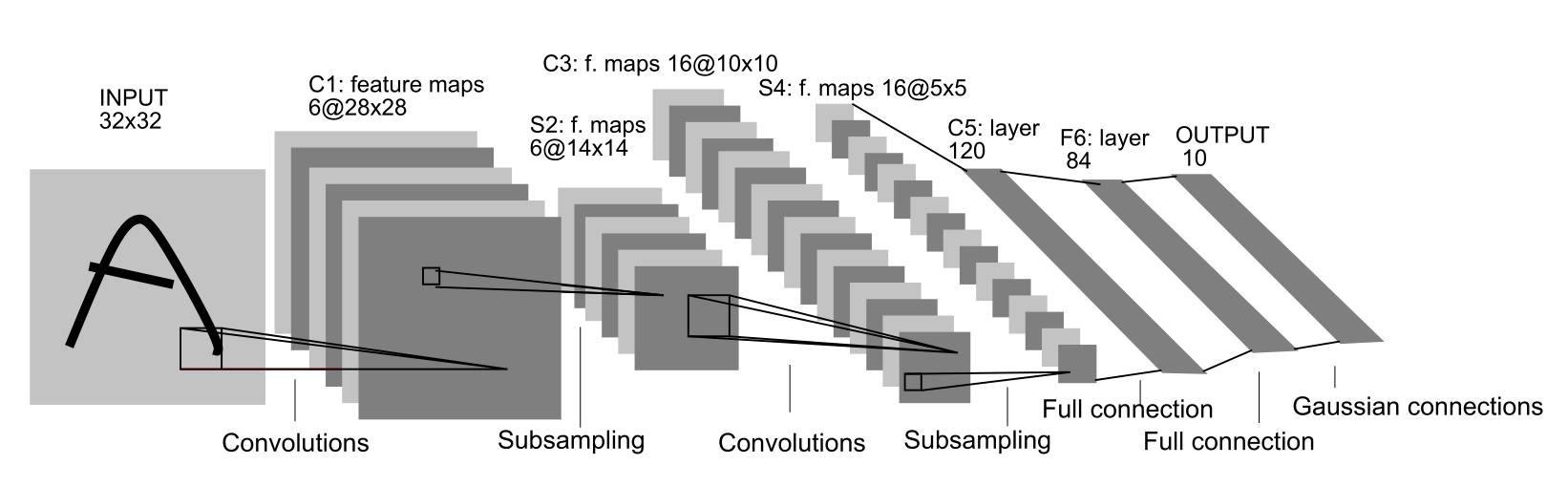
输入图像为32*32
C1:卷积层,滤波器6组5*5,输出28*28 *6 。训练参数(25个unit,1个偏置)。连接数156*28*28。神经元:28*28*6
S2:下采样,一个滤波器2*2,,输出14*14*6。参数6*2=12,(一个权重,一个偏置)。连接数:6*5*14*14=5880。14*14个神经元,过滤器处理一样
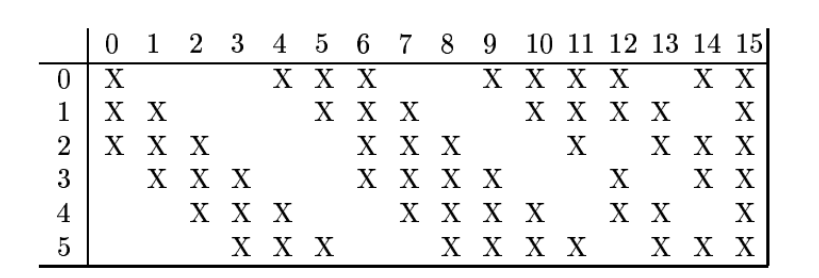
C3:卷积,60个滤波器,输出10*10。C3层的最开始的6个特征映射依赖于S2层的特征映射的每3个连续子集。接下来的6个特征映射依赖于S2层的特征映射的每4个连续子集。再接下来的3 个特征映射依赖于S2层的特征映射的每4个不连续子集。最后一个特征映射依赖于S2层的所有特征映射。这样共有60个滤波器,大小是5 × 5 = 25。得到16组大小为10×10 = 100的特征映射。C3层的神经元个数为16×100 = 1,600。可训练参数个数为 60 × 25 + 16 = 1,516。连接数为1,516 × 100 = 151,600。
S4:1个滤波器2*2,输出5*5*16。参数16*2。连接数16*5*25=2000。神经元25个。
C5:输出1*1*120。120*16个滤波器5*5。参数120*16*25+120=48120。连接数=48120。全连接
F6:84个单元(之所以选这个数字的原因来自于输出层的设计),与C5层全相连。有120*84+84=10164个可训练参数和连接数。全连接
输出层由欧式径向基函数(Euclidean Radial Basis Function)单元组成,每类一个单元,每个有84个输入。每个输出RBF单元计算输入向量和参数向量之间的欧式距离。输入离参数向量越远,RBF输出的越大。一个RBF输出可以被理解为衡量输入模式和与RBF相关联类的一个模型的匹配程度的惩罚项。用概率术语来说,RBF输出可以被理解为F6层配置空间的高斯分布的负log-likelihood。给定一个输入模式,损失函数应能使得F6的配置与RBF参数向量(即模式的期望分类)足够接近














 9202
9202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









