







LeNet-5网络简介
LeNet-5出自论文Gradient-Based Learning Applied to Document Recognition,是一种用于手写体字符识别的非常高效的卷积神经网络。是入门深度学习网络的基础网络,LeNet-5网络虽然小,但是包含了深度学习的基本模块:卷积层、池化层、全连接层。LeNet5共有七层,不包含输入,每层都包含可训练参数,每个层有多个Feature Map,每个Feature Map通过一种卷积滤波器提取输入的一种特征,然后每Feature Map有多个神经元。
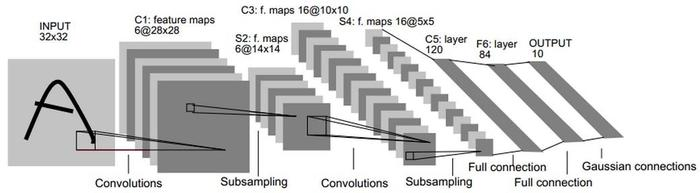
各个参数详解
1、 input层
输入图像的尺寸同一为32*32
2、C1层
输入图片:32*32
卷积核大小:5*5
卷积核个数:6
输出featuremap大小:(32-5+1)=28---->28*28
神经元数量:28286
可训练参数:(55+1) * 6(每个滤波器55=25个unit参数和一个bias参数,一共6个滤波器)
连接数:(55+1)62828=122304
详细说明:对输入图像进行第一次卷积运算(使用 6 个大小为 55 的卷积核),得到6个C1特征图(6个大小为2828的 feature maps, 32-5+1=28)。我们再来看看需要多少个参数,卷积核的大小为55,总共就有6(55+1)=156个参数,其中+1是表示一个核有一个bias。对于卷积层C1,C1内的每个像素都与输入图像中的55个像素和1个bias有连接,所以总共有1562828=122304个连接(connection)。有122304个连接,但是我们只需要学习156个参数,主要是通过权值共享实现的。
3、S2层-池化层(下采样层)
输入:28*28
采样区域:2*2
采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid
采样种类:6
输出featureMap大小:14*14(28/2)
神经元数量:14146
连接数:(22+1)61414
S2中每个特征图的大小是C1中特征图大小的1/4。
详细说明:第一次卷积之后紧接着就是池化运算,使用 22核 进行池化,于是得到了S2,6个1414的 特征图(28/2=14)。S2这个pooling层是对C1中的2*2区域内的像素求和乘以一个权值系数再加上一个偏置,然后将这个结果再做一次映射。同时有5x14x14x6=5880个连接。
4、C3层-卷积层
输入:S2中所有6个或者几个特征map组合
卷积核大小:5*5
卷积核个数:16
输出featureMap大小:10*10 (14-5+1)=10
C3中的每个特征map是连接到S2中的所有6个或者几个特征map的,表示本层的特征map是上一层提取到的特征map的不同组合
存在的一个方式是:C3的前6个特征图以S2中3个相邻的特征图子集为输入。接下来6个特征图以S2中4个相邻特征图子集为输入。然后的3个以不相邻的4个特征图子集为输入。最后一个将S2中所有特征图为输入。
则:可训练参数:6*(355+1)+6*(455+1)+3*(455+1)+1*(655+1)=1516
连接数:10101516=151600
5、S4层-池化层(下采样层)
输入:10*10
采样区域:2*2
采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid
采样个数:16
输出featureMap大小:5*5(10/2)
神经元数量:5516=400
连接数:16*(2*2+1)55=2000
S4中每个特征图的大小是C3中特征图大小的1/4
详细说明:S4是pooling层,窗口大小仍然是2*2,共计16个feature map,C3层的16个10x10的图分别进行以2x2为单位的池化得到16个5x5的特征图。有5x5x5x16=2000个连接。连接的方式与S2层类似。
6、C5层-卷积层
输入:S4层的全部16个单元特征map(与s4全相连)
卷积核大小:5*5
卷积核个数:120
输出featureMap大小:1*1(5-5+1)
可训练参数/连接:120*(1655+1)=48120
详细说明:C5层是一个卷积层。由于S4层的16个图的大小为5x5,与卷积核的大小相同,所以卷积后形成的图的大小为1x1。这里形成120个卷积结果。每个都与上一层的16个图相连。所以共有(5x5x16+1)x120 = 48120个参数,同样有48120个连接。
7、F6-全连接层
输入:c5 120维向量
计算方式:计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过sigmoid函数输出。
可训练参数:84*(120+1)=10164
8、output层
Output层也是全连接层,共有10个节点,分别代表数字0到9,且如果节点i的值为0,则网络识别的结果是数字i。采用的是径向基函数(RBF)的网络连接方式。假设x是上一层的输入,y是RBF的输出,则RBF输出的计算方式是:
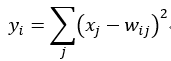
上式w_ij 的值由i的比特图编码确定,i从0到9,j取值从0到7*12-1。RBF输出的值越接近于0,则越接近于i,即越接近于i的ASCII编码图,表示当前网络输入的识别结果是字符i。该层有84x10=840个参数和连接。
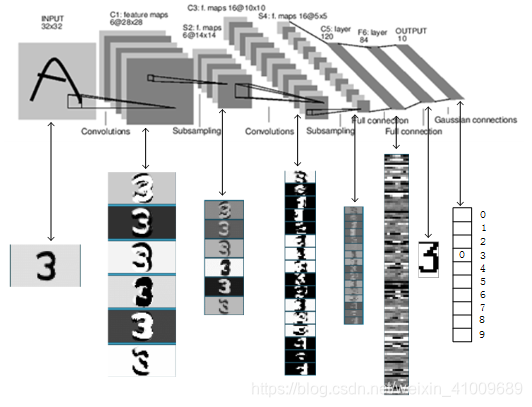
上图是LeNet-5识别数字3的过程。
Pytorch实现
LeNET_5.py
import torch
import torch.nn as nn
import torch.optim as optim
import pandas as pd
import pandas.util
import matplotlib.pyplot as plt
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1),
nn.MaxPool2d(kernel_size=2)
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1),
nn.MaxPool2d(kernel_size=2)
)
self.fc1 = nn.Sequential(
nn.Linear(in_features=4 * 4 * 16, out_features=120)
)
self.fc2 = nn.Sequential(
nn.Linear(in_features=120, out_features=84)
)
self.fc3 = nn.Sequential(
nn.Linear(in_features=84, out_features=10)
)
def forward(self, input):
conv1_output = self.conv1(input) # [28,28,1]-->[24,24,6]-->[12,12,6]
conv2_output = self.conv2(conv1_output) # [12,12,6]-->[8,8,16]-->[4,4,16]
conv2_output = conv2_output.view(-1, 4*4*16) # [n,4,4,16]-->[n,4*4*16],其中n代表个数
fc1_output = self.fc1(conv2_output) # [n,256]-->[n,120]
fc2_output=self.fc2(fc1_output) # [n,120]-->[n,84]
fc3_output = self.fc3(fc2_output) # [n,84]-->[n,10]
return fc3_output
# 模型建立好了,下面进行训练
##############################################################
train_data = pd.DataFrame(pd.read_csv(r'C:\Users\zs\Desktop\python_practice\classical_model\data\mnist_train.csv'))
model = LeNet()
loss_fc = nn.CrossEntropyLoss() # 定义损失函数
optimizer = optim.SGD(params=model.parameters(), lr=0.001) # 采用随机梯度下降SGD
loss_list = [] # 记录每次的损失值
x = [] # 记录训练次数
for i in range(900):
batch_data = train_data.sample(n=30, replace=False) # 每次随机读取30条数据 sample(序列a,n)功能:从序列a中随机抽取n个元素,并将n个元素生以list形式返回
batch_y = torch.from_numpy(batch_data.iloc[:, 0].values).long() # 标签值
batch_x = torch.from_numpy(batch_data.iloc[:, 1::].values).float().view(-1, 1, 28, 28)
# 图片信息,一条数据784维将其转化为通道数为1, 大小为28*28的图片
prediction = model.forward(batch_x) # 向前传播
loss = loss_fc(prediction, batch_y) # 计算损失值
optimizer.zero_grad() # 将梯度置为零,在每次进行误差反传时应该先置零
loss.backward() # 反向传播
optimizer.step() # 更新权重
print('第%d次训练, loss=%.3f' % (i, loss))
loss_list.append(loss)
x.append(i)
torch.save(model.state_dict(), 'LeNet.pkl') # 保存模型参数
plt.figure()
plt.plot(x, loss_list, 'r-') # 可以将损失值进行绘制
plt.show()
#############在下一个文件里将训练好的模型用于测试数据进行测测试
####### 下面进行测试 LeNet_test.py
import torch
import torch.nn as nn
from LeNET_5 import LeNet
import pandas as pd
import numpy as np
model = LeNet()
test_data = pd.DataFrame(pd.read_csv(r'C:\Users\zs\Desktop\python_practice\classical_model\data\mnist_test.csv'))
model.load_state_dict(torch.load('LeNet.pkl')) # 加载模型参数
with torch.no_grad(): # 测试不需要反向传播
batch_data = test_data.sample(n=50, replace=False)
batch_x = torch.from_numpy(batch_data.iloc[:, 1::].values).float().view(-1, 1, 28, 28)
batch_y = batch_data.iloc[:, 0].values
prediction = np.argmax(model(batch_x).numpy(), axis=1) # 在pytorch中.numpy()的意思是将tensor转化为numpy
print(prediction)
for i in range(100):
batch_data = test_data.sample(n=50, replace=False)
batch_x = torch.from_numpy(batch_data.iloc[:,1::].values).float().view(-1,1,28,28)
batch_y = batch_data.iloc[:, 0].values
prediction = np.argmax(model(batch_x).numpy(),axis=1)
acccurcy = np.mean(prediction == batch_y)
print("第%d组测试集,准确率为%.3f" % (i, acccurcy))
下面给出数据集的下载地址
链接:https://pan.baidu.com/s/15GALKfgK2LLXBNit2lHXcg
提取码:ooca














 142
142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









