







刘子健 +
原创作品转载请注明出处 +
《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
题目自拟,内容围绕操作系统是如何工作的进行;
博客中需要使用实验截图
博客内容中需要仔细分析进程的启动和进程的切换机制
总结部分需要阐明自己对“操作系统是如何工作的”理解
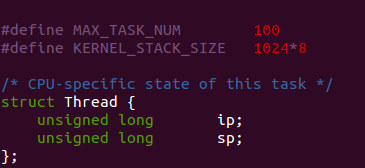
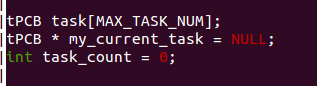
这里struct Thread有两个member 组成,特意的,用了unsigned long 类型的数据,就是为了取得机器指针长度一致的数据.这里的ip,即instruction pointer , 而sp为stack pointer.分别用来指示当前进程的下一条指令的地址和栈顶指针.
接着,定义结构体struct PCB,这里的PCB应该不是玩硬件同学熟悉的印刷电路板的那个PCB(printed circuit board)
对应的英语全称偶也不是很清楚,不过有一点可以肯定,这个结构体对应着Linux内核里的struct task.
意义在于为进程提供抽象数据结构,把需要描述进程的元素统统用这个结构体封装起来.
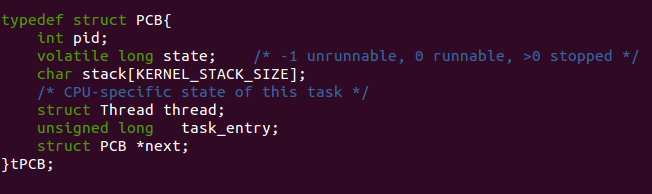
呵呵,老师也是良苦用心,这么精简,要知道,真正的struct task有近1000行,一个结构体的定义就1000+行.
state 有三种情况,0为正在运行的进程,-1表示不可运行,大于0则表示进程停止了.
这是Mykernel的进程描述情况,
真正的Linux的Process state有五种.


OK, 头文件pcb.h搞定了.然后分析mymain.c
看看my_start_kernel()函数
void __init my_start_kernel(void)
{
int pid = 0;
/* Initialize process 0*/
task[pid].pid = pid;
task[pid].state = 0;/* -1 unrunnable, 0 runnable, >0 stopped */
// set task 0 execute entry address to my_process
task[pid].task_entry = task[pid].thread.ip = (unsigned long)my_process;
task[pid].thread.sp = (unsigned long)&task[pid].stack[KERNEL_STACK_SIZE-1];
task[pid].next = &task[pid]; //构造一个链表
/*fork more process */
for(pid=1;pid<MAX_TASK_NUM;pid++)
{ //这里主要是对每个进程的数据结构进行初始化,把所有初始进程除了进程0,都设置为不可运行
memcpy(&task[pid],&task[0],sizeof(tPCB));
task[pid].pid = pid;
task[pid].state = -1;
task[pid].thread.sp = (unsigned long)&task[pid].stack[KERNEL_STACK_SIZE-1];
task[pid].priority=get_rand(PRIORITY_MAX);//each time all tasks get a random priority 进程优先级
}
task[MAX_TASK_NUM-1].next=&task[0];
printk(KERN_NOTICE "\n\n\n\n\n\n system begin :>>>process 0 running!!!<<<\n\n");
/* start process 0 by task[0] */
pid = 0;
my_current_task = &task[pid];
asm volatile(
"movl %1,%%esp\n\t" /* set task[pid].thread.sp to esp */
"pushl %1\n\t" /* push ebp */
"pushl %0\n\t" /* push task[pid].thread.ip */
"ret\n\t" /* pop task[pid].thread.ip to eip */
"popl %%ebp\n\t"
:
: "c" (task[pid].thread.ip),"d" (task[pid].thread.sp) /* input c or d mean %ecx/%edx*/
);
}
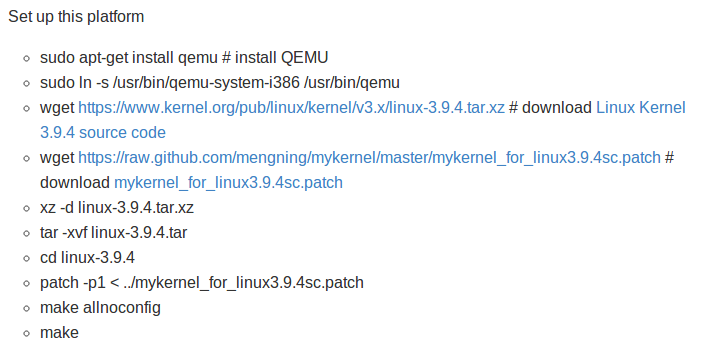
这个时候我们最好一步步的跟踪内核代码,这样体会会更加深刻(虽然Linus大神完全不提倡用调试器,but他是对内核维护的那批神人说的啊,吾辈啥都不知道的时候还是利用神器-qemu帮助自己学习内核吧, 不然你看再多代码可能也没感觉)
首先去./linux-3.13.1/目录下修改好configure文件,是为了方便gdb调试,不然哥们没有提示符很坑爹哦~
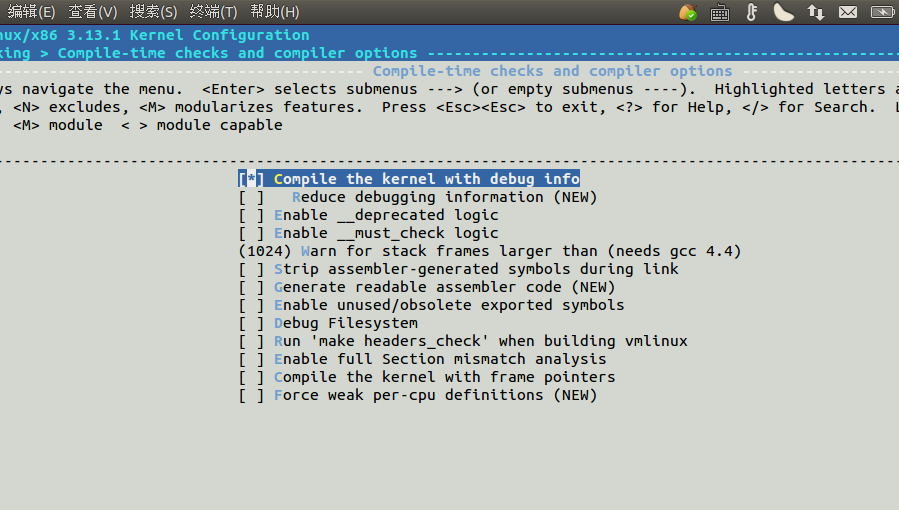
make menuconfig
然后你会看到一个图形界面的内核配置选项菜单
然后进入到kernel debugging
然后再去把选项Compile the kernel with debug info(CONFIG_DEBUG_INFO)打钩
看这样就可以在gdb里面调试内核代码了
我们在my_start_kernel函数处设置个断点
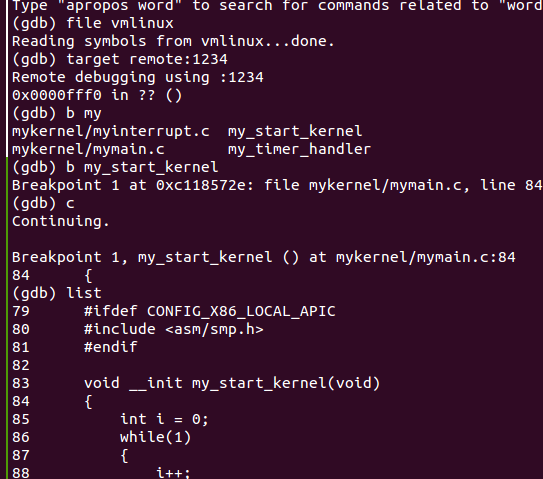
具体的如何用qemu和gdb调试内核,我特意做了笔记如下面的link:
http://blog.csdn.net/cinmyheart/article/details/44249291
如果你跟我一样,是用全新的源码搭建环境的话,记得一定要修改内核代码根目录下的Makefile
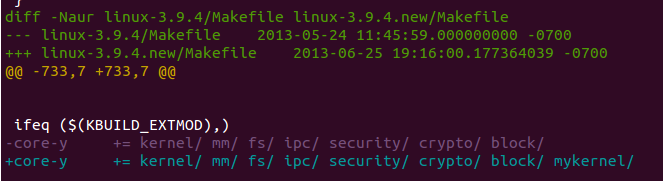
之前我就一直很奇怪,为什么我编译的内核始终是没有编译自己新添加的文件的,这时候明白了,忘记修改Makefile了.
下面是我的3.13.1版本内核里面Makefile的部分截图.记得一定把你要编译的目录添加到core-y里面去!不然你debug的时候总会觉得奇怪,为嘛自己添加代码了但是没有编译.

如果你用的新的源代码.记得还要做一下几件事情.
1.
/arch/x86/kernel/time.c里面添加头文件
#include <linux/timer.h>
2.下面约定,找到相应的文件路径,然后添加带有+开头的代码行.
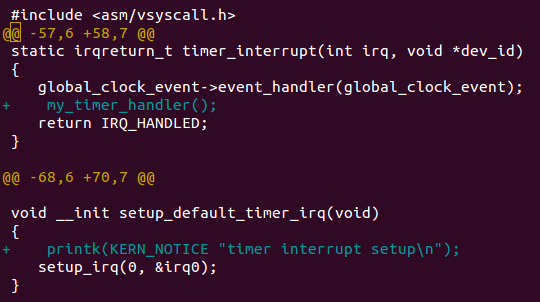
3.
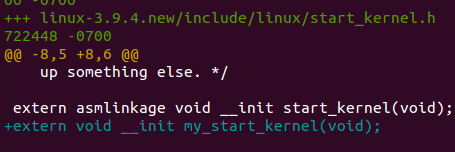
4.

5.这里可以特别注意到,在init/main.c里面添加了my_start_kernel()
旨在让初始化结束后的引导过程进入my_start_kernel(),我们自己写的函数.
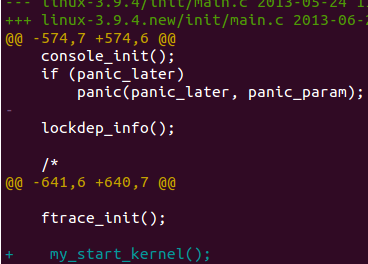
最后把mykernel文件夹放到新的内核源代码目录树下面就OK啦
在my_start_kernel()里面,下面是一段嵌入式汇编,旨在切换堆栈(movl %1 %%esp),然后保存当前进程的堆栈指针和指令指针,最后把进程为pid的堆栈设置为esp新的值.还有指令指针也更新为pid进程的指针.
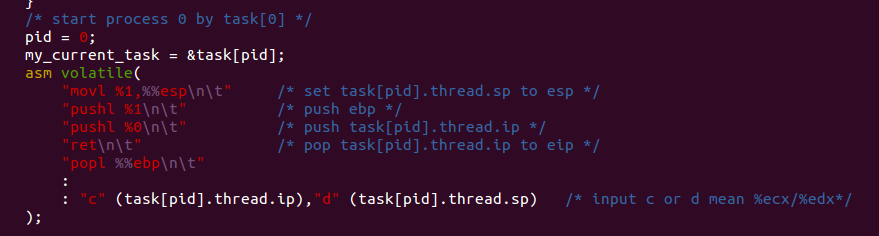
至于%1 %0是嵌入式汇编,这里可以看到图中的后面部分有两个分号,那里是特指明输入输出寄存器的.
"c" (task[pid].thread.ip)被特别声明,用ecx寄存器来储存task[pid].thread.ip的值,并且可以用%0引用这个值,
同理,edx寄存器来储存task[pid].thread.sp的值
如果对嵌入式汇编不熟悉,传送门在这里:
http://blog.csdn.net/cinmyheart/article/details/24967455
接着会进入my_process函数,这里就是个暴力时间迭代,如果变量i一直++到10000000,然后可以进入if判断,
当前进程就让出CPU.
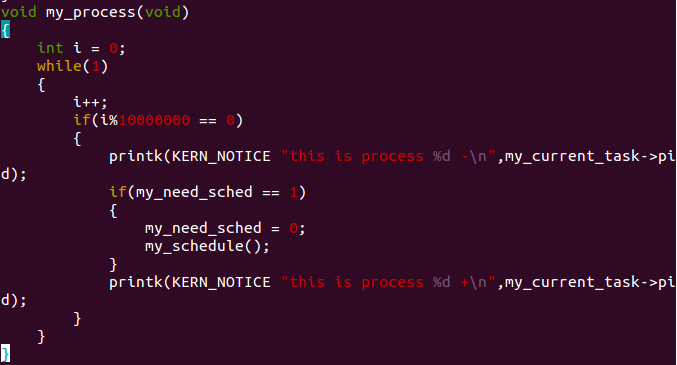
在mykernel/myinterrupt.c里,有定义好的全局变量,这个变量默认为0,那么之前从未有改变这个变量的值,因此你会发现,这个

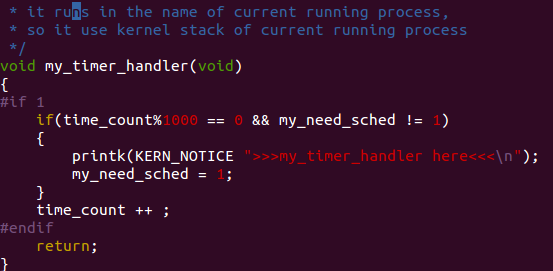
my_timer_handler作为一个定时器,每次time_count自增到1000的倍数,然后当前进程不需要进程切换的话,那么我们把my_need_sched置为1,我们将要切换进程,如果my_need_sched本来就是1,那么啥也不需要干
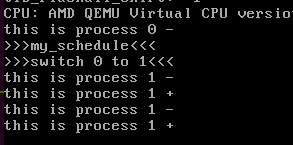
一开始进程0就会切换到进程1而后,进程1会不断的尝试切换到进程2但是一段时间内不会成功,只有当my_need_sched等于1的时候,进程才会切换.而这需要定时器处理函数进入if(),将my_need_sched置为1.条件就是time_count自增1000次.
看你定时器多块啦~
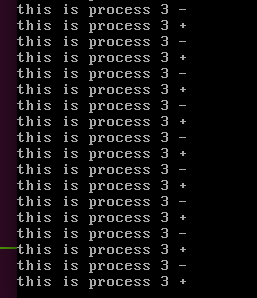
下面是当进程切换到进程3的时候进程不但尝试切换到其他进程(this process 3 -),但是不成功,于是又回到(this process 3+)
博客内容中需要仔细分析进程的启动和进程的切换机制:
之前玩过一点JOS,从系统上电的那一刹那, 除了CS段是0xFFFF之外,其他的段寄存器都是0x0000.故事从这里开始.
而后便是一系列的初始化过程,init/main.c里面作为初始化的主程序,会调用各种不同的初始化程序.基本上初始化OK了,那么就可以开始创建进程关系链接,以及进程切换的事情了.玩过单片机的童鞋应该很清楚,有时候很喜欢写个while(1)的死循环,其实在内核里面,系统开始运行了就是个大的while(1),只是在这里面各种花样太多了.呵呵.进程是为了抽象CPU,让某一个进程去集中做一件事情,而当运行计算单元(CPU)比较少时,我们可以一步步的做,保存现场,进程见相互切换,实现一个CPU或者比较少的CPU可以"同时"做很多事情.
传统的,单核计算机的并发就是不停的切换任务.造成一种并行的假象.到后来正在多核CPU的时候才会正真意义上的并行计算.
就这么多吧,不然又唧唧歪歪不停的啰嗦.
总结部分需要阐明自己对“操作系统是如何工作的”理解
操作系统嘛~草鸡好玩的东东.宏观的意义上来说,这层软件把硬件设备处理的非常非常好,以至于,人们可以不用去管硬件实现,直接和计算机进行交互.通过编程语言.借助操作系统的系统调用,完成你想做的事情.不用去管底层实现.
如何工作?这要扯扯体系结构的东东,不同的硬件平台,可能初始化的过程不一样,但是只要完成初始化的过程,后面的系统调度策略都是一样的.
系统从BIOS(这家伙叫basic input and output system),储存在永久记忆的储存芯片里面,记忆这关于计算机硬件的很基本的信息,比方说,最大的内存容量是多少等等,有兴趣的话,可以去看看Linux设备驱动里面,我写了个读取CMOS信息的驱动.
从BIOS获取基本的硬件信息之后,就会利用这些信息,对硬件进行必要的初始话工作.完成之后,操作系统的特定部分软件就开始维护,并运行这个硬件.而后就可以工作使用啦~
对于Operating system还木有神马概念的话,推荐看看<<Modern Operating system>>.很好的概念性的书籍.实际动手的话推荐赵炯博士的Linux内核源码注释0.11(我也是水,还没看完.)然后可以玩玩草鸡棒的JOS.JOS这家伙也不是好惹的.呵呵...
Have fun : )
















 803
803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









