







Self-taught leaning是用的无监督学习来学习到特征提取的参数,然后用有监督学习来训练分类器。这里无监督学习和有监督学习分别是用的sparse autoencoder和softmax regression.
如果已经有一个足够强大的机器学习算法,为了获得更好的性能,最靠谱的方法之一是给这个算法以更多的数据。机器学习界甚至有个说法:“有时候胜出者并非有最好的算法,而是有更多的数据。”
人们总是可以尝试获取更多的已标注数据,但是这样做成本往往很高。例如研究人员已经花了相当的精力在使用类似 AMT(Amazon Mechanical Turk) 这样的工具上,以期获取更大的训练数据集。相比大量研究人员通过手工方式构建特征,用众包的方式让多人手工标数据是一个进步,但是我们可以做得更好。具体的说,如果算法能够从未标注数据中学习,那么我们就可以轻易地获取大量无标注数据,并从中学习。自学习和无监督特征学习就是这种的算法。尽管一个单一的未标注样本蕴含的信息比一个已标注的样本要少,但是如果能获取大量无标注数据(比如从互联网上下载随机的、无标注的图像、音频剪辑或者是文本),并且算法能够有效的利用它们,那么相比大规模的手工构建特征和标数据,算法将会取得更好的性能。
在自学习和无监督特征学习问题上,可以给算法以大量的未标注数据,学习出较好的特征描述。在尝试解决一个具体的分类问题时,可以基于这些学习出的特征描述和任意的(可能比较少的)已标注数据,使用有监督学习方法完成分类。
在一些拥有大量未标注数据和少量的已标注数据的场景中,上述思想可能是最有效的。即使在只有已标注数据的情况下(这时我们通常忽略训练数据的类标号进行特征学习),以上想法也能得到很好的结果。
特征学习
我们已经了解到如何使用一个自编码器(autoencoder)从无标注数据中学习特征。具体来说,假定有一个无标注的训练数据集 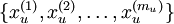 (下标
(下标 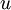 代表“不带类标”)。现在用它们训练一个稀疏自编码器(可能需要首先对这些数据做白化或其它适当的预处理)。
代表“不带类标”)。现在用它们训练一个稀疏自编码器(可能需要首先对这些数据做白化或其它适当的预处理)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 604
604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









