









潘嘉林Sinno (Sinno Jialin Pan)在会议ACML最新一届上做了一个讲座
OAMLS -- Transfer Learning -- Sinno Jialin Pan
The 13th Asian Conference on Machine Learning(ACML)官网:
HKUST资源:
slide:
http://www.lamda.nju.edu.cn/conf/mla16/slides/pans-slides.pdf
视频地址
https://www.youtube.com/watch?v=9UiKV2i1TPM

主要内容:
1.迁移学习的定义
2.迁移学习的分类

目录
迁移学习的使用场景
迁移学习是一种较新的机器学习方法(paradigm)


使训练集(环境)中学到的模型可以用在将来的同一个环境

传统方法在环境改变后, 重新搜集训练数据, 训练新的模型. 开销很大.
Wifi定位例子

定位模型的输入: 对应时间的每个AP接收信号强度
输出: 移动设备的位置
训练回归模型, 通过定位点与真实点的误差距离来计算loss
采集数据
信号强度在不同的时期, 不同的移动设备上会发生变化.

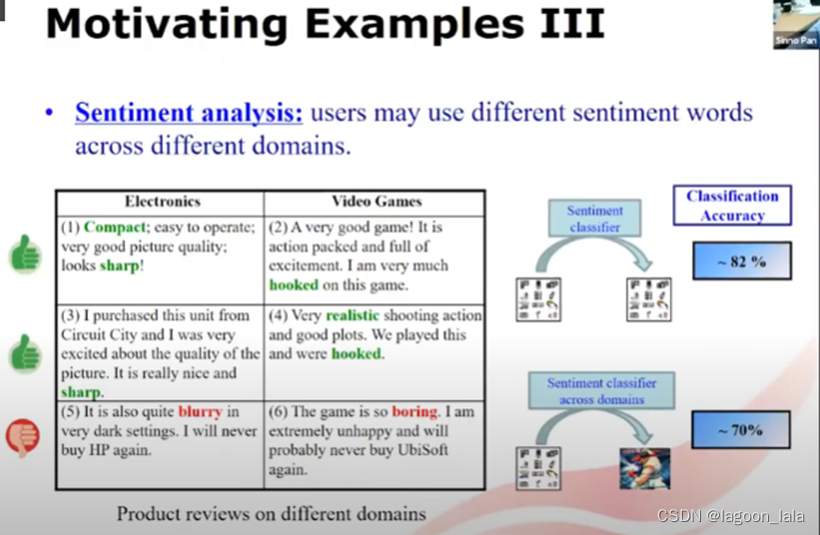
情绪分析例子
输入句子
输出情绪积极/消极
分类模型
两个域: 电子产品评论/游戏评论
监督学习的假设
监督学习的假设: 训练集和测试集在同一个特征空间, 服从相同特征分布


监督学习的目标: 最小化经验风险, 即最小化损失的期望

在训练数据上引入概率, 重写这个期望
其中P_tst代表文本数据的概率分布(probability distribution of text data),
P_trn代表训练数据的概率分布(probability distribution on the training data)
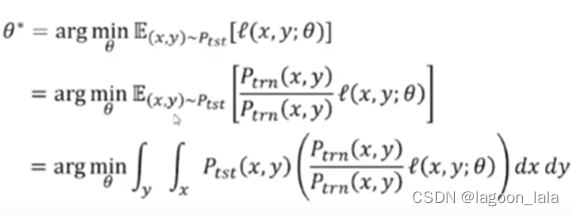
代入期望的定义重写这个式子
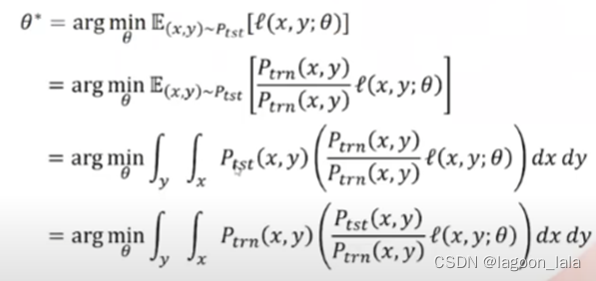
重新排列两个分子(Ptst, Ptrn)位置

再次使用期望定义
模型在学习最小化期望, 即中括号内的这一项
基于假设: 训练集分布即为全数据集分布
即x, y的联合概率在全数据集和训练集相同, 除项为1, 可以消掉

消掉之后可以写作

所得式子含义为:
进行优化求解时,
最小化全数据集分布上的loss的期望,
等价于,
学习一个模型, 最小化训练集上loss的期望.
(理想情况下, 是基于全数据集的分布, 优化loss, 也等价于基于训练集的分布, 优化loss*全数据集分布/训练集分布)
即使我们没有得到全数据集, 只要训练集数据充分, 就可以通过训练集得到的模型来预测全数据集.
这就是监督学习需要这个强假设的原因. (训练集分布和测试集分布相同)
迁移学习的假设
在实际情况中, 训练集和测试集来自于不同的域, 所以在不同的特征空间, 有不同的数据分布.

所以监督学习的假设在实际情况不成立

在训练集上, 通过最小化损失期望来训练的模型, 可能在测试集上表现得不好.
因为右式的最优解不一定是左式的最优解(optimal solutions)

左侧为源任务(source task)或源领域(source domain)
右侧为目标任务(target task)或目标领域(target domain)
源域和目标域的数据可能有不同的数据分布, 源域训练的模型之间用在目标域上可能效果不好.
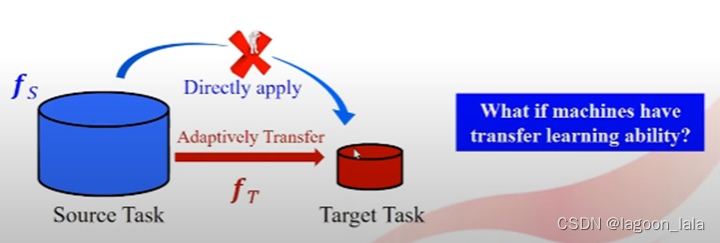
从源域适应性地迁移到目标域, 是机器学习中的迁移学习目的.
当目标域数据量小时, 可以使用源域数据训练模型, 用在目标域上.
给定一个目标域/任务, 迁移学习的目的

1.识别源域目标域共性/共同存在的知识
2.使用这个共性, 将知识从源域迁移到目标域, 使目标域能训练出更强的分类器
迁移的过程

假设目标域可以获取无标签训练数据, 和少量有标签数据.
源域已经收集充分多的数据
源域和目标域都可以有一个或多个
迁移的目标是分析两个域的共性, 训练迁移算法, 使源域数据训练的模型能够适应目标域
迁移学习与机器学习区别
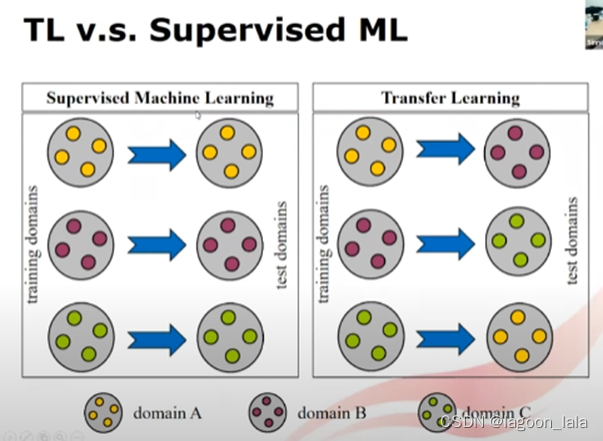
机器学习将学到的知识用在同一个领域. 当在其它领域使用时, 需要重复这个学习过程
迁移学习在一个域上有足够数据, 在另一个域可以利用之前域学到的知识. 而不是从头收集数据.
强化与预测两种任务的迁移学习

1.强化学习的迁移(可参考这篇综述)
2.分类/回归问题的迁移(本节主要研究)
迁移学习与主动学习, 半监督学习的区别

1.在目标任务的有标记数据稀缺的问题上, 都可以使用
2.它们的策略/假设不同
3.可以结合起来提高标签数据稀少时候学习的效果
半监督学习
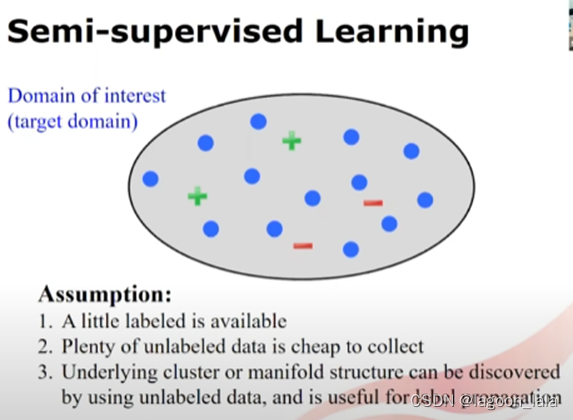
半监督学习的假设
1.有少量有标签数据
2.大量无标签数据
3.隐含有簇或流形结构(manifold structure), 可以通过无标签数据得到, 并且可以进行标签传播(label propagation). 通过传播标签, 可以学习对应领域精确的预测模型.
主动学习
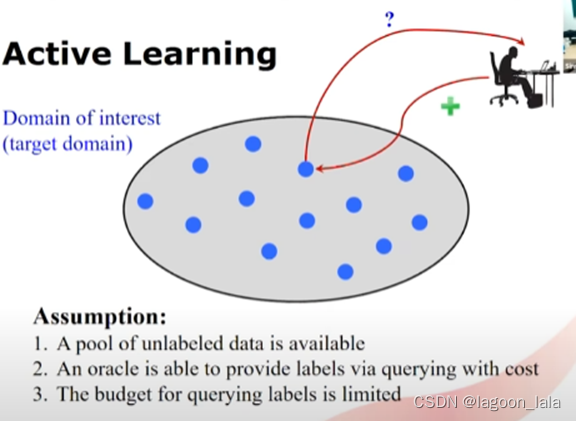
1.有大量无标签数据
2.可以通过oracle有开销地查询得到标签
3.查询标签的开销预算有限制
主动学习的通过有标准地选择一小部分样本, 查询标签, 得到精确的模型.
其关键问题是如何选择数据
迁移学习

1.目标域有标签数据少, 或无标签
2.源域数据有标签数据充足
3.在进行自适应操作后, 源域数据可用于学习目标域的分类任务
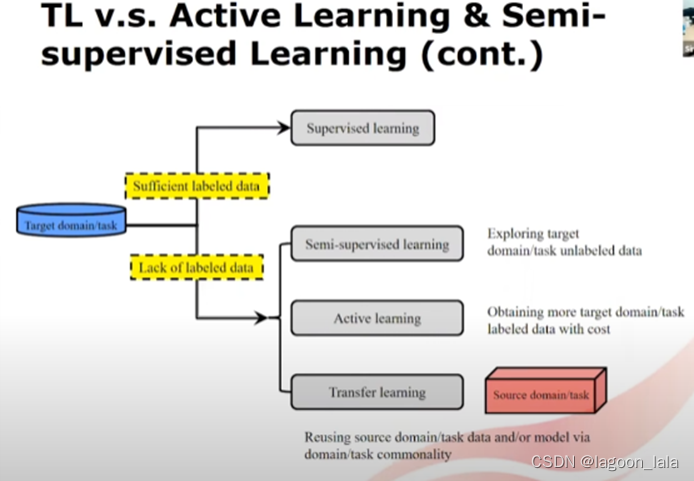
当可以收集足够的有标签数据, 可以直接使用监督学习
如果缺少有标签数据, 可以使用以上提到的三种方法.
其中半监督对目标域无标签数据打标签
主动学习有开销地生成更多目标域标签数据
迁移学习重用源域的数据或模型, 通过域/模型的共性
迁移学习与多任务学习
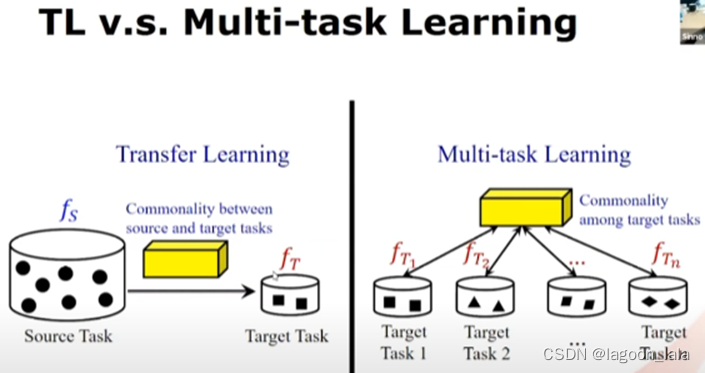
迁移学习:
有一个特定的目标域/任务, 源域已经有大量数据
迁移的目的是使用源域与目标域的共性, 为目标域建立一个精确的模型.
多任务学习:
没有源域, 可能有多个目标域, 每个目标域只有少量数据
多任务学习的目的是导出多个目标域之间的共性, 提高每个目标域的性能. (需要确保所有任务的性能都得到改进)
两者相似之处:
都是要利用不同域/任务的共性, 泛化不同任务/领域的性能
不同的迁移学习设置(settings)

根据特征空间的不同进行分类
同构(homogeneous)/异构(heterogeneous)
迁移学习和领域自适应的关系
领域自适应可以看成迁移学习的一个特例, 自监督学习(self supervised learning)
迁移学习中研究的问题
迁移先找到不同领域的共性, 再基于这个共性进行不同领域, 不同任务的知识转移.

1.迁移什么: 找到源域目标域的共性
2.如何迁移: 开发迁移的算法
3.什么时候迁移
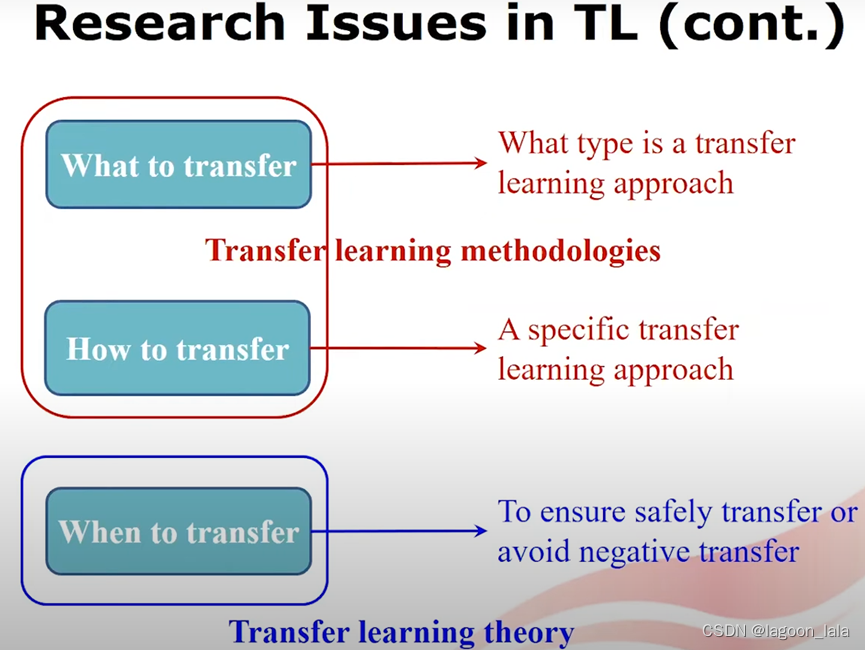
前两个问题与迁移学习方法有关, 后一个问题与迁移学习的理论有关
1.迁移什么: 确定用哪种类型的迁移学习方法
2.如何迁移: 确定特定的迁移方法
3.什么时候迁移: 保证安全的迁移, 避免负迁移
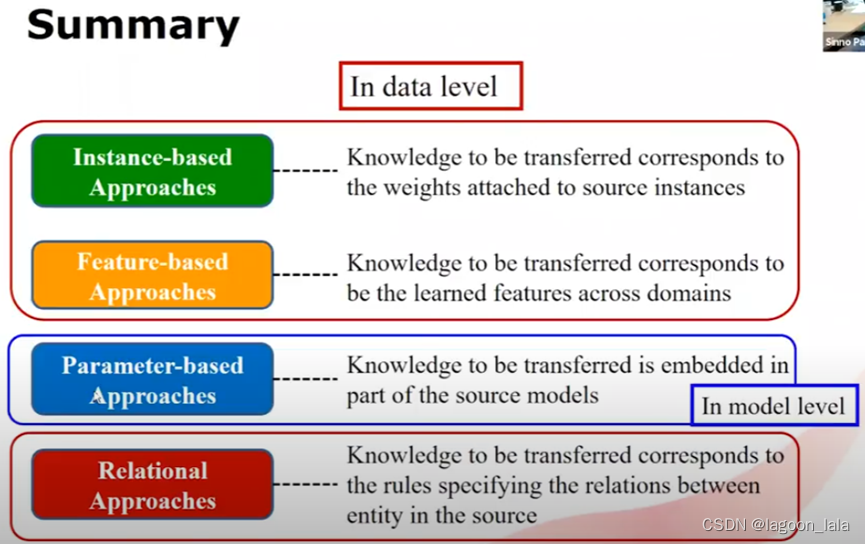
四种类型的迁移方法

基于样本,基于特征,基于参数,基于关系
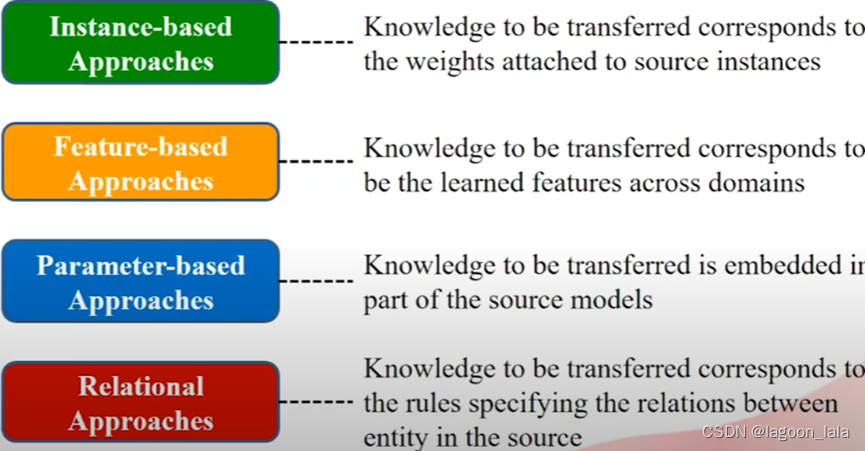
基于样本
基于样本的迁移, 需要学习的知识是源域样本的权重(典型的有前段时间论文里看到的TrAdaboost)
基于特征
要学习的知识是跨不同域或任务的共同特征
基于参数
知识嵌入在源域训练出的模型中, 将模型从源域迁移到目标域
基于关系
重点在于关系.
样本不是独立同分布的, 而是与其它每个样本都有关系
要迁移的知识是描述源域中每个样本的关系的规则
基于样本
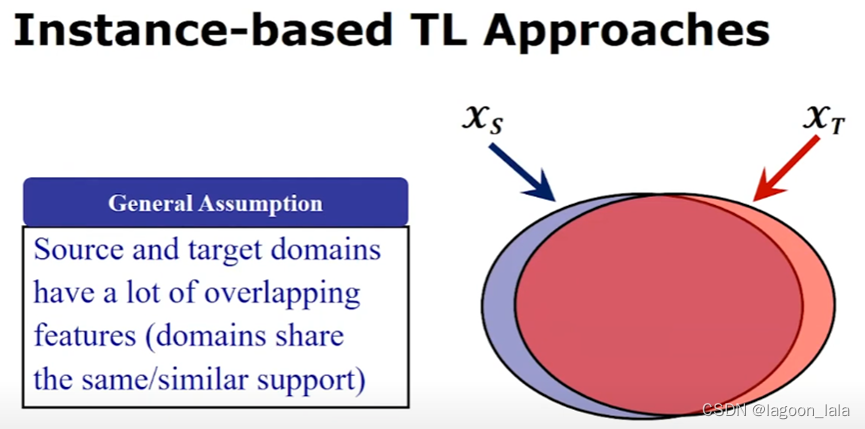
迁移学习早期阶段出现比较多的算法
假设: 源域与目标域有很多重叠特征, 并且值的大小相似(have a similar scale of values)
这个假设在实际情况常常不成立

样本迁移的两类算法
1.除了样本迁移的大假设, 还假设源域与目标域数据的条件概率相同(类似的输入特征能得到类似的标签), 但边缘分布不同相同(样本特征的分布不同). (这里原PPT有个笔误, 后面一个式子是不等号)
2.不假设源域与目标域数据的条件概率相同(即相同的输入特征可以得到不同的输出标签)
第一类样本迁移

定位46:00, 因为时间紧张, 先略过. 但是和稳定学习目前的思想有点像, 所以最好还是再回来看下.

这里面也介绍了TrAdaboost, 定位1:00:00
基于特征
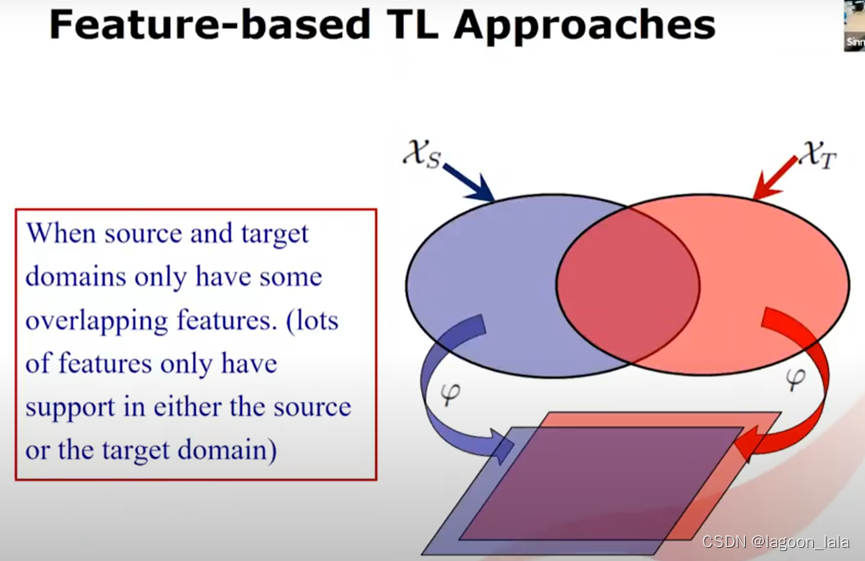
源域和目标域只有一些重叠特征(大多数特征只能用于预测源域和目标域中的其中一个)
此时, 基于样本的迁移不起作用, 考虑基于特征的迁移
总的想法是对源域和目标域进行转换/映射, 到一个共同的潜在的组合特征空间
在这个潜在空间(隐空间)中, 源域和目标域之间的差异减小
如何转换到这个隐空间:
对于相同的特征, 如果在一个域中的值的范围为0~10, 另一个域-100~-10, 则可以认为支持(support)不同.

下面介绍两种常用的方法
1.通过最小化两个域的差异学习特征. 最小化隐空间中域之间的差异
2.使用通用特征. 即每个域都表现良好的特征
TCA为例介绍第一种方法
任务为WiFi定位问题
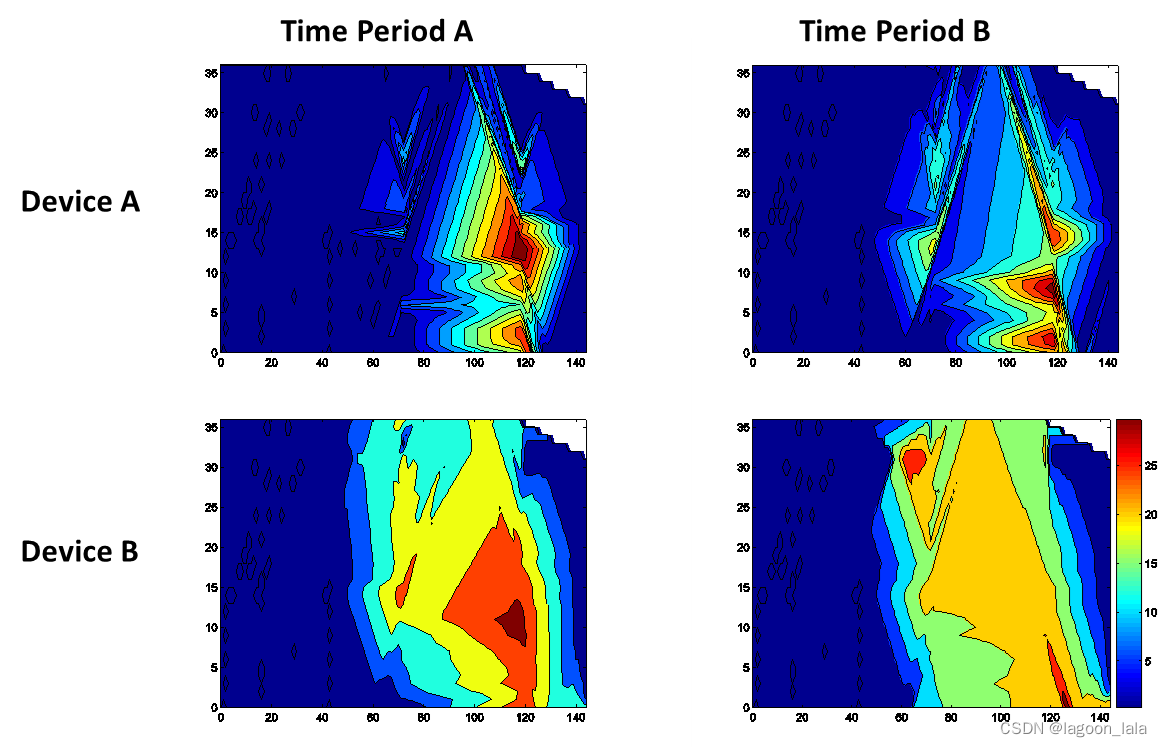
图为信号强度的轮廓, 在两个时段, 两种设备上变化很大.
每个样本中输入的特征数量=环境中部署的资产(assets, 如路由器)数量
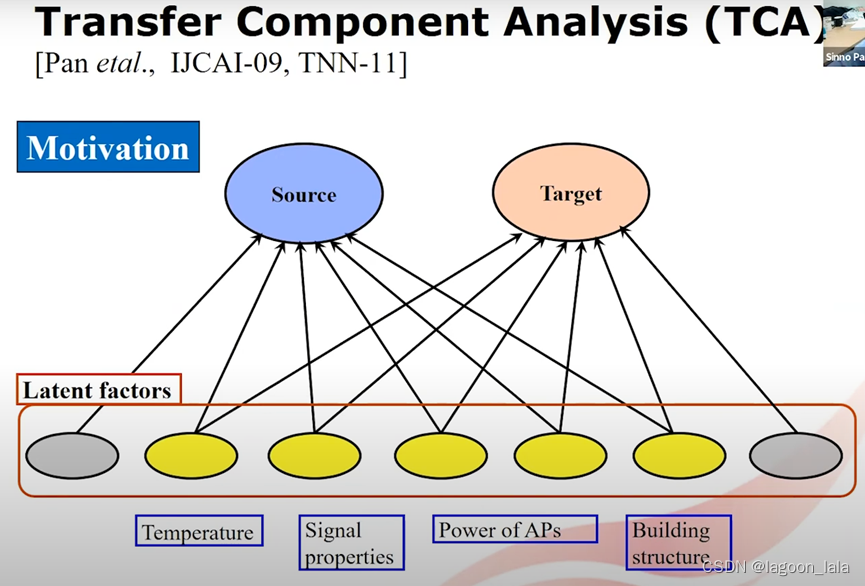
建筑内的资产数有上百个, 为高维特征. 但是这个高维观察(high dimension observation)可以通过少量隐空间特征表示.
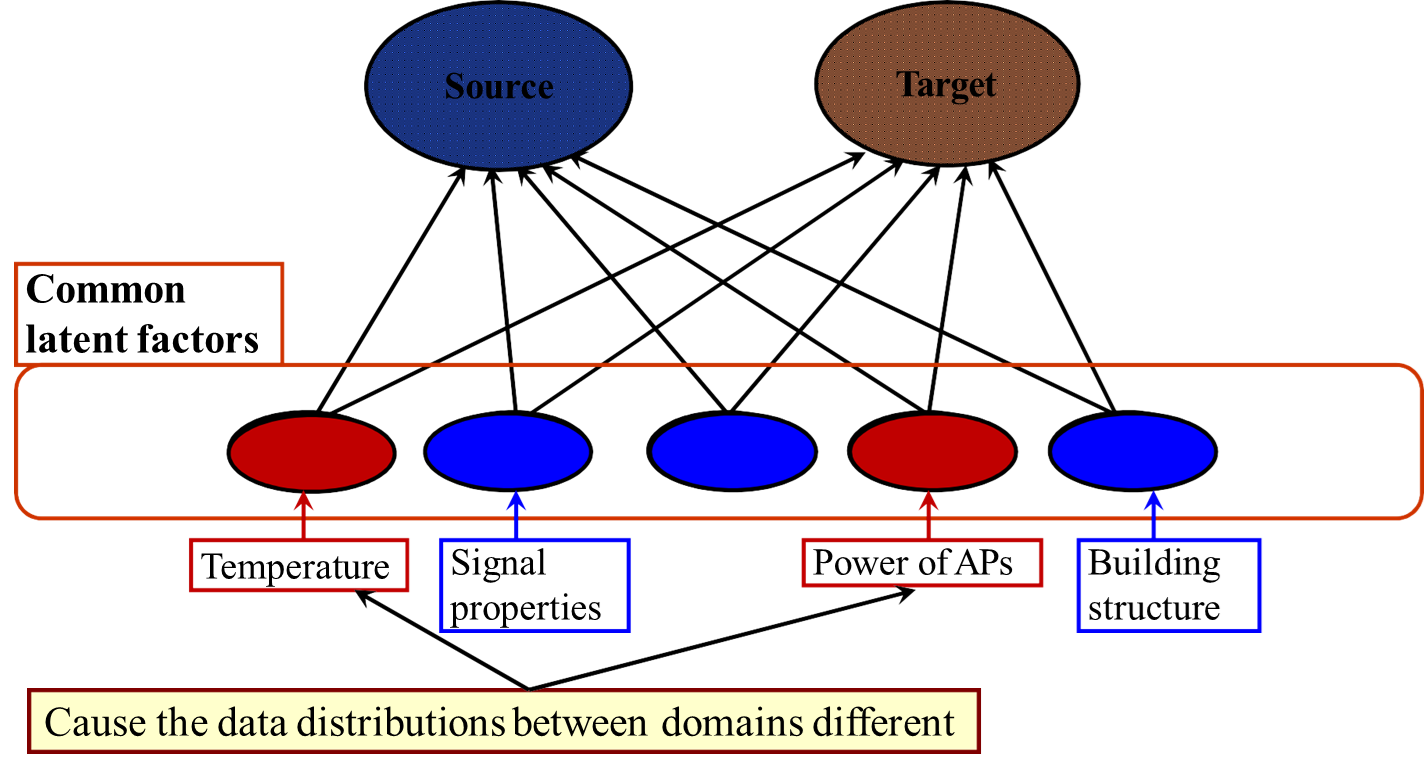
因为在同一个建筑物中, 源域和目标域共享许多特征.
两个不同的时间段可以分别作为源域目标域
两个不同的设备也可以分别作为源域目标域
隐空间中有一些特征, 可能同时与时间段与设备相关(红色特征, 导致两个域的数据分布不同); 另一些特征可能与时间独立, 或与设备独立(蓝色特征)

发现时间独立或设备独立的潜在特征, 用来表示源域与目标域数据, 可以减少源域与目标域的差异.
这些时间独立或设备独立的潜在特征中, 有一部分可能是主成分, 它们可以保留方差, 尽可能多地保留数据属性, 即信息;
另一些可能只是噪声成分, 它们无法保留重要属性, 如数据方差.
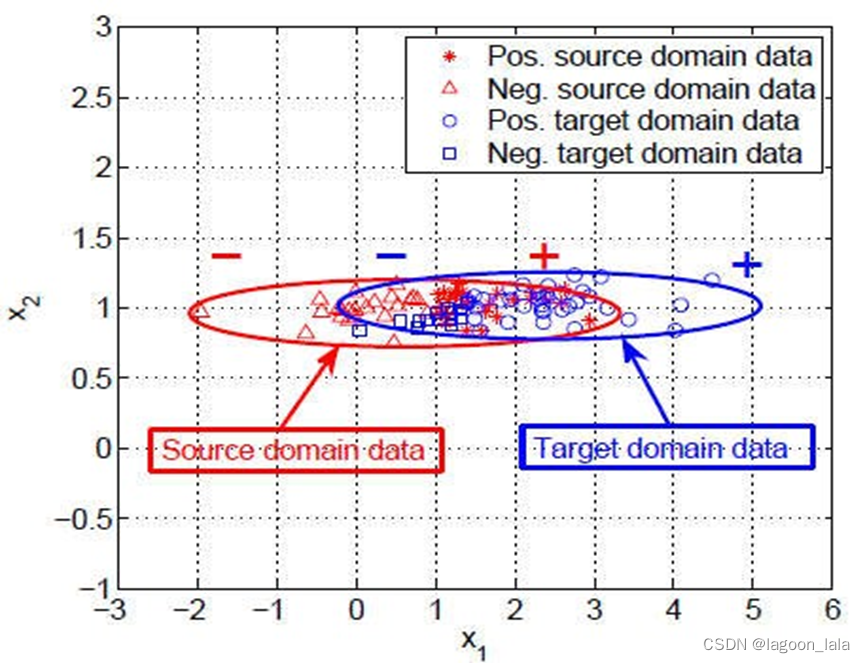
Learning 𝜑 by only minimizing distance between distributions may map the data onto noisy
所以仅最小化分布间距离可能将数据映射到噪声特征(noisy factors)上.
假设x2是一个噪声特征, 将二维数据映射到轴x2后, 源域和目标域的距离可以最小化, 但是无法捕获重要信息.
TCA的主要思想

学习一个映射φ, 映射源域和目标域的数据到隐空间, 隐空间包含的特征使得域间距离减小, 并保留了数据结构.

TCA的优化问题(Optimization problem)
最小化域间距离(优化目标的第一项, 这里用MMD表达分布距离)
优化目标的第二项, 即迁移的正则项(regularization term on this transformation)
约束条件-为下游(downstream)分类或回归问题保留重要特征, 数据方差, 防止映射到噪声特征
MMD如何计算隐空间中源域与目标域概率分布距离
概率分布核嵌入

Representing Probability Distributions in RKHS
分布距离的计算基于分布的核嵌入(kernel embedding of distribution), 它使用RKHS(再生核希尔伯特空间Reproducing Kernel Hilbert Space)代表概率分布(probability distribution)
对于给定的样本, 假设概率分布为X~P(x)
使用概率分布核嵌入的作用(high motivation):
对于每个域, 用特征向量表示这个概率分布, 就可以通过计算特征向量之间的距离, 来计算不同概率分布之间的距离.
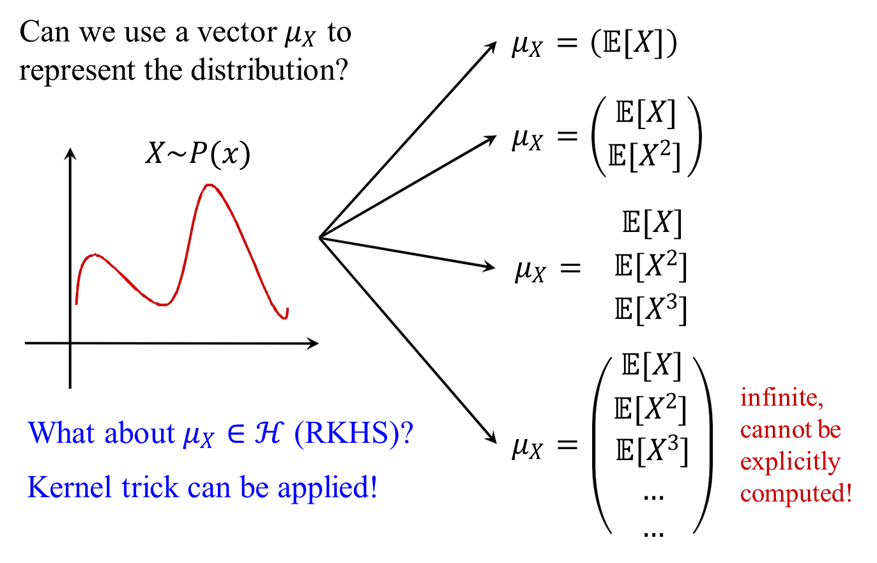
如何构造这个特征向量:
1.可以是一阶矩(the first order of moment), 即样本的平均值, 表示分布的期望
但不同的均值只能用来区分不同的均匀分布
2. 一阶矩+二阶矩共同构造一个二维的特征向量
但这只能用来区分高斯分布(Gaussian distribution), 不能区分更复杂的分布
3. 一阶矩+二阶矩+三阶矩…
4. 计算所有阶的矩来构造特征向量, 就可以区分任意复杂的分布. 但此时难以显示计算(be explicitly computed)
5.RKHS中表示特征向量, 可以使用核技巧计算无穷阶矩. 不知道特征向量的具体形式, 但可以使用核函数计算RKHS中表示的特征向量之间的内积.
如何使用RKHS表示概率分布
介绍概念Mean Map in RHKS

设X为一个样本, 服从未知的概率分布X~P(x), 记Φ(x)为到一个RKHS的特征映射. 将每个样本映射到再生核希尔伯特空间.
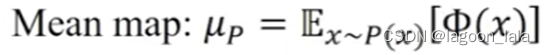
Mean Map定义为样本在RKHS映射的期望, 这个期望(此时每个样本的均值)也是一个RKHS中存在的点(向量), 记为μ_P

对每一个域的概率分布, 都对应RKHS中的一个μ_P
一一映射, 任意一个概率分布对应RKHS中一个的μ_P
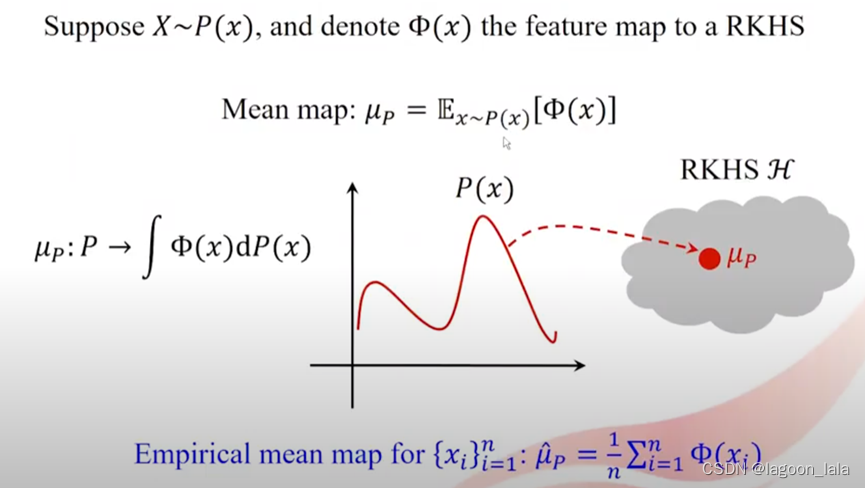
因为我们训练集样本点只是这个域样本的一部分, 无法精确计算出这个期望, 只能近似地用经验均值映射(empirical mean map)代替, 即数据点在RKHS中的均值

首先将每个原始样本点映射到RKHS空间, 再计算RKHS空间中每个样本点的均值得到μ_P, 这个μ_P就可以代表这些原始样本, 或者说代表它们的概率分布P(x)
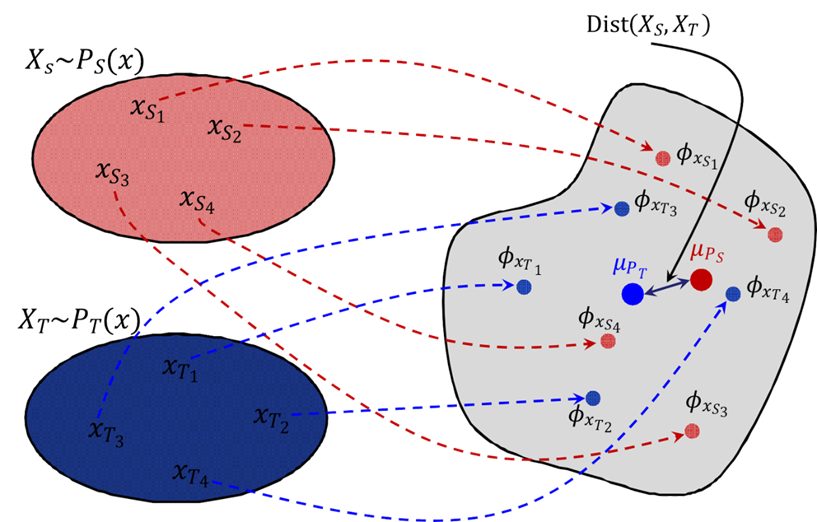
将源域和目标域映射到RKHS上, 分别得到两个empirical mean map: μ_{P_S}, μ_{P_S}
则μ_{P_S}, μ_{P_T}之间的距离可以代表源域和目标域的概率分布的距离
这个距离就称为最大均值差异(MMD,maximum mean discrepancy)
MMD可以用来度量两个分布的距离
TCA中用MMD代表两个域在隐空间的距离
在优化问题high level optimization problem中

目标是在映射后, 使隐空间中两个域的分布间距离最小化
这里说的就是, 要最小化距离, 就要知道如何计算这个距离
记φ为单个样本到隐空间的映射
希望得到的这个隐空间, 能够缩小源域和目标域的距离

为了计算这个距离MMD, 就需要把映射到隐空间的点再进行一次映射到同一个RKHS, 两个域分别计算empirical mean
现在的问题是, 我们如何选择核函数, 实际情况中最常用RBF. 但考虑到不同情况, 还是需要使用试错法 (follow the error and trial method), 基于下游分类表现决定.

基于分布的核嵌入法
定义一个复合函数(composite function) ψ
其中ϕ代表从隐空间到RKHS的映射; φ代表从原始样本到隐空间的映射
所以合成之后的复合函数就代表从原始样本到RKHS的映射
与这个特征映射相关的核, 为两个样本映射ψ的内积(这里原幻灯片有笔误, 后一个ψ的输入是x_j)
根据核技巧, 这两个ψ的内积与核函数的值相同.

所以源域与目标域在隐空间的距离可以重写为这个核矩阵K乘以L矩阵的迹tr
其中K为核矩阵, L为一个指示矩阵

(此处作者没有多加推导)

对于总的优化问题, 优化目标的第一项可以重写为MMD的tr(KL)
问题转换

由此产生的优化问题很难解决, 因为其中有一个复合函数ψ
在这个复合函数中, 我们的目标是学习从原始样本到隐空间的转换φ
而从隐空间到RKHS的Φ是隐式的, 并且高度非线性, 但因为使用核技巧, 这个Φ不用求出来
此时ψ可以认为是一个φ的高度非线性函数.

我们想要直接优化ψ, 根据优化ψ的结果直接生成特定形式的φ
但是因为Φ是隐式的, 所以ψ也是隐式的, 并且可以是无限维的, 所以依然难以直接计算

但因为核函数的输出=ψ的内积, 可以通过计算核矩阵K, 重建每个样本的低维表示, 来近似φ
这里的MMD可以换成其它的度量方法, 但MMD是最早提出的可以用来度量分布之间距离的迁移学习方法.
如何学习核矩阵
解法1

我们首先将学习变换φ的问题转为学习核矩阵K的问题
然后将学到的K用来转换源域与目标域的样本

此处, 隐空间中源域与目标域的距离用tr(KL)来表示

优化目标是最小化tr(KL), 求的是K(K为半正定矩阵)
为了保留原始数据的一些属性, 最大化隐空间方差tr(K), 即最小化-tr(K)
约束是为了保留原来的几何结构, 确保学到一个解

在学到K之后, 基于K进行PCA变换
这是一种核化的PCA方法(kernelize PCA approach), 不过其中的核由这个优化问题得出
通过PCA, 可以构建源域与目标域的低维表示
通过这两步, 可以近似得到数据到隐空间的映射φ

但现在依然存在一些限制:
1.这个优化问题是半正定规划(semi-definite programming)的优化问题, 开销非常大
2.因为我们通过解这个优化问题学习核矩阵K, 再基于K进行PCA变换. 整个过程是直推式的(transductive), 难以泛化.
这就代表, 当出现新的(训练集中不存在的)目标域的样本点时, 需要通过这个优化问题重新构建K矩阵. 然后再通过PCA变换.
3.因为PCA的过程再学习核矩阵之后, 这有可能忽略潜在的有用信息
第二种解法

解TCA时不解K, 而使用经验核映射再组成K
K bar是已知的, 给定的核矩阵
我们显式(explicitly)地定义一个核函数去计算核矩阵K
其中W是一个未知的低秩矩阵, 是我们将求的.
n_S是源域样本的总数, n_T是目标域样本的总数
因为m远小于n_S+n_T, 所以W是一个低秩矩阵
经过核分解后, 不再学习整个K矩阵
这里只需要学习低秩的W

将学习核矩阵K的问题转化为学习低秩矩阵W的问题
第一项还是最小化两个域的距离, 第二项是低秩矩阵W的正则项, 约束最大化数据方差
(优化目标的第二项可以认为, 因为K bar是给定的, 所以只用考虑W, 不过这里负号变成了正号. 但是这里说法不同了, 之前说第二项是最大化方差, 约束是保留数据几何性质. 可能是因为现在解法不同, 不再需要PCA, 而PCA的作用就是最大化方差)
解决这个问题, 需要解决一个广义特征分解的问题, 这比SDP快得多
TCA思想用于DNN
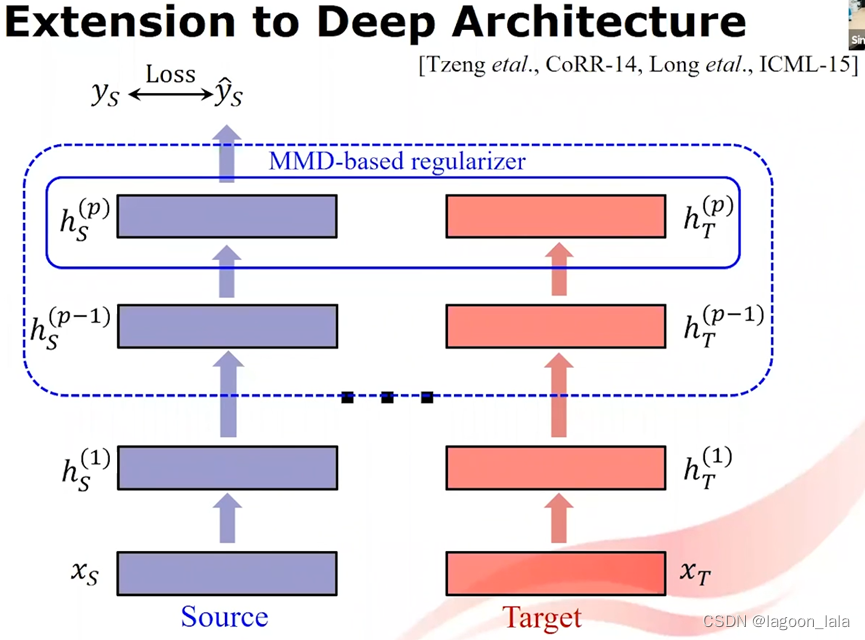
Extension to Deep Architecture
这种想法应用在深度学习模型中, 映射φ被替换为深度神经网络(DNN)
一个DNN用于源域, 一个DNN用于目标域
对于两个模型其中的对应的一层或多层, 添加MMD正则项, 使之距离最小化
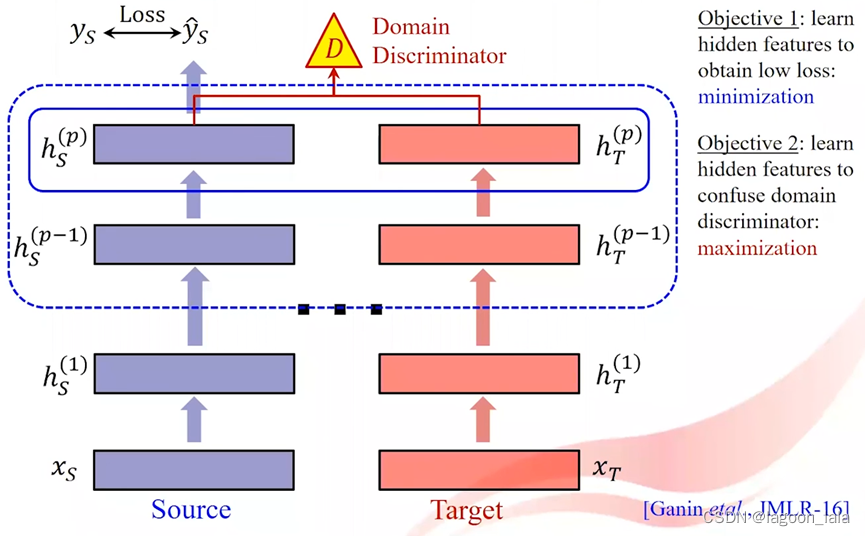
Domain Adversarial Training
如果不使用MMD作为衡量标准, 也可以使用领域对抗训练, 来学习一些不依赖领域的泛化性强的特征
对于两个模型其中的对应的一层或多层, 引入领域判别器(Domain discriminator)
领域判别器(Domain discriminator)也就是一个分类器, 对于得到的特征向量, 判断特征来自源域还是目标域
在最后输出时同时引入标签上的损失函数
所以领域对抗训练有两个目标:
1.学习隐藏层特征使预测任务的loss最小化
2.学习隐藏层特征最大化领域判别器的loss
此处不是显式地最小化领域间距离, 而是引入一个领域判别器

基于特征的迁移方法的第二种, 学习通用特征, 它最早在self-taught learning中被提出

使用self-taught的动机:
1.存在一些特征可以帮助目标学习任务, 即便只有很少的标签数据
2.可以从辅助的任务和域中学习一些特征

self-taught的一般步骤
1.从大量无标签数据中学习
2.使用学到的特征表示目标任务的数据
略过, 定位1:40
基于参数
基于关系


定位1:50















 1297
1297











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









